
Controlled Chaos with Fault Injection Testing
Hi, I'm Doug Lardo, a solutions architect at Riot Games. You may remember me from previous blogs I co-wrote on our infrastructure. I roam between teams and help them prepare for production. In this article, I'll talk about how we used Fault Injection Testing (FIT) to launch the Riot API inside of rCluster.
This isn't going to be a tutorial as plenty of those exist already. Our journey with FIT is still ongoing, but I want to show the world how we use FIT, and specifically demonstrate that it works and that we find it extremely valuable. We began using FIT to fix a specific problem, but now we’re using it to predict the future. This is our story, and I hope it inspires some of you to start your own FIT journey.
In this article, I'm going to introduce the concept of Fault Injection Testing, and talk about the Riot Games API and how they implemented it. Then I’ll discuss our testing methods, what we found, and soap box a little bit about high availability design along the way.
Context and Background
What is Fault Injection Testing?
Fault Injection Testing, or Chaos Engineering, is breaking things on purpose to build more reliable systems. It's finding problems before they find you. Instead of failures in the middle of the night, we create artificial failures on our schedule. I like to think of FIT as speeding up the clock - we can use it to simulate 10 years worth of naturally occurring failures in just a few hours in the lab.
We prefer to call it “Fault Injection Testing” instead of “Chaos Engineering” because although it's the same idea, when people hear the word chaos, they think evil. They think chaos is an uncontrollable monster you let loose inside your data center. That simply isn't true; in fact it's quite the opposite, as this solution introduces an unprecedented state of stability and reliability. We want people to feel safe when we introduce this idea. The name “Fault Injection Testing” implies control, not monstrous chaos.
Learning Point: Fault Injection Testing is a scientific approach to solving problems.
Our Failure Framework: Mundo Make Fail
# Grab the list of running packs
potential_targets = clusterctl.get_instance_ids(pack)
# Kill some of those PIDs
terminate_pids(ssh_username, ssh_key_path, potential_targets, delta)
# Wait for impact
logger.info(f"[{friendly_name}] Waiting for pack to adjust to Chaos.")
wait_until_change(rcluster, pack, admiral_tlspass, delta, timeout)
# Happy dance
logger.info(f"[{friendly_name}] Pack {pack} impacted successfully.")Sample FIT Test code
Our fault injection framework is called Mundo Make Fail (MMF). It's written in python3, and runs as a CLI tool. It started off as a single file and has grown organically over the years. Over time, we broke code out into reusable functions, multiple files, and classes. Now engineers can run basic tests - such as killing a random instance from the CLI - without writing any code. Keep in mind that tests like "kill the backup matchmaking server" need more logic to understand what the backup is. As we add support for more applications, it‘ll be easier for new products to FIT test in the future.
MMF also runs in a service mode. We define the tests using a cron library in a config file tracked in GitHub. At the top of every minute, we check for scheduled tests, and when it’s time to run the test, we spin up a future for it. Parallel-SSH remotes in and does the dirty work, and after the tests complete, we can send feedback via Slack or any HTTP endpoint the developer wishes. We also wrote user documentation with interactive Jupyter notebooks.
test_template = {
"create_timestamp": settings.get_timestamp(),
"delta": 1,
"description": "Test template description. Runs every 1m.",
"expect_pack_nochange": False,
"friendly_name": name_generator.get_friendly_name(),
"modified_timestamp": settings.get_timestamp(),
"pack": pack_name,
"rcluster": "globalriot.las2.rcluster1",
"regex": "string",
"ssh_key_path": "test_template/path/to/compute_node/id_rsa",
"ssh_username": random_name,
"status": "not started",
"test_id": test_id,
"test_type": "kill_process",
"timeout": 120,
"cron": "* * * * * Test template defined. Runs every minute",
}Test Template
The Riot Games API
The first major project we used fault injection with was the Riot Games API. To understand our API fault injection story, it's important to know what the Riot API is and how it works.
External developers use The Riot Games API to run sites backed by League of Legends data. These sites teach players ways to improve their game, organize tournaments, and much more. A key component of the Riot API architecture is the Edge Service Rate Limiter (ESRL). The rate limiter keeps track of how many calls a second a customer made. Because any one of our API servers could answer a request, no single server knows everything. You can only calculate the total number of calls a customer makes from a central point. Redis is that central source of truth for the rate limiter.
