Running Online Services at Riot: Part III: Part Deux
In our previous article, we discussed some of the networking involved in rCluster, Riot’s solution for worldwide application deployments. Specifically, we talked about the concept of overlay networks, an implementation we leverage called OpenContrail, and how that solution plays with Docker. In this post, we’ll build on that foundation and dive deeper on other topics: infrastructure as code, load balancing, and failover testing. If you are curious about how and why we built some of the tools, infrastructure, and processes that we did, this write-up is for you.
Infrastructure as code
With OpenContrail providing an API to configure our networking, we now have the opportunity to automate our application’s networking needs. At Riot, we embrace continuous delivery as a best practice for releasing our applications. This means that every commit of code to the main branch is potentially releasable. In order to get to that state, the application must go through rigorous test automation and have a fully automated build and deployment pipeline. These deploys should also be repeatable and reversible in the case of problems. One of the complications of this approach is that an application’s functionality is not just its code, but also its environment, including the network features it depends on.
To make builds and deploys repeatable, every part of an application and its environment should be versioned and auditable (so we know who changed what). That means that I not only have every version of my application’s code in source control, but I have also described its environment in source control and versioned them together.
To enable this workflow, we built a system to describe the network features of an application in a simple JSON data model that we call a network blueprint. We then created a recurring job that pulls these blueprint files from our source control, which we then translate into API calls on Contrail to implement the appropriate policies. Using this data model, an application developer can define requirements such as one application’s ability to talk to another. Developers don't have to worry about IP addressing or any details that normally only a network engineer would truly understand.
Developers of applications own their own network blueprints. Changing them is now as easy as making a pull request to their blueprint file and having a peer merge it to the main branch. By enabling such a self-service workflow, our network changes are no longer bottlenecked by a small set of specialized network engineers. Now, the only bottleneck is the speed at which an engineer can edit a JSON file and click "submit."
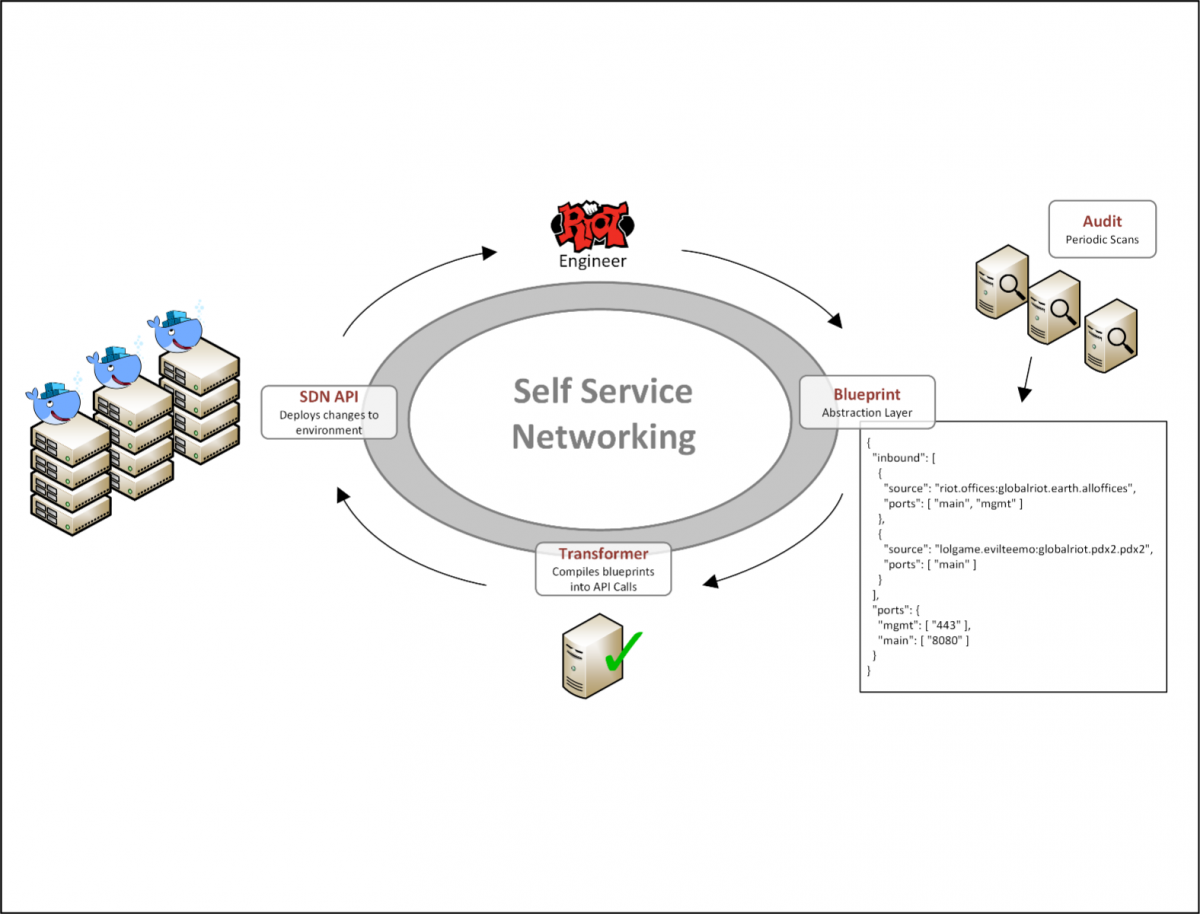
This system enables us to quickly and easily open up only the necessary network access, which is a key element to our security strategy. Here at Riot, player security is of paramount importance, so we baked security into our infrastructure. Two main pillars of our strategy are least privilege and defense in depth.
