Running Online Services at Riot: Part I
My name is Jonathan McCaffrey and I work on the infrastructure team here at Riot. This is the first post in a series where we’ll go deep on how we deploy and operate backend features around the globe. Before we dive into the technical details, it’s important to understand how Rioters think about feature development. Player value is paramount at Riot, and development teams often work directly with the player community to inform features and improvements. In order to provide the best possible player experience, we need to move fast and maintain the ability to rapidly change plans based upon feedback. The infrastructure team’s mission is to pave the way for our developers to do just that - the more we empower Riot teams, the faster features can be shipped to players to enjoy.
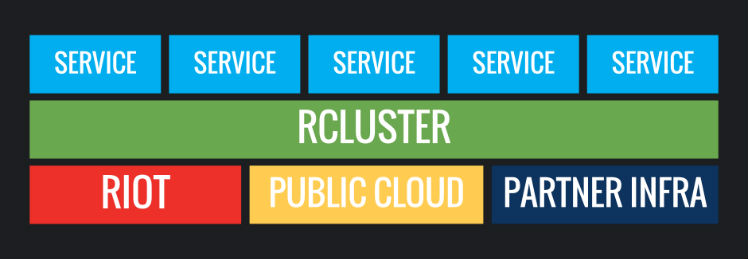
Of course, that’s easier said than done! A host of challenges arise given the diverse nature of our deployments - we have servers in public clouds, private data-centers, and partner environments like Tencent and Garena, all of which are geographically and technologically diverse. This complexity places a huge burden on feature teams when they are ready to ship. That’s where the infrastructure team comes in - we’ve recently made progress in removing some of these deployment hurdles with a container-based internal cloud environment that we call ‘rCluster.’ In this article I’ll discuss Riot’s journey from manual deploys to the current world of launching features with rCluster. As an illustration of rCluster’s offerings and technology, I’ll walk through the launch of the Hextech Crafting system.
A bit of history
When I started at Riot 7 years ago, we didn't have much of a deployment or server management process; we were a startup with big ideas, a small budget, and a need to move fast. As we built the production infrastructure for League of Legends, we scrambled to keep up with the demand for the game, demand to support more features from our developers, and demand from our regional teams to launch in new territories around the world. We stood up servers and applications manually, with little regard to guidelines or strategic planning.
Along the way, we moved towards leveraging Chef for many common deployment and infrastructure tasks. We also started using more and more public cloud for our big data and web efforts. These evolutions triggered changes in our network design, vendor choices, and team structure multiple times.
Our datacenters housed thousands of servers, with new ones installed for almost every new application. New servers would exist on their own manually created VLAN with handcrafted routing and firewall rules to enable secure access between networks. While this process helped us with security and clearly defined fault domains, it was arduous and time-consuming. To compound the pain of this design, most of the newer features at the time were designed as small web services, so the number of unique applications in our production LoL ecosystem skyrocketed.
On top of this, our development teams lacked confidence in their ability to test their applications, particularly when it came to deploy-time issues like configuration and network connectivity. Having the apps tied so closely to the physical infrastructure meant that differences between production datacenter environments were not replicated in QA, Staging, and PBE. Each environment was handcrafted, unique, and in the end, consistently inconsistent.
While we grappled with these challenges of manual server and network provisioning in an ecosystem with an ever-increasing number of applications, Docker started to gain popularity amongst our development teams as a means to solve problems around configuration consistency and development environment woes. Once we started working with it, it was clear that we could do more with Docker, and it could play a critical role in how we approached infrastructure.
Season 2016 and beyond
The infrastructure team set a goal to solve these problems for players, developers, and Riot for Season 2016. By late 2015, we went from deploying features manually to deploying features like Hextech Crafting in Riot regions in an automated and consistent fashion. Our solution was rCluster - a brand new system that leveraged Docker and Software Defined Networking in a micro-service architecture. Switching to rCluster would pave over the inconsistencies in our environments and deployment processes and allow product teams to focus squarely on their products.
Let’s dive into the tech a bit to examine how rCluster supports a feature like Hextech Crafting behind the scenes. For context, Hextech Crafting is a feature within League of Legends that provides players a new method of unlocking in-game content.
The feature is known internally as “Loot,” and is comprised of 3 core components:
-
Loot Service - A Java application serving Loot requests over an HTTP/JSON ReST API.