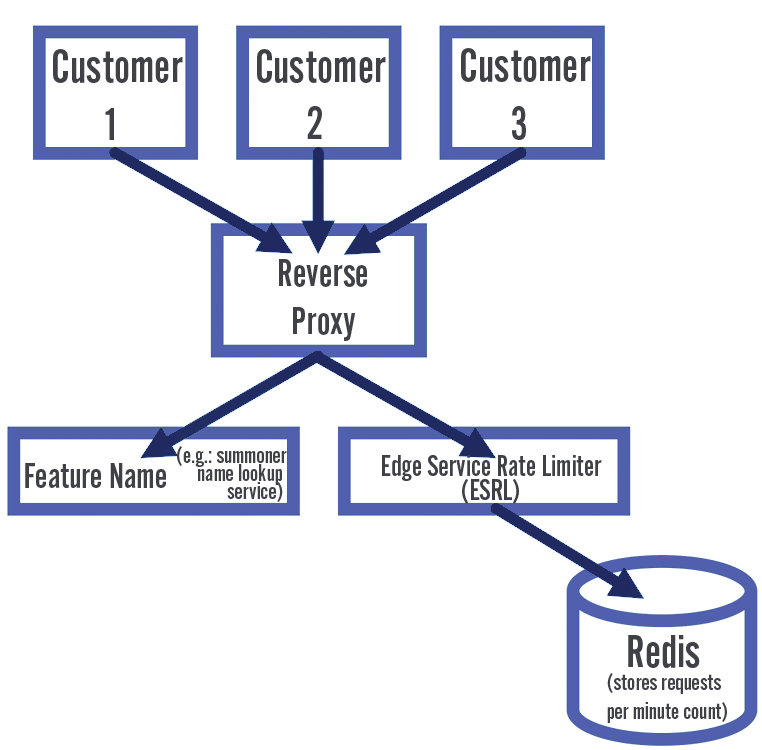
Riot API Simplified Architecture
Our Challenge: Redis on rCluster
When the time came to migrate the Riot API into rCluster (our container-based internal cloud environment) we ran into a problem. We’d been using Redis for a long time for the ESRL inside of AWS virtual machines. When we migrated from VMs to Docker, we needed to make a choice. We could either find a way to run Redis in the rClusters, or switch to a cloud-native solution. After weighing our options, we decided to put Redis in rCluster. "We can write a sidecar, it's easy." we said. Since I'm writing this article, you can guess how that turned out.
Our First Attempt
Putting Redis in the rCluster was like nailing Jello to a tree. We expected some issues because Redis was invented before Docker was. There was no way Redis could have been designed for it. Back when Redis was designed, assigning static IPs to servers was the standard way to do things. The memory of the box almost never changed, and reboots were rare. An admin would create a configuration file by hand and create the cluster once. Changes to the cluster after that were quite rare. In a cloud world, you get none of that. IPs are dynamic, reboots are a way of life, and the clusters have to build a topology themselves. We ended up writing over 3000 lines of code before we could get Redis into rCluster.
We like to think of ourselves as qualified for our jobs, so we tested our work. We rebooted instances and after some minor adjustments, everything felt solid. Secondaries took over when a primary died, new nodes spun up, the topology reported as healthy. What more could you ask for? The team all agreed, "let's turn it on!"

Yes, that's a full on dumpster fire.
Learning Point: Microservices, containers, and high availability are never simple.
Every Redis cluster we launched burned to the ground. Clusters were all in unrecoverable states. The API couldn't read or write data; we were without rate-limiting. Our Docker instances were running, but the Redis layer was in shambles. Instances were waiting to join a cluster but couldn't. Restarting the instances had no effect. We were shocked, confused, and a little (okay a lot) embarrassed. If the API wasn't in beta, we would’ve been in real trouble. How could we have messed this up? We tested it! We even used Golang!
Finding Problems with Fault Injection Testing
We were stumped. We knew the clusters were dying, and all we had to debug were some cryptic stack traces. To make matters worse, the traces didn't follow any discernible pattern. We were basically handed a copy of every Redis cluster failure and disconnect error in the book. We decided we had way too many variables at play at any given moment, and we needed a way to isolate them one at a time. The best approach we could think to use was Fault Injection Testing.
We ran to the lab and started killing instances. What did we miss? Everything seemed to check out. The cluster reported itself as healthy after each test.

