Running Online Services at Riot: Part III
Hey all, this is David Press and Doug Lardo, two engineers working on improving the data center networking that enables online services at Riot. This article is the third part in a series on exactly that topic, which begins with an overview from Jonathan of a platform we called rCluster. This time we’ll be discussing our approach to Software Defined Networking (SDN), how we integrate SDN with Docker, and the new infrastructure paradigms that this combination has unlocked for us. If you’re curious about how SDN can transform infrastructure, how to empower developers to obtain and secure networking resources via an API, or how to get out of purchasing larger and larger specialized networking appliances, this article is for you.
In the first article, Jonathan mentioned some of the networking challenges we faced when rolling out services to support new League of Legends features - turns out it’s not as easy as installing code on a server and pressing go.
New features need supporting functions from the network infrastructure, including:
-
Connectivity: low-latency and high-throughput access to players and internal services
-
Security: protection from unauthorized access and DoS attacks, and communication on an as-needed basis to minimize impact should a breach occur
-
Packet Services: load balancing, networking address translation (NAT), virtual private networks (VPN), connectivity, and multicast forwarding
Traditionally, setting up these network services has been the domain of hyper-specialized network engineers that log into individual network devices and input commands that I’m confident are, in fact, pure sorcery. Setup often requires a deep understanding of the network, relevant configurations, and responses when something goes wrong. Add in variability between data centers due to an evolving buildout process, and the situation gets even more complicated. The same task may look completely different for two network engineers in two different data centers.
All this means that data center network infrastructure changes have often been the bottleneck for rolling out new services. Fortunately, at Riot, whatever impedes delivering new awesome to players immediately receives serious attention. The rCluster platform aims to solve this bottleneck - in the sections below we’ll dive into the crucial components: the overlay network concept, our OpenContrail implementation, and our integration with Docker. In the next article in this series, we’ll cover some of the bells and whistles such as security, load balancing, and scaling the system.
SDN and Overlay Networks
SDN has turned into a bit of a buzzword that means different things to different people. For some, it means network configuration should be defined by software; however at Riot, it means that our networking features should be programmable via a consistent API.
By making our networks programmable, we can write automation that vastly expands our ability to rapidly deploy changes to our networks. Instead of shelling into numerous devices to make a change, we can run a single command. Our time to enact worldwide network changes goes from days to minutes. And then we get to go do other cool stuff with all our free minutes.
Network devices have been programmable for a while now; however, across the industry, the interfaces to program these devices are constantly changing and evolving, and no single standard exists that works with all vendors across every style of device. Writing robust automation that speaks every interface across multiple vendors is therefore a challenging task. We also know that having a consistent API as an abstraction layer above the hardware is a key requirement for Riot to effectively scale its network configuration management and operations. In our time of need, we turned to overlay networks.