-
Loot Cache - A caching cluster using Memcached and a small golang sidecar for monitoring, configuration, and start/stop operations.
-
Loot DB - A MySQL DB cluster with a master and multiple slaves.
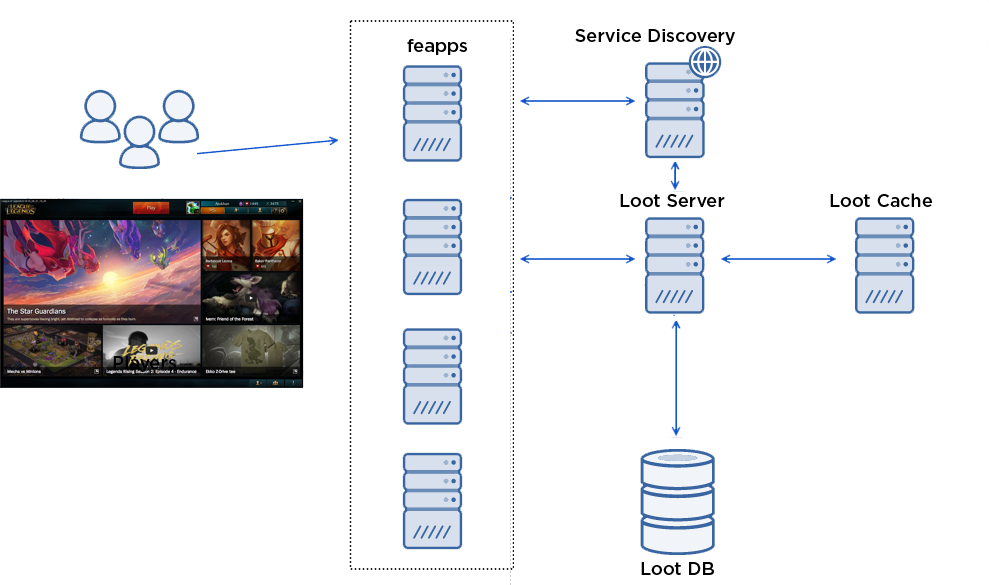
When you open the crafting screen, here is what happens:
-
A player opens the crafting screen in the Client.
-
The Client makes an RPC call to the frontend application, aka “feapp” which proxies calls between players and internal backend services.
-
The feapp calls to the Loot Server
-
The feapp looks up the Loot Service in “Service Discovery” to find its IP and port information.
-
The feapp makes an HTTP GET call to the Loot Service.
-
The Loot Service checks the Loot Cache to see if the player’s inventory is present.
-
The inventory isn’t in the cache, so the Loot Service calls Loot DB to see what the player currently owns and populates the cache with the result.
-
Loot Service replies to the GET call.
-
-
The feapp sends the RPC response back to the Client.
Working with the Loot team, we were able to get the Server and Cache layers built into Docker containers, and their deployment configuration defined in JSON files that looked like this:
Loot Server JSON Example:
{
"name": "euw1.loot.lootserver",
"service": {
"appname": "loot.lootserver",
"location": "lolriot.ams1.euw1_loot"
},
"containers": [
{
"image": "compet/lootserver",
"version": "0.1.10-20160511-1746",
"ports": []
}
],
"env": [
"LOOT_SERVER_OPTIONS=-Dloot.regions=EUW1",
"LOG_FORWARDING=true"
],
"count": 12,
"cpu": 4,
"memory": 6144
}Loot Cache JSON Example:
{
"name": "euw1.loot.memcached",
"service": {
"appname": "loot.memcached",
"location": "lolriot.ams1.euw1_loot"
},
"containers": [
{
"name": "loot.memcached_sidecar",
"image": "rcluster/memcached-sidecar",
"version": "0.0.65",
"ports": [],
"env": [
"LOG_FORWARDING=true",
"RC_GROUP=loot",
"RC_APP=memcached"
]
},
{
"name": "loot.memcached",
"image": "rcluster/memcached",
"version": "0.0.65",
"ports": [],
"env": ["LOG_FORWARDING=true"]
}
],
"count": 12,
"cpu": 1,
"memory": 2048
}However, to actually deploy this feature - and really make progress on mitigating the pains I outlined earlier - we needed to create clusters that could support Docker around the world in places like North & South America, Europe, and Asia. This required us to solve a bunch of hard problems like:
-
Scheduling Containers
-
Networking With Docker
-
Continuous Delivery
-
Running Dynamic Applications
Subsequent posts will dive into these components of the rCluster system in more detail, so I’ll just touch on each briefly here.