Redis Topology
Next we spun up a copy of the API, pointed it at the cluster, and killed the instances again. At first everything looked normal, but every once in a while we would get an error. We would dig for a while and realize that we needed more logs, another graph, or another terminal open. Once we got that set up, the issues would disappear. After this happened a few times, we started to doubt ourselves. "Maybe we did something wrong? Maybe we failed things too quickly? Are we seeing things?"
Learning Point: Automate your fault injection tests.
Our minds aren't designed to do this type of testing. Mine isn't, for sure. The screens start to blur, I forget to add a timestamp in the CLI, I get side tracked into a debate over what Redis' startup logic is, my delusional coworker insists the boba truck is outside on a Tuesday (spoiler: it wasn't!). It's hard to stay on top of testing like this for days on end.
All that changes when you automate tests, because you run the exact same tests each time. All your logs get put in a nice pile with timestamps, even when you aren't paying attention. If our goal is to be scientific and to reduce as many variables as possible... we should get rid of the human variables. Tests in code improve over time, whereas tests in heads do the opposite.
What we found with FIT
Interesting Find #1 - redis://:0
The clusters were failing in random ways, and we didn't know where to start looking for the source of the problem. To break down the problem, we asked ourselves what we thought was most likely. At the top of our list was container restarts. The SEA regions were all built around the same time - could there be a setting we missed somewhere?
We thought more about it, and figured Redis should be able to recover from 30 restarts an hour without issue. So we either missed something in our testing, or production was notably different from development. We needed to test everything again.
We wrote a FIT test to help us speed things along. It would kill a random instance, do a read & write test, ask every Redis instance if it was healthy, and repeat. After 20 runs or so, we noticed something strange. The cluster nodes command started reporting instances with an IP address of 0. We saw errors in our logs when the ESRL was trying to connect to redis://:0. What was going on here? Did Redis start without an IP address? That shouldn't be possible. We needed to keep digging.
After investigating, we found out that redis://:0 was a downstream symptom of a bigger problem. When an instance dies in rCluster, we reclaim the IP address so we can use it again later. When a container dies, the replacement container may or may not get that same IP addresses. In our dev environment, instances are coming up and down all the time, so it's rare that you get the same IP twice. In our production environments, things are much quieter. We aren't iterating and testing new versions, so changes are far less frequent. The odds of getting the same IP back again in production are much higher.
When the fresh Redis instance booted up, the old instances tried to connect to it as if they were old friends. This caused a lot of confusion in our client driver, Reddison. It had never seen this situation before. The new instance had the same IP address as the old one, but it had a new UUID. It didn't know how to handle this case, so it errored out, and reported the neighbor as redis://:0.
10.45.251.63:6379> cluster nodes
c2b52d0b4ec079bc861eb4fa01e03fea64a84277 10.45.251.243:6379 slave 3258bcdf9162dc30b2111df1e1511a84d9e68e5c 0 1538600231061 93 connected
5c174bd519aaa4b952fbb8cb8f7d4e5d5464ce04 10.45.253.84:6379 slave bc1ec5c1c0690f519e2600d2e4b8f7409a85334d 0 1538600232061 15 connected
bc1ec5c1c0690f519e2600d2e4b8f7409a85334d 10.45.252.232:6379 master - 0 1538600230560 15 connected 5461-10921
3258bcdf9162dc30b2111df1e1511a84d9e68e5c 10.45.252.124:6379 master - 0 1538600232261 93 connected 0-5460
0504a7f8c49eef07cff7bb4b4f76acbb3a226440 10.45.251.63:6379 myself,slave dca877c7b346a2c35c1da9a6951703db3687a7cf 0 0 33 connected
dca877c7b346a2c35c1da9a6951703db3687a7cf 10.45.252.235:6379 master - 0 1538600230360 76 connected 10922-16383
56a9abb7144ab2571fad3fbee25e3916882630f2 :0 slave,fail?,noaddr 3520b6bcce62b62ef55ddf73b10d26bc57b0b632 1538599571743 1538599570342 72 disconnected
c021676ceaee20845e41348f9d8795aedc8752ab :0 slave,fail?,noaddr bc1ec5c1c0690f519e2600d2e4b8f7409a85334d 1538599573247 1538599570841 30 disconnected
47d4aa3cbb1f6207809915d95de964c1c3cb8352 10.45.254.87:6379 slave 3258bcdf9162dc30b2111df1e1511a84d9e68e5c 0 1538600230061 93 connected
3520b6bcce62b62ef55ddf73b10d26bc57b0b632 10.45.251.173:6379 master,fail? - 1538599576161 1538599575459 72 connected
683d7d6bd569d69753b8f4a65862edca15341651 10.45.251.107:6379 master,fail? - 1538599574754 1538599573850 60 connected
10.45.251.63:6379>Output from cluster nodes
At first this wasn't a problem because the new instance joined the cluster as a secondary. No clients attempted to connect to it, so there were no errors. It was something far worse - a ticking time bomb. It would only become a problem when the primary died and the broken secondary got promoted. When this happened it would look like we lost two nodes at once. This showed up by the Reddison driver trying to connect to redis://:0 and immediately panicking.