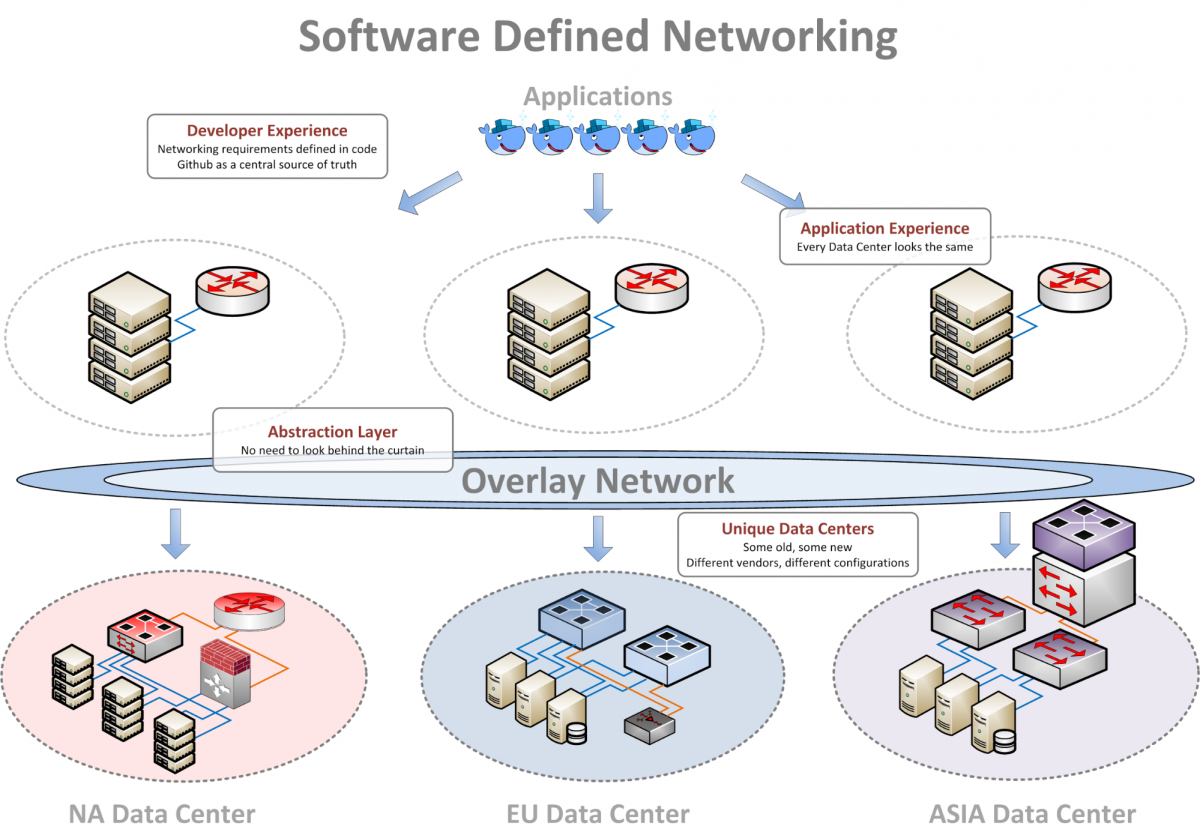
An overlay network, unsurprisingly, lives on top of an existing network. An application living inside an overlay network isn’t aware of the network's existence since it looks and feels exactly like a physical network would. If you’re familiar with virtual machines, the same "virtual inside of a physical" paradigm applies to virtual networks as well. One physical network can host many virtual networks. In a VM, applications think they own an entire physical machine, but in reality they only own a small, virtual slice of it. Overlay networks are a similar concept - one physical infrastructure (referred to as the underlay network) with virtual networks created inside.
This approach enables us to hide various details of the physical network that Riot engineers don’t need to worry about. Engineers no longer have to ask questions like “how many ports does this have”, “what vendor are we using,” or “where should the security policy live?” Instead, we can deliver a consistent API to program what the engineers do want to concern themselves with. Additionally, by having the same API available in every data center that Riot operates, we can write automation that works everywhere, every time, whether we’re using the first data centers we ever built or a much more modern design. In addition, we can look to other cloud providers such as Amazon, Rackspace, Google Compute, and so on, and our API will still work. The underlying physical hardware might be Cisco, Juniper, Arista, Dell, D-Link, whitebox, greybox, a bunch of Linux boxes with loads of 10G ports added - it really doesn’t matter. The underlay network must be built using specific methods, such as automated configuration templates (more on this in the next blog post), but this allows us to decouple the physical build and configuration from the configuration of services that applications require.
There are benefits to the maintenance of the underlay network as well. The separation of concerns frees up the underlay so it can focus exclusively on providing highly available packet forwarding, and allows us to upgrade our physical network without worrying about breaking applications that were previously too tightly coupled to the physical infrastructure. It simplifies our operations, allows us to move services in and out of any data center, and removes the risk of vendor lock-in.
In short, we think overlay networks are awesome.
OpenContrail
When we first evaluated SDNs, we looked at various projects across the industry. Some configured the physical network via a central controller, others presented an abstraction layer that translated API calls into vendor-specific commands. Some solutions required new hardware, others would work over existing infrastructure. Some were developed by huge companies, others were open source projects, and still others were from scrappy startups. In short, we spent a ton of time doing homework and it wasn’t an easy decision. Here are a few requirements we settled on:
-
Functionality in our data centers (both old and new), bare metal, and the cloud
-
An open source project that wasn’t going to disappear overnight
-
Professional assistance to guide us on our journey
We landed on OpenContrail from Juniper Networks. OpenContrail is designed from the ground up to be an open source, vendor-agnostic solution that works with any existing network. BGP and MPLS are at its core - both are known protocols that have been proven to scale to the size of the entire internet. Juniper certainly isn’t going away anytime soon, and they have been extremely helpful while we designed and installed our first set of clusters. Check out the architecture documentation for all the down and dirty details.
