
Globalizing Player Accounts
Hey there! I’m Tyler "Riot Adabard" Turk, Senior Infrastructure Engineer, and I work on the Player Accounts team at Riot. The Player Accounts team is responsible for every player's ability to log in and manage account data, and we recently re-architected our system to become GDPR compliant, provide a better player experience, and enable Riot to become a multi-product company in the future.
I also recently talked about the system in great detail at re:Invent. Check out the video below for all the deep tech details or read on for a high level overview of our accounts system and our shiny new backend database. This article will provide some historical context on the authentication and authorization platform and then dive into the database layer we're using for player accounts. In the future, we hope to cover Atlas (the replacement of the Global Account Service) and provide deeper dives on building global services with a focus on functional, load, and chaos testing.

Setting the Stage
We deploy League of Legends to 12 disparate game shards in Riot-operated regions, and many more in China and southeast Asia via our publishing partners Tencent and Garena. With 10 clustered databases storing hundreds of millions of player account records, hundreds of thousands of valid logins and failed authentication requests, and over a million account lookups per minute, we have our work cut out for us.
History Lesson
Accounts are the backbone of the player experience in League. Without accounts, players wouldn’t be able to track their progress, stockpile achievements, or use the cosmetic content they’ve unlocked. Without accounts, players would have no identity in the game.
As League of Legends grew, so did its supporting systems. Riot expanded into new regions using a “shard” strategy, with individual shards containing a complete League of Legends platform and all the systems needed for players to play our game. The accounts system was one such foundational system included in every shard.
The advantages of this shard growth model are pretty easy to describe: Each shard is an isolated unit, geographically co-located and contained. Systems that are constrained to a single local datacenter are simpler than systems distributed across multiple datacenters - they’re easier to design, build, and operate.
The model worked well for Riot, League of Legends, and most importantly, players. Teams were able to focus on feature development and scaling, and growth was relatively predictable and manageable (though not a simple problem to solve).
While the shard model was successful, we realized early on that there were some serious limitations. The shard model, designed with the needs of League of Legends players in mind, restricted how players could interact, socialize and engage in future games.
Some folks in our community like to joke about Riot being a small indie company, and at one point, we very much were. Our growth was rapid, and as we scaled and adapted over the years, we built and deployed several competing authentication and authorization implementations running in parallel. Here’s a snapshot of what our accounts infrastructure (dubbed RiotSignOn or “RSO”) looked like in early 2018. We’ve zoomed in on two AWS regions out of the four we’re deployed into:
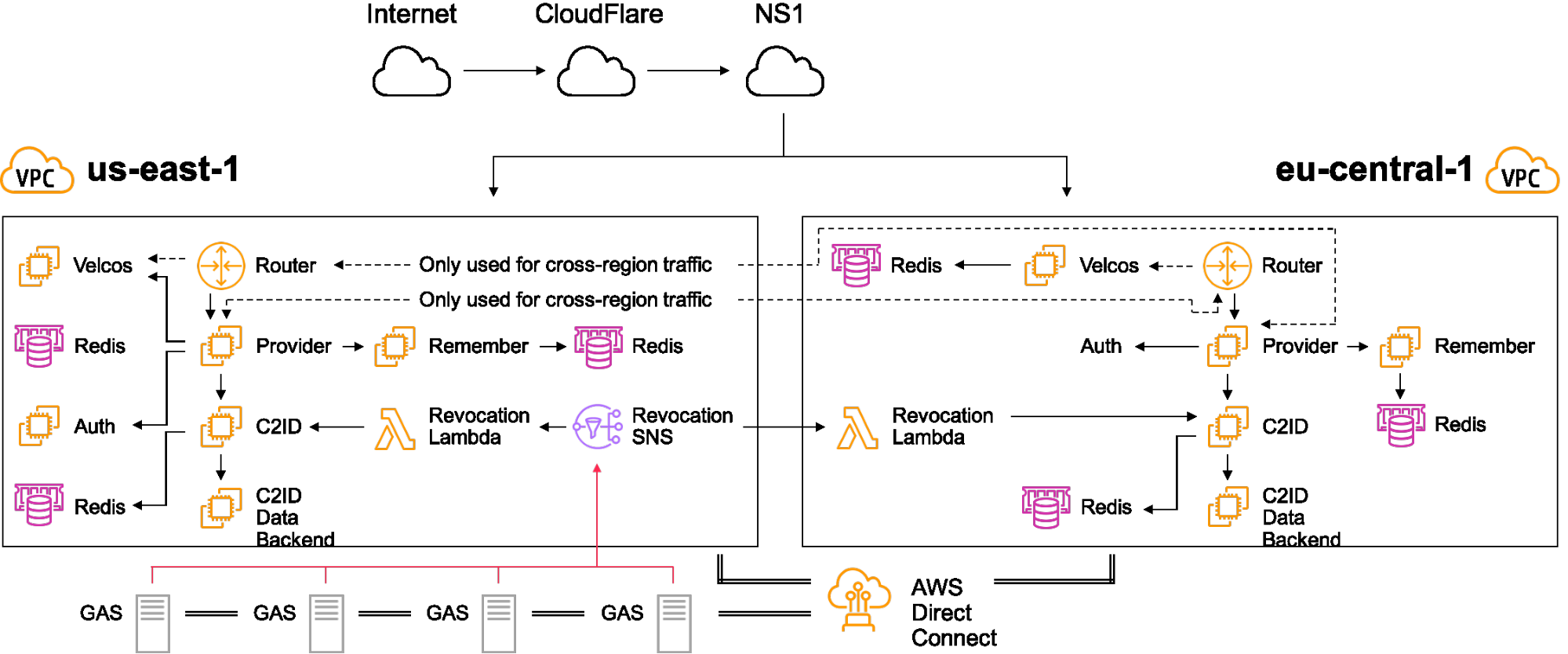
Diagram Quick Overview
Internet - This is where our players live
CloudFlare - DDoS mitigation provider
NS1 - Geographical routing via DNS for global service distribution