We worked with the Reddison owners to get a few related fixes in. They were very helpful and quick to respond, and we implemented the fix in release 3.7.2.
Interesting Find #2 - Elections are fragile
We had ironed out a few minor issues, but we suspected there were more out there somewhere, lurking, that we didn’t know how to find. We refer to these problems as unknown unknowns. What we did know for sure was that a full cluster delete & reset is a great way to fix a lot of issues in the middle of the night. We’d grab all the logs, restart the cluster, and try to figure it out in the morning.
We decided that this full cluster reset needed to be reliable and that we wouldn't launch without it. We wrote another FIT test to destroy and rebuild the cluster. To meet our quality bar, we iterated until we passed the test 100 times in a row without issue.
What we found was that every so often, the election process would hang and never complete. The problem was that all instances raced to write "I'm first!" (AKA its IP address) to a central server on startup. If your instance isn't first, join the cluster that came before you. This is a pretty common method for doing simple elections, so the logic was sound. What could be wrong?
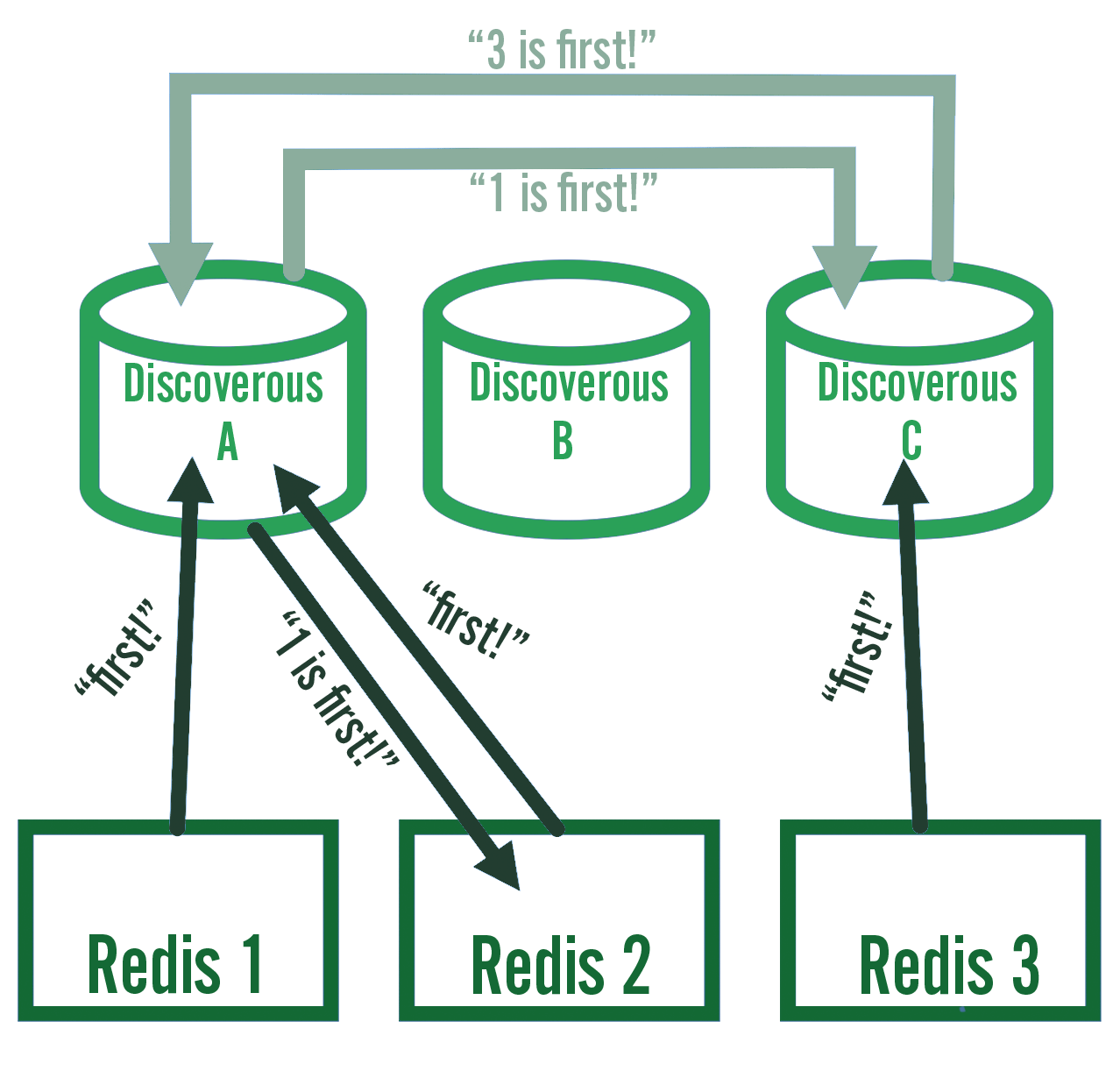
Our sidecar's election process
It turned out our central server wasn't actually central. We used our service discovery server, Discoverous, which we deployed in a load-balanced HA cluster with 3 nodes. When instances write "first!" to the cluster, there are good odds that they write to different nodes. Discoverous is eventually consistent, so this is great for service discovery, but bad for elections. Over time the cluster does agree on which instance won the election but it's impossible to tell when that happens. We had to rethink things.
One way to fix this problem is to have a strongly consistent, distributed locking service. Google's Chubby is a good example of that. We wouldn't have to change the election process because the central servers would do it for us. Unfortunately we didn't have one of those handy, and building one would take far too long. We needed a creative solution.