Least privilege means that any actor on Riot’s network can access only the minimum set of resources necessary to do its job. Actors might be people or our backend services. By enforcing this principle, we drastically limit the scope of effect for potential intrusions.
Defense in depth means that we enforce our security policies at multiple points in our infrastructure. If an attacker compromises or bypasses one of our enforcement points, they will always have more with which to contend. For example, public web servers are restricted from network access to the payment system, and that system also maintains its own set of defenses, such as layer 7 firewalls and intrusion detection systems.
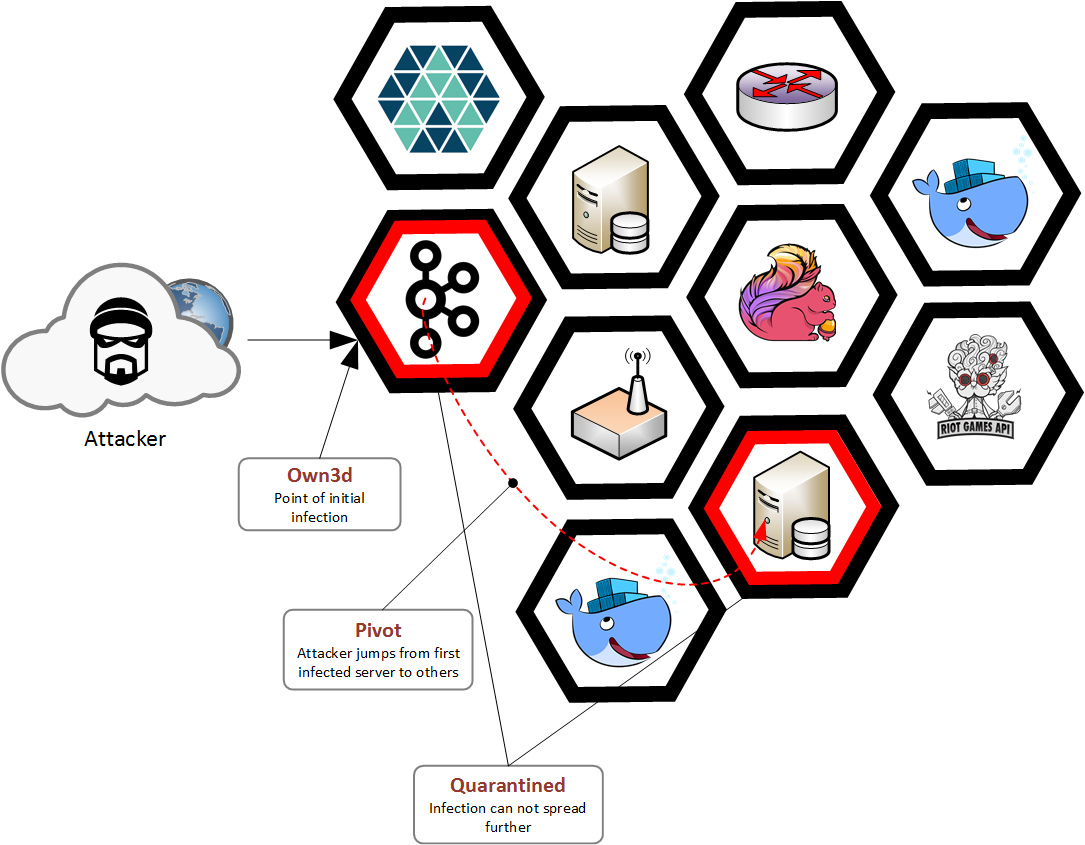
Contrail helps us by adding an enforcement point on each host via its vRouter. By using its API through the infrastructure-as-code JSON description, we always have an up-to-date, versioned, and easily auditable network policy for allowed communication between applications. We create tools that scan the network rules for policy violations and overly-open access. This combination of speed, strong security best practices, and the ability to audit makes for a strong security system that doesn't get in the way of our developers. Instead, it enables them to quickly and easily do the right thing.