Scheduling
We implemented container scheduling in the rCluster ecosystem using software we wrote called Admiral. Admiral talks to Docker daemons across an array of physical machines to understand their current live state. User make requests by sending the above-mentioned JSON over HTTPS, which Admiral uses to update its understanding of the desired state of the relevant containers. It then continually sweeps both the live and desired state of the cluster to figure out what actions are needed. Finally, Admiral makes additional calls to the Docker daemons to start and stop containers to converge on that desired state.
If a container crashes, Admiral will see a divergence in live vs desired, and start the container on another host to correct it. This flexibility makes it much easier to manage our servers because we can seamlessly “drain” them, do maintenance, and then re-enable them to take workloads.
Admiral is similar to the open source tool Marathon, so we are currently investigating porting our work over to leverage Mesos, Marathon, and DC/OS. If that work bears fruit, we’ll talk about it in a future article.
Networking with Docker
Once the containers are running, we need to provide network connectivity between the Loot application and other parts of the ecosystem. In order to do that, we leveraged OpenContrail to give each application a private network, and let our development teams manage their policies themselves using JSON files in GitHub.
Loot Server Network:
{
"inbound": [
{
"source": "loot.loadbalancer:lolriot.ams1.euw1_loot",
"ports": [
"main"
]
},
{
"source": "riot.offices:globalriot.earth.alloffices",
"ports": [
"main",
"jmx",
"jmx_rmi",
"bproxy"
]
},
{
"source": "hmp.metricsd:globalriot.ams1.ams1",
"ports": [
"main",
"logasaurous"
]
},
{
"source": "platform.gsm:lolriot.ams1.euw1",
"ports": [
"main"
]
},
{
"source": "platform.feapp:lolriot.ams1.euw1",
"ports": [
"main"
]
},
{
"source": "platform.beapp:lolriot.ams1.euw1",
"ports": [
"main"
]
},
{
"source": "store.purchase:lolriot.ams1.euw1",
"ports": [
"main"
]
},
{
"source": "pss.psstool:lolriot.ams1.euw1",
"ports": [
"main"
]
},
{
"source": "championmastery.server:lolriot.ams1.euw1",
"ports": [
"main"
]
},
{
"source": "rama.server:lolriot.ams1.euw1",
"ports": [
"main"
]
}
],
"ports": {
"bproxy": [
"1301"
],
"jmx": [
"23050"
],
"jmx_rmi": [
"23051"
],
"logasaurous": [
"1065"
],
"main": [
"22050"
]
}
}Loot Cache Network:
{
"inbound": [
{
"source": "loot.lootserver:lolriot.ams1.euw1_loot",
"ports": [
"memcached"
]
},
{
"source": "riot.offices:globalriot.earth.alloffices",
"ports": [
"sidecar",
"memcached",
"bproxy"
]
},
{
"source": "hmp.metricsd:globalriot.ams1.ams1",
"ports": [
"sidecar"
]
},
{
"source": "riot.las1build:globalriot.las1.buildfarm",
"ports": [
"sidecar"
]
}
],
"ports": {
"sidecar": 8080,
"memcached": 11211,
"bproxy": 1301
}
}When an engineer changes this configuration in GitHub, a transformer job runs and makes API calls in Contrail to create and update policies for their application’s private network.
Contrail implements these private networks using a technique called Overlay Networking. In our case, Contrail uses GRE tunnels between compute hosts, and a gateway router to manage traffic entering and leaving the overlay tunnels and heading to the rest of the network. The OpenContrail System is inspired by and conceptually very similar to standard MPLS L3VPNs. More in depth architectural details can be found here.
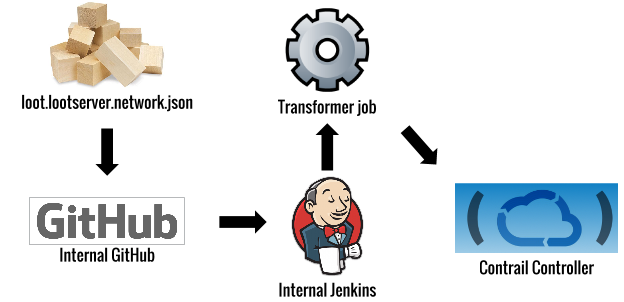
As we implemented this system, we had to tackle a few key challenges:
-
Integration between Contrail and Docker
-
Allowing the rest of the network (outside of rCluster) to access our new overlay networks seamlessly
-
Allowing applications from one cluster to talk to another cluster
-
Running overlay networks on top of AWS
-
Building HA edge-facing applications in the overlay
Continuous Delivery
Max Stewart has previously posted about Riot’s use of Docker in continuous delivery, which rCluster also leverages.