Router - Front-end proxy to route authentication requests to destination cluster
Velcos - Rate-limiting service to mitigate traffic bursts, backed by redis
Provider - Primary business logic focused application that handles authentication
Remember - Handles session remembrance for staying logged in, backed by redis
Auth - Authentication proxy that distributed requests to the appropriate GAS server
C2ID - Connect2id is a commercial product for handling OpenID Connect logic
DirectConnect - AWS service for linking AWS and external networks
GAS "Global Account Service" - backend source of truth for regional player account records, backed by MySQL and colocated with each League of Legends shard
Setting Context
We’ve aligned on the use of OpenID Connect as the standard for handling authentication and authorization. If you’re not familiar with OpenID Connect, it’s an identity layer built on top of the oAuth 2 protocol.
We’d already done some significant refactoring work to standardize authentication. Today, if you log in to any Riot Games service, be it League of Legends, our forums, or our merch store, you’re using RiotSignOn for authentication and authorization.
The account data provided to each service is controlled via scopes that limit what data is available for read and write for that login session and service, and this helps to ensure our player accounts are more secure than they were with the bespoke services that had existed before. We have RiotSignOn deployed into four AWS regions with a front-end router that provided us with a federated authentication model. A login session would be pinned to an AWS region upon instantiation by appending metadata to a part of the authorization response, and any request to refresh or validate this session would be routed back to the origin cluster if it was online. While all of the account lookups and authentications would be performed through RiotSignOn as the front-end, the accounts were still stored in the disparate game shard databases. You can see in the diagram above that DirectConnect was heavily leveraged to tie into our physical datacenters where the GAS service was located as well as other AWS regions.
The system worked, but it had some built in limitations that we knew would come back to haunt us in the future:
-
Even though we called the backend authentication system the Global Account Service (GAS), it wasn’t truly global.
-
Our original design was rigid; some of our expectations for what data was present and how it should be presented no longer made sense.
-
Our authentication and authorization systems required large changes to meet new challenges, but we couldn’t change it all at once. Small, incremental change over time was needed. We needed to both rebuild the plane while in flight and keep it flying.
-
We had no way of integrating with third parties who wanted to work with us, and this became painful as new platforms and services requiring scoped access to player data came online.
-
We needed the ability to federate our authentication and authorization with community tools to provide more value.
-
Maintenance in one region could result in service interruptions for global services.
-
It wasn't GDPR compliant.
In short, we knew that alignment around a well-adopted standard would help to drive significant change of the accounts platform and greatly increase our security. With our requirements and limitations in mind, we set out to build our new system. The next section will cover the back-end database technology we've implemented to handle globalizing our player accounts infrastructure.