Load Balancing
In order to meet the ever-increasing needs of our applications, we combine DNS, Equal Cost Multi-Pathing (ECMP), and a traditional TCP-based load balancer such as HAProxy or NGINX to provide a feature-rich and highly available load balancing solution.
On the internet we use DNS to spread the load across multiple global IP addresses. Players can look up a record such as 'riotplzmoarkatskins.riotgames.com' (not real but maybe it should be) and our servers can reply with multiple IP addresses that will answer to that DNS query. Half the players might receive a list with the location of server A at the top, while the other half will see the location of server B at the top. If either server is down, clients will automatically try the other, so nobody sees an interruption of service.
Inside our network, we have many servers all configured to answer for the IP address of server A. Each server advertises itself to the network with its ability to answer for this address, and the network sees each server as a possible destination. When a new player connection is received, we perform a hash calculation in the switches to deterministically calculate which server receives the traffic. The hash is based on a combination of the IP address and TCP port values inside the packet headers. If one of the servers goes on vacation, we attempt to minimize the impact by using a technique called consistent hashing to ensure that only the players using the failed server are impacted. Most of the time, clients handle this seamlessly by reinitiating a new connection automatically and impacted players don't even notice. Once we receive the new connection, we have already detected and removed the failed server, so we don't waste our time trying to send traffic to it. For most of our systems, we automatically spin up a new instance, and once it's ready to receive traffic, the system adds it back into rotation. We think it’s pretty slick. The last layer of load balancing is performed via a traditional TCP or HTTP based load balancer such as HAproxy or NGINX.
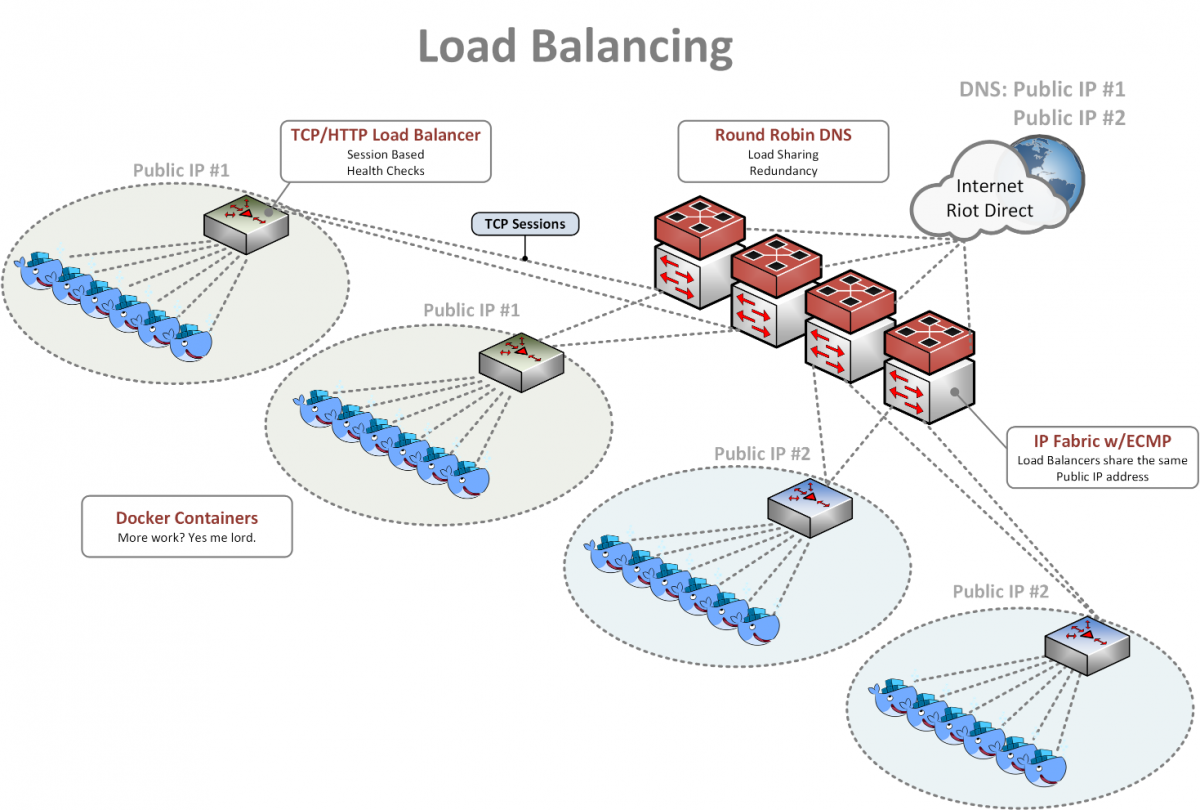
As requests come in from the ECMP layer, they can hit one of many load balancing instances. Those load balancing instances monitor each real web server and ensure that the server is healthy, responding in an appropriate amount of time, prepared to receive new connections, and so on. If all those conditions are met, the server receives the request and the reply goes all the way back to the player. This layer is where we typically do blue-green deploys and intelligent health checks. "Is /index.html loading with a response code of 200?" for example. In addition, we can do things like 'canary deploys' where one server out of 10 gets the newest version of the web page while the other 9 still serve the old version. We closely monitor the new version, making sure no issues creep up, and if it's going well we move two out of the ten servers to the new version, and so on. If things go poorly, we roll back to the last known stable version and figure out how to fix what went wrong. We then add a test to catch these issues earlier so we don't make the same mistake twice. This allows us to constantly improve our service while minimizing risk to production.