We solved it by using Discoverous in a new way. Discoverous contains a list of every running Redis instance, so if we fix the cluster size to always be 7, we can hold off on starting the election until everyone is present. Once we account for all 7 instances, we sort the list of IP addresses. Finally, we assign roles based on their location in the list. The lowest IP address would be the primary, the next lowest would be its backup, and so on. Not too shabby, right?
Additional Interesting Finds
Here are a few quick summaries of some other issues we found.
-
Most Redis clients ask a single node what the state of the cluster is. If that node is behind or out of sync, you get bad information. To know the true state of the cluster, you have to ask every node independently.
-
When you fill up a Redis master and it gets OOM killed by the kernel, the replicas get killed shortly thereafter. This happens because the replicas are filling up with memory at the same rate as the primary. This means you can have multiple failures within a few moments of each other.
-
A sidecar needs to track and restart its children PIDs. Docker only monitors PID 1. Killing the main Redis worker process with a kill -9 is a great test. It also raises some interesting questions. Is it better to failover to a new primary, or is it better to restart the existing one? The answer will depend on your environment.
Riot API Injects Faults to Production
When starting your fault injection journey, it's important to have an end goal in mind. It may make sense to timebox your tests so you leave yourself ample time to fix the issues you find. This is good for products and projects with fixed end dates. For us, we knew that what we really wanted was confidence in our systems, and we weren't going to launch until we were ready. We set the bar in two phases. First, pass a test 100 times in a row. Second, run tests in production.
Learning Point: Make it your goal to run FIT in production.
Making the jump to run in production was scary, but it was a leap we knew we had to make to successfully build confidence in our systems. We learned a lot during our internal testing, but you can never be sure of your work until you run it in production. We started off by running the tests during our normal working hours. We made fixes, and then we made some more. As we gained confidence, we started injecting faults 24/7. After a week of running the full battery of tests without issues, we turned it on in production.
As of today, we’re running 100 tests a day on production! That’s 7 live clusters, each running 16 tests a day.