For the Loot application, the CI flow goes something like this:
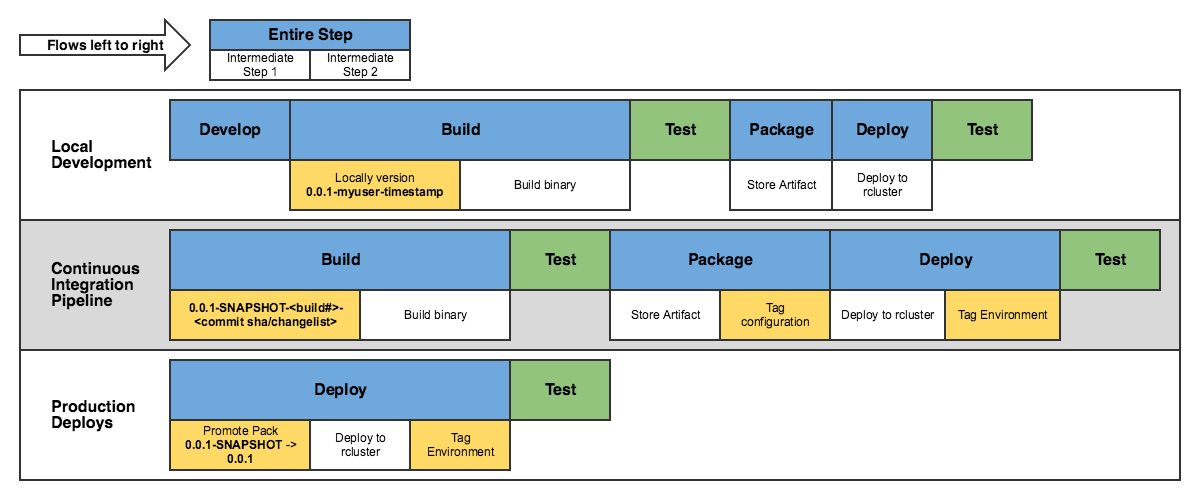
The general goal here is that when the master repo is changed, a new application container is created and deployed to a QA environment. With this workflow in place, teams can quickly iterate on their code and see the changes reflected in a working game. That tight feedback loop makes it possible to refine the experience rapidly, which is a key goal of player-focused Engineering here at Riot.
Running Dynamic Applications
By this point we’ve talked through how we build and deploy features like Hextech Crafting, but if you’ve spent much time working with container environments like this, you know that's not the whole problem.
In the rCluster model, containers have dynamic IP addresses and are constantly spinning up and down. This is an entirely different paradigm than our previous static server and deployment approach, and thus requires new tools and procedures to be effective.
Some key issues raised are:
-
How do we monitor the application if its capacity and endpoints are changing all the time?
-
How does one app know the endpoint of another if it’s changing all the time?
-
How does one triage application issues if you can’t ssh into the containers and logs are reset whenever a new container is launched?
-
If I am baking my container at build time, how do I configure things like my DB password or what options are toggled for Turkey vs North America?
To solve these, we had to build a Microservices Platform to handle things like Service Discovery, Configuration Management and Monitoring; we’ll dive into more details about this system and the problems it solves for us in our final installment of this series.
Conclusion
I hope this article gave you an overview of the kind of problems we are trying to solve to make it easier for Riot to deliver player value. As stated before, we are going to follow this up with a series of articles focusing on rCluster’s use of scheduling, networking with Docker, and running dynamic applications; as those articles are released, the links will be updated here.
If you are on a similar journey, or want to be part of the conversation, we’d love to hear from you in the comments below.
For more information, check out the rest of this series:
Part I: Introduction (this article)
Part II: Scheduling
Part III: Networking with OpenContrail and Docker
Part III: Part Deux: Networking with OpenContrail and Docker
Part IV: Dynamic Applications - Micro-Service Ecosystem
Part V: Dynamic Applications - Developer Ecosystem
Part VI: Products, Not Services