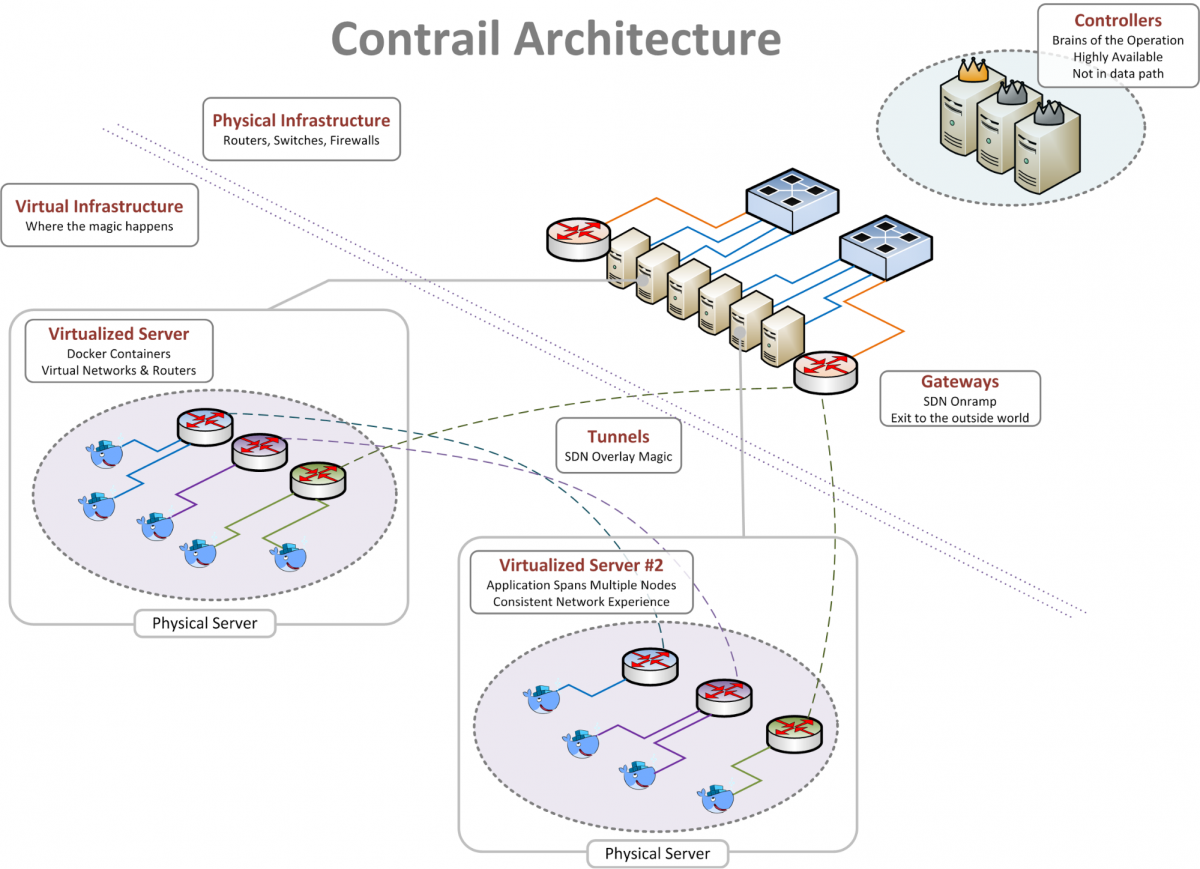
Three major components comprise Contrail: the centralized controller (the “brain”), the vRouter (virtual router), and the external gateway. Each component is a member of a highly available cluster, so no single device failure can take down the whole system. Interaction with the controller’s API immediately causes it to push all necessary changes out to the vRouters and gateways, which then physically forward traffic on the network.
The overlay network consists of a series of tunnels that span from one vRouter to another (protocol minutia: GRE w/MPLS, UDP w/MPLS or VXLAN, take your pick). When one container wants to talk to another, the vRouter first looks up where that container lives in the list of policies that the controller previously pushed to it, and then forms a tunnel from one compute node to another. The vRouter on the receiving end of the tunnel inspects the traffic inside to see if it matches a policy, and then delivers it only to the destination for which it is intended. If a container wishes to speak to the internet or to a non-overlay destination, we send that traffic out to one of the external gateways. The gateway removes the tunnel and sends the traffic on to the internet, keeping the container's unique IP address intact. This makes integrating with legacy applications and networks easy since nobody outside of the cluster can ever tell that the traffic originated from an overlay network.