"SG-Zuul": {
"rcluster": "globalgarena.sg1.rcluster1",
"cron": {
"test1": "30 2,14 * * *",
"test2": "30 5,17 * * *",
"test3": "30 8,20 * * *",
"test4": "30 11,23 * * *"
},
"pack": "globalgarena.sg1.riotapi_sg_zuul_redis.rapi.redis",
"yes": True,
"feedback_scope": "globalriot.pdx2.pdx2.rapi.healthchecker"
}Live Test Definition Example
Running every test in production isn't possible because we know some tests are going to cause an outage, such as with a full cluster stop and restart. However, we know we can survive losing a single instance at any time of the day. We decided to run destructive tests in QA, and the rest in production. If we had any doubt that our system couldn’t handle a hit to production, we would know that we had more work to do.
After going live, we didn't change the sidecar too much. Most of our changes involved telling interested parties when we ran the tests. We started by logging every test to a monitoring pipeline and a Slack channel. With 100 tests a day, nobody looked at it after a week, so we’ve since adapted it to only send Slack messages when a human is needed to investigate.
At the beginning, we tried to write the FIT tests to check the health of the cluster after each test. In hindsight, that wasn't the best idea. FIT tests shouldn’t be in the business of determining if there’s an impact or not. Instead, use the monitoring tools you already have.
Learning Point: FIT tests are pass / fail agnostic. Your app's monitoring system is the source of truth.
The validation you put in a FIT test is never going to be as good as a team's existing monitoring solutions. If your monitoring isn't setting off alarms when the tests run, it's either really good or really bad - the fault was injected without impact, or there was an impact and you have gaps in your monitoring. For example, we learned that we were unable to detect a degraded cluster. The only way we saw errors was when the primary and the secondary failed. To fix it, we added monitoring to directly check all the nodes. Now we fix degraded clusters in the morning, rather than fixing failed clusters in the middle of the night.
FIT in your environment
Every environment is different, but they all will fail if given enough time; it's inevitable. Every component in your system is unreliable if you zoom out enough.
Armed with this knowledge, your engineering mindset changes. You stop trying to build large reliable systems and start designing for failure. The challenge is a fun one; how will you design a reliable system if all you have is unreliable parts? How can I test this system by forcing the inevitable?
At first this feels like an impossible problem. If everything is going to fail, how can adding more fragile systems help? The answer is to expect that some failures will happen at any given moment. Many classic HA systems use a primary and a backup system. When the primary dies, the backup takes over. One limitation with systems like this is that the backup sits dormant for most of its life. Without testing it on a regular basis, we never know if the system will work when we need it. I can't tell you how many times I've heard "The backup worked when I installed it," in my career. A better architecture would have both systems active at the same time, both running at 50% load. In this setup, both systems are active, and we’re more confident that either can take over for the other if needed. We call these two patterns active/backup and active/active.
Another benefit of active/active is that you can extend it. An active/active system is not that different from an active/active/active/active/active one. In this setup, when a system fails, we only impact 1/5th of the traffic. The other servers will still have to take over for the missing node, but it's only an increase of 5% during a failure. The downside is that we need more sophisticated protocols to detect failures. Understanding those protocols is critical to being able to maintain the system. Reading the manual can help, but I've found you don't deeply understand them until you use them. It's common to know how clustering protocols work when standing up a cluster. The best way to learn the other features of the protocol is to break the cluster. Take the time to plan a failure scenario out, write down what you expect will happen, and then test it. Your knowledge and comfort will increase, and you’ll be more prepared for the unexpected in the future.
Learning Point: FIT lets you think through outages in advance.
As you’re leveling up your system, you will notice that your outages are more and more outside of your control. All your instances have a shared dependency at some point. For example, your instances might share a network, or a DNS server, or an OS, or they may all run on planet Earth. Somewhere along that journey, you’ll decide that taking the next step is too expensive. At this point, ask yourself: How do we respond to an outage at this level? Do we expose the failure to whoever depends on the service being up? Do we wake someone up? Do we send a shuttle to Mars?
Running FIT tests will let you find where these hidden failures are, and help you decide what to do in advance. I make the worst decisions when I'm scared, tired, or stressed. I avoid making decisions in those states as much as possible. FIT gives us the time and space to think slowly, deeply, and holistically. It lets us solve problems once.
Conclusion
It's been an exciting journey, both technically and culturally. When we first started, we used it to put out a fire. By the end, the team was using FIT proactively. It leveled up our confidence, our stability, and our monitoring and alerting systems. The repo for our Redis sidecar has doubled in size after all the Fault Injection Testing. It's at 6000 lines, and has 10 contributors from various teams. There’s a lot of operational wisdom baked into that code.