Database Layer
We use MySQL as the database backend for our accounts platform instead of other options such as Cassandra, Riak, Postgres for a few reasons. MySQL is widely adopted at Riot and our parent company Tencent, which means we have a lot of engineers with a good understanding of how it works. For us to provide the best player experience globally, this kind of consistency is crucial. We put a high priority on having full ACID compliance - atomic operations, guaranteed consistency, isolation, and durability of our queries. Given the nature of the data we’re storing, this helped provide us with confidence that our players’ accounts are safe.
Clustering Technology
We chose to use a product called Continuent Tungsten Clustering suite which consists of a number of processes that live alongside MySQL that wrap around and manage the cluster. From the perspective of MySQL, there is no clustering or replication configured. Since MySQL is not clustered nor configured for replication, the servers do not need to be aware that there are other servers with the same data.. There are three primary components of the Continuent Clustering suite: the replicator, the manager, and the connector.
The replicator reads MySQL binary logs on the primary server and converts them to a transaction history log, shortened to THL, which is a sequential list of events. It then serves the THL-based events to the other nodes in the cluster. These events are immutable and are written to disk without buffering in order to prevent software failure causing a problem. When receiving events from another database server, the replicator will add them to a queue, write the THL to disk, and then apply the transaction to the database to mitigate server failure causing partial writes. This replication is performed asynchronously.
The manager is a cluster orchestrator service that keeps tabs on the current state of the cluster and handles membership as well as quorum. The manager service includes an API that provides JSON outputs of the current view of the cluster from the perspective of itself and can be used for monitoring and reporting.
The connector is a MySQL proxy that talks to the manager service to identify which of the database servers function as a primary and which servers function as secondaries. Our implementation uses read and write splitting based on connected port (3306 for writes and 3307 for reads) but Continuent also offers a connector mode that will introspect MySQL queries and do intelligent routing based on query type.
Our Implementation
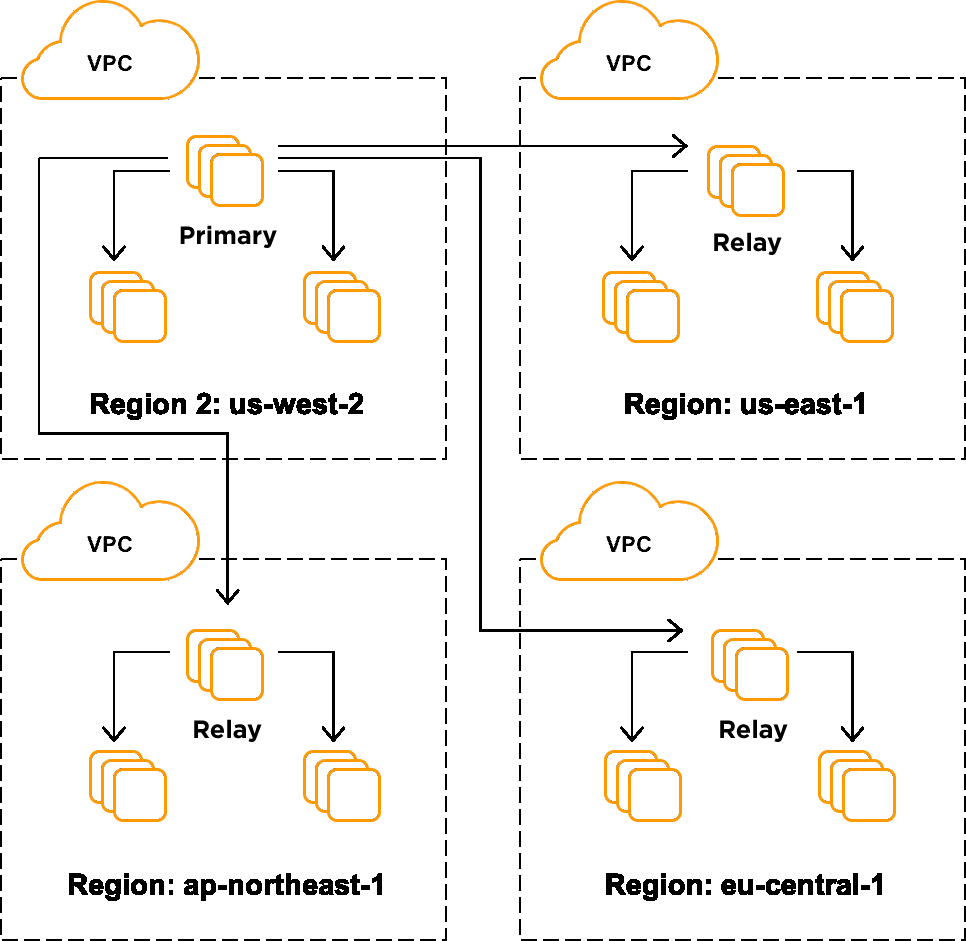
We deployed a multi-region composite cluster with the intended primary residing in us-west-2. As you can see in the image above, there are three nodes per region with a primary or relay and two secondaries. A relay functions as a local read-only primary that replicates off of the current global primary node. The secondaries local to each relay replicate off of their local relay node. The connector is configured to send read requests to the most up-to-date node in the same AWS region, but if there is a local outage, requests will be proxied off to the other regions. This global cluster has a single write primary, and each of our backend services that do writes to the database connect to the appropriate primary over the DirectConnect backend by leveraging a connector.