Docker Integration
All of this is nothing more than an interesting thought experiment if we can’t spin up containers on the overlay network to do some real work for players. Contrail is a virtualization-agnostic SDN product, so it needs to be integrated with orchestrators to associate scheduled compute instances with the network features Contrail provides. Contrail has a robust integration with OpenStack via a Neutron API driver, however since we wrote our own orchestrator, Admiral, we also needed to write our own custom integration. Additionally, Contrail’s integration with OpenStack was originally designed for Virtual Machines, and we wanted to apply it to Docker containers. This necessitated a collaboration with Juniper to produce a service we call “Ensign” that runs on every host and handles the integration between Admiral, Docker, and Contrail.
To explain how we integrated Docker with Contrail, it is important to understand a bit about Linux networking. Docker uses a feature called network namespaces from the Linux kernel to isolate containers and prevent them from accessing each other. (This introduction to the topic is great further reading.) A network namespace is essentially a separate stack of network interfaces, routing tables, and iptables rules. Those elements in the network namespace are only applied to processes launched in the namespace. It's similar to chroot when used with a file system, but instead applied to networking.
When we started using Docker, there were four ways to configure the network namespace that containers would attach to:
-
Host networking mode: Docker places processes in the host network namespace, effectively making it not isolated at all.
-
Bridge network mode: Docker creates a Linux bridge that connects all the container’s network namespaces on the host and also manages iptables rules to NAT traffic from outside the host to a container.
-
From network mode: Docker uses the network namespace of another container.
-
None network mode: Docker sets up a network namespace with no interfaces, meaning processes within it cannot connect to anything external to the namespace.
The None network mode was built for third-party network integrations, which is great for what we were trying to do. After launching the container, a third-party can insert all the components into the network namespace that are needed to attach that container to the network. However, this presented a problem to us: the container has already launched and for some amount of time has zero networking. This is a bad experience for applications, since many want to know what IP address they are assigned on startup. While Riot developers could have potentially implemented retry logic, we didn’t want to burden them with it - plus, many third party containers can’t handle this, which we can’t change. We needed a more holistic solution.
In order to overcome this, we took a page from Kubernetes and introduced the concept of a “network” container that starts before the main application container. We launch that container with the None network mode, which has no problems as it doesn’t require connectivity or an IP. After the completion of network setup with Contrail and the assignment of an IP, we launch the main application container and use the From network mode to attach it to the network namespace of the network container. With this setup, applications have a fully operational networking stack on startup.
When we spin up a new container inside of a physical compute node (or host machine), the vRouter presents that container with a virtual NIC, a globally unique IP address and any routing or security policies that are associated with that container. This is very different than the default Docker networking configuration, in which every container on a server shares the same IP address, and all containers on a single machine can talk to each other freely. This behavior goes against our security policies, since two applications should never be able to do this by default. Giving each container its own IP address inside a secure, feature-rich virtual network allows us to give a consistent 'first class' networking experience to the container. It simplifies our configurations, our security policies, and allows us to avoid a lot of the out-of-the-box complexity that comes with many Docker containers sharing the same IP address as the host machine.
Conclusion
Our road to SDN and Infrastructure Automation has been a long one, and we still have a journey in front of us. We’ve had to learn a lot about how to establish best practices for self-service networking, how to debug connectivity issues on an overlay network, and how to deal with new failure modes. We’ve had to deploy this SDN across two generations of network architecture for the cluster itself and integrate it with a half-dozen “legacy” data center architectures. We've had to make investments in automation and learn how to ensure that our systems are trusted and our testing is well balanced. With that said, we’re now seeing the dividends of this work every day as Riot engineers can now develop, test, and deploy their services across the globe with a self-service workflow that transforms the network from a constant source of delay and frustration into a value-added service and another powerful tool in every developer’s toolbox.
In the next post on rCluster, we’ll talk about security, network blueprints and ACLs, how the system scales, and some of the work we’ve done to improve uptime.
If you have any thoughts or questions, please leave them below!
For more information, check out the rest of this series:
Part I: Introduction
Part II: Scheduling
Part III: Networking with OpenContrail and Docker (this article)
Part III: Part Deux: Networking with OpenContrail and Docker
Part IV: Dynamic Applications - Micro-Service Ecosystem
Part V: Dynamic Applications - Developer Ecosystem
Part VI: Products, Not Services