
Hey there! I’m Tyler "Riot Adabard" Turk, Senior Infrastructure Engineer, and I work on the Player Accounts team at Riot. The Player Accounts team is responsible for every player's ability to log in and manage account data, and we recently re-architected our system to become GDPR compliant, provide a better player experience, and enable Riot to become a multi-product company in the future.

Taking the League of Legends game server from a nondeterministic process to its current state required almost a full year of effort from multiple engineers. As a side benefit of this effort, we holistically improved the codebase’s robustness, discoverability, and maintainability. We removed swaths of dead or redundant code and created new opportunity spaces for gameplay exploration.

Imagine you're a web developer. You have to create an app that leverages five different data sources. The project has 26 different views built in - and don’t forget to make it fast, easy to test, and reliable. I work on creating the tools that make this kind of app as easy as possible for developers to build and manage. My name is Matthew Drake and I’m a member of the Riot Data team.
The Riot internship program helps technical players drive their professional growth by embedding them on tech teams and having them contribute to impactful, exciting technology projects. Last year we published an article by some of our interns, giving readers a glimpse at the projects technical interns get to work on. We’re doing a follow-up this year, but with additional sections to reflect our new games.
There were so many interns excited to contribute to this article that this year we’ll be doing a 2-part series. Intern stories are sorted into categories - the first post (this one) includes all blurbs for League of Legends, TFT, & VALORANT, and the second post focuses on General Game Tech & Tooling/Infrastructure.

Hi, I’m Tony Albrecht, an engineer on League. You might remember me from such articles as Profiling: Measurement and Analysis and Profiling: Optimisation where we looked at how we find and optimise performance bottlenecks in the LoL code base. In this article, we’re going to take a step back and look at how we detect and then fix real world performance issues that slip out past our QA and monitoring systems and escape into the wild to plague you, The Player.

Game developers working on a continuously evolving product like League of Legends are constantly battling against the forces of entropy as they add more and more content into unfortunately finite machines. New content carries implicit cost—not just implementation cost but also memory and performance cost created by more textures, simulation, and processing. If we ignore (or miscalculate) that cost then performance degrades and League becomes less enjoyable. Hitches suck. Lag is infuriating. Frame rate drop is frustrating.

This article is the third in a multi-part series on the Riot Games API. As discussed in our second article, the API is fronted by the Zuul proxy server developed by Netflix. We chose Zuul because Netflix built it to handle an enormous amount of daily traffic, so we knew we could trust that the code was battle-tested and production-hardened.
I’m Byron Dover, engineering manager for information technology at Riot, and I lead the team responsible for developing enterprise software at Riot - or as we sometimes call it, Riot’s Operating System. I’m excited to share a look at how Riot integrates with Slack to support the game development lifecycle.

Hi, I’m Paul Geerts and I’m one of the engineers on League’s Render Strike Team. A while back my buddy Tony posted an article about how League of Legends currently builds a single frame of the action. Today, I’d like to dive into a component of the rendering pipeline that we’re actively improving: materials. I’ll discuss some of the changes we’ve made and why they’re important for players and developers alike.
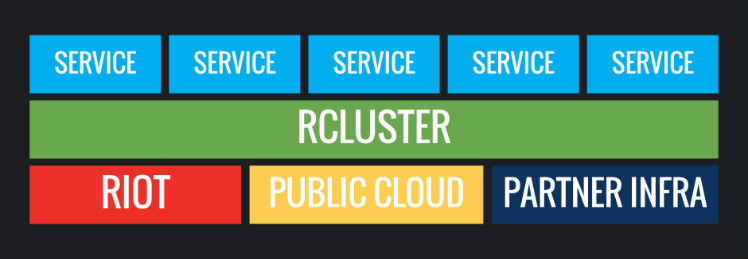
Our names are Kyle Allan and Carl Quinn, and we work on the infrastructure team here at Riot. Welcome to the second blog post in our multi-part series describing in detail how we deploy and operate backend features around the globe. In this post, we are going to dive into the first core component of the deployment ecosystem: container scheduling.