These database instances are deployed using Terraform and allocated static IP addresses when provisioned. The services are all containerized and launched via docker-compose, which is written through userdata startup scripts. All general maintenance, restarts, and upgrades are managed by Ansible. We also wrote a helper osascript to automate creating an active SSH session to each server in an environment and entering the Docker container as the appropriate user. This enables rapid iteration and triage if we need to investigate any local logs/service health. While these servers are treated much more like pets than cattle, we have a good amount of fault tolerance and automation for server instability and service recovery. They still require a bit of tender loving care, but they will self-heal and attempt remediation steps when necessary. Each of these database servers are deployed as r4.8xlarge with a 5TB encrypted EBS volume for data and 15TB encrypted EBS volume for logs and backups. We chose these instance types and disk sizes for performance reasons, primarily the guaranteed 10 gigabit network performance and write IOPS for the SSD EBS disks.
Managing the Database Schema
The database schema for the legacy service Atlas was replacing was designed to have a sharded access model. All of the accounts that existed in the local database were expected to be for a region or small subset of regions. The new schema would require the PUUID as well as additional identifier information to allow the table to be unique. A fairly significant mistake in our approach was to have an auto-increment ID field called primary ID as part of the migration, and a legacy ID field that was called ID and was only unique when combined with the shard ID. This resulted in a frantic attempt at recovery when doing our first pass of the right to be forgotten requirement of the GDPR laws. One of our engineers had his query proofread by several folks, including myself, who had forgotten we had chosen to do such a silly thing as having multiple fields called ID, at which point we debated adding a primarier ID and potentially primariest. As noted in this slide, our current schema is not final, and we should be transitioning to a final schema Soon™ which will clean up most of the legacy data types we had to keep intact for the initial migration.
We have the capability of doing live schema updates, as long as they’re backwards compatible, by removing a database from the cluster, performing the schema change, and bringing it back into the cluster. Once all nodes have been completed, we’re able to perform a cluster switch which will promote a new primary, and the schema change can then be applied to the former primary node. This ensures the change is never executed on a primary, thus bypassing the write to THL and avoiding the replication hit as well as performance hit due to isolated table locking.
Performing Database Backups
As part of our production rollout plan, we had made the decision to perform a daily backup in each region due to the amount of data. We wanted to avoid doing S3 replication after a backup completed, and manually copying the database over the network was also too slow. Our backups are triggered via automation that elect a backup node - any secondary node in the cluster intentionally skipping relay and primary nodes - and then executes the Continuent wrapper around xtrabackup. We chose this method to ensure an easy restore process by just invoking the restore command and referencing a backup performed through their tooling. This backup performs xtrabackup, copying the files from the data EBS volume to the logs and backup EBS volume, compressing it using pigz, the parallel gzip, and finally uploading it to a local S3 bucket. The resource utilization pattern started with heavy network and disk i/o due to copying files from one EBS volume to another, then high CPU utilization to compress the backup, and finally high network i/o again as the backup was uploaded to S3. The EC2 instances we deployed the database on are beefy, and we had a good amount of CPU to spare, so we chose to use 8 threads for the parallel compression. Everything was great, and we went fully into production with each region performing their own local backup. The backup process was taking roughly 5-7 hours every day to complete, but it was working as intended, with compressed backups being stored in S3. We celebrated success and started to tackle other features.