With all of the layers working together (DNS, ECMP, and traditional TCP or Layer 7 load balancing), we provide developers and players a feature-rich, stable, and scalable solution that lets us grow as fast as we can get servers installed in racks.
Failover Testing
One of the most important parts of having a highly available system is knowing that the system will actually fail over when something breaks. When we first started building data centers, we simulated these problems by having an engineer yank some cables out and reboot a few servers here and there. However, that process is difficult, inconsistent, and simply not acceptable once the data center is up and serving players. It encouraged us to build something once and then not touch it ever again. We absolutely discovered important issues and avoided outages with this process, but it needed serious improvement.
To start, we built a scaled down version of our data centers in a staging environment. It was sufficiently complete to be accurate without being wasteful. For example, in staging we have five servers per rack and only two racks. Production systems are much larger in both dimensions, but our questions are answered with a smaller (and cheaper) setup.
This staging environment is where we test all our changes before we ship them to production. Our automation deploys changes here, and with every change we have quick, basic tests that we perform on every change to keep us from doing something completely idiotic. This removes the fear of our automated systems becoming sentient, making a thousand runaway changes, and eventually melting the whole planet. We prefer to catch those types of bugs in staging rather than production.
In addition to our basic checks, we also have more complicated and disruptive testing that breaks important components and forces the system to run in a degraded state. While only three of four subsystems may be operational, we know that we can tolerate the loss and that we have time to repair the system without player impact.
This full suite of tests is more time-intensive, more disruptive (since we’d rather break the system and learn now than in production), and more complicated than the basic tests, so we run the full suite of failover testing on a less frequent basis. We fail every link, reboot the cores, reboot the top of racks, disable our SDN controllers, and anything else we can think of. We then measure the time it takes for the system to failover and make sure that everything is still running smoothly. If things drift we can look at the changes we made to our code since the last time we ran it and figure out what we might have changed before shipping the changes to production. If we ever run into an unforeseen issue in production that we didn't catch in our failover testing, we quickly add that test to the suite to ensure that it doesn't happen again. Our goal is always to find problems as early in the process as possible. The earlier we find the problem, the faster we can fix it. When we work this way, we can not only go fast, but go fast with confidence.
Conclusion
Building on the core concept and implementation of data center networking in our last article, this time we covered how we’re approaching infrastructure as code and the security implications, load balancing, and failover testing. “Change is the only true constant” might be a theme that unites these topics. Infrastructure is a living, breathing, evolving animal. We need to provide resources when it's time to grow, we need to react when it gets sick, and we need to do it all as fast as possible at a global scale. Embracing this reality means ensuring that our tools, processes, and paradigms can react to the dynamic environment. All of this leads us to believe that it’s an extremely exciting time to be developing production infrastructure.
If you agree, check out our careers page. We're always looking for engineers who can level us up and prevent the planet-melting bugs we mentioned earlier.
And as always, leave your questions and comments below.
For more information, check out the rest of this series:
Part I: Introduction
Part II: Scheduling
Part III: Networking with OpenContrail and Docker
Part III: Part Deux: Networking with OpenContrail and Docker (this article)
Part IV: Dynamic Applications - Micro-Service Ecosystem
Part V: Dynamic Applications - Developer Ecosystem
Part VI: Products, Not Services