Other indirect benefits
-
The team has high confidence and pride in the system now. It's inspired other teams and games to also adopt FIT.
-
The Legends of Runeterra team used Fault Injection Testing before their first launch, which resulted in the smoothest launch day any of us have ever seen.
-
On-call engineers described the launch day as "boring." We love boring launch days! It means everyone that wants to play, can! Including us!
-
We added a login queue, a message bus (Kafka), and circuit breakers.
-
We put in fixes for our CNI, our load balancer configs, and our client side reconnect logic.
-
Every week we practiced responding to simulated outages. We called it "Failure Fridays."
-
-
The team started thinking about when something fails, instead of if something fails. This leads to better designs on new products and features.
-
Fault Injection Testing means more work at first, but results in less work later. We have a more stable velocity now as there are fewer surprises and less emergent work. The team is hitting their commitments at a higher quality and speed than teams that aren't doing FIT.
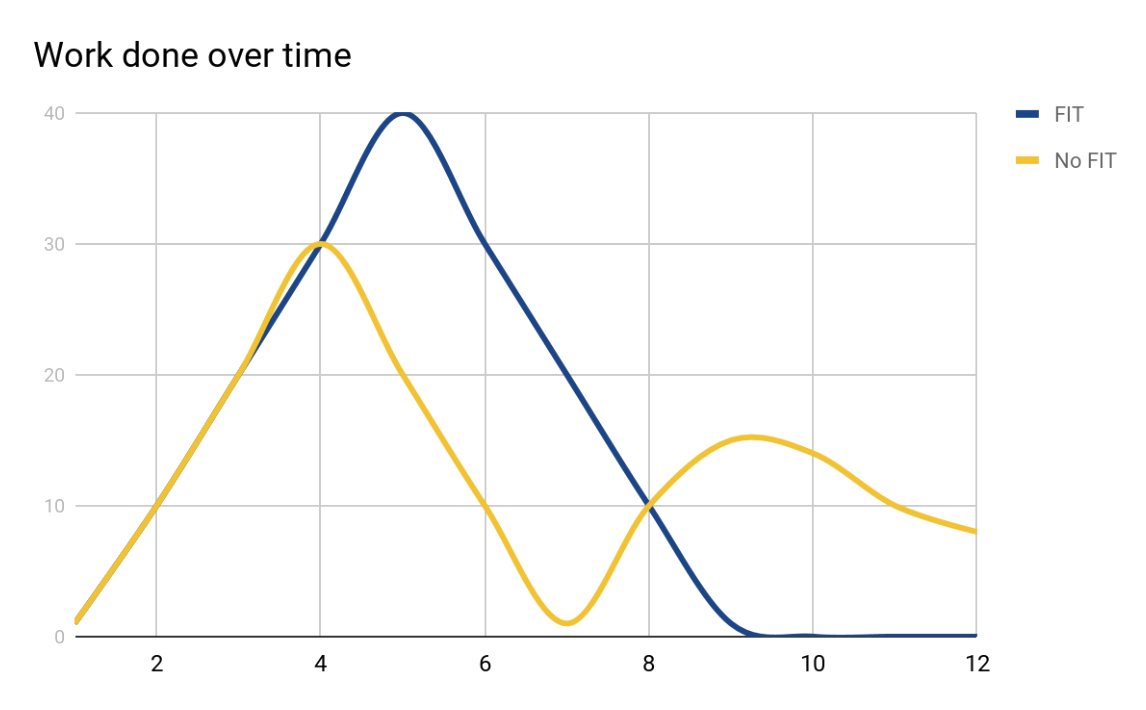
Fun side effects
-
Ironically, terminating systems gracefully is now the risky way to shut it down. We know kill -9 works.
-
The name FIT Testing is as annoying as ATM Machine, PIN Number and WINE Emulator. The problem is that trying to say "We are going to run another FIT now," sounds so much worse! Just go with it. Embrace the chaos.
Thanks for reading! I hope this inspires you to start on your own Fault Injection Journey (FIJ).
I’ll leave you with a brain teaser to get you in the FIT problem-solving mindset. There is a rare, but possible issue with our Redis cluster startup logic. Can you guess what it is? Leave your answers in the comments!