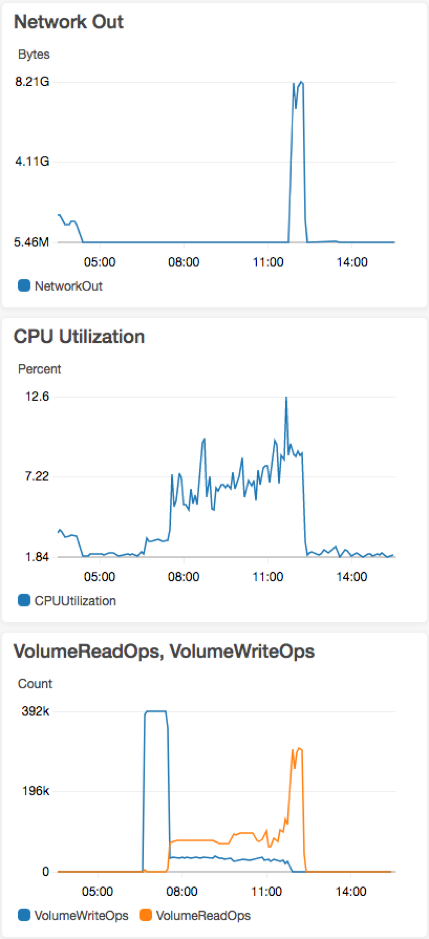
A couple of weeks after cutting over all of our production traffic, we started to see consistent full cluster outages occurring around the same time every day. The images above show slightly elevated CPU utilization and high load with consistent memory utilization. During the high CPU traffic here, there’s very low network utilization, but it spikes immediately after the elevated CPU ends. The bottom image demonstrates our monitoring showing a Continuent resource during a flapping outage where the service would report up and then cycle itself, causing it to go down. After having several triage and troubleshooting calls with Continuent, we discovered that the elevated CPU utilization, even though it capped at less than 50% of the cluster’s available CPU, was causing latency in the manager and resulted in the wrapper monitor service that checks the health of the manager via polling calls to think it was unhealthy and trigger a restart. This would result in other nodes attempting to check and validate quorum again, pinging for health, and entering similar scenarios. The rapid successive restarts of the manager resulted in cluster instability that would sometimes auto-recover and other times cause up to an hour-long outage of the database layer.
We were able to do some configuration changes to the manager to provide more resources and higher tolerance to processes competing for resources, reduce the number of cores used for the parallel compression, and focus backups to only 1 region, which receives the lowest amount of database traffic. These backups are still uploaded to S3 and are fully functional. The best part is that the backups don’t impact the cluster stability anymore. We intend to take this one step further and implement the cluster-secondary replicator offering from Continuent. This is effectively a node that dangles off of an existing cluster as a standalone node. This offering provides a nifty feature that we intend to use when we deploy it, which is effectively an intentional delay on replication. This enables us to have a full, near real-time copy of the MySQL data that is insulated from developer error. If an engineer, for instance, ran an operation to update player accounts and mark them as pending deletion (which renders them unusable) and accidentally used the wrong key, we would be able to relatively quickly revert the mistake. We wouldn’t have to cull through event audit logs and previous backups to verify which accounts needed to be returned to service. This is a standalone tungsten-replicator node that can be used for ETLs, backups, reporting, and general queries which are not part of the connector’s pool of hosts. This means any impact to the database is not seen by the production running service. The configuration is relatively straightforward, and it is non-impactful to add to an existing cluster post-deploy.
Lessons Learned
This is an overview of some of the lessons learned and ideas we followed throughout this project. If you're interested in more in-depth information, check out the re:Invent talk.
-
Ensure you have rock-solid monitoring
-
Consider and practice multiple migration methodologies to find what'll work for you
-
Evaluate if containers are right for your task
-
Document and draw your designs, and ensure detail is provided
-
Focus on iterative architecture, not ivory tower design principles
-
Think everything through, and when designing a VPC, plan your subnets
-
Consider your network access control implementation, what strengths and weaknesses are there, and what you have to do to provide only what's necessary
-
When load testing, evaluate your resource constraints and test with actual usage patterns
-
Avoid reinventing the wheel and use services when possible
-
WAN replication is very fragile and susceptible to error when hiccups occur
Thanks for reading! If you have any questions about this article or the re:Invent talk, feel free to post them in the comment section below.