Running Online Services at Riot: Part VI
Welcome back to the Running Online Services series! This long-running series explores and documents how Riot Games develops, deploys, and operates its backend infrastructure. We are Nicolas Tittley and Ala Shiban, software architect and product manager on the Riot Developer Experience team. Our team is responsible for how Riot developers build, deploy, and operate games everywhere our players are, with a focus on a cloud-agnostic platform that makes shipping and operating games continuously easier. In our last installment nearly 2 years ago, Maxfield Stewart wrote about our developer ecosystem and the many tools used then. Since 24 months is an eternity in this space, we figured we would update you all on how things have worked out, new challenges we faced, and what we learned addressing them!
A Quick Recap
We highly recommend going back and reading the earlier entries, but if you want to jump straight into this article, here’s a super condensed version to catch you up.
Riot uses a mix of metal and cloud infrastructure to operate backend systems around the world. Those backend systems are separated into geographical shards, which are fully distinct deployments of the full set of services that allow players to engage with League of Legends. Like most game backends, the League backend began as a monolith operated by a dedicated operations team. Over time, Riot has embraced both DevOps practices and microservice-based architectures. Part 1 of this series goes into the details - in order to help our developers deliver player value faster, Riot leaned heavily into packaging services as Docker containers and started running them in a clustered scheduler. The last article, part V, discusses the many pieces of tooling we put in place to enable this.
So How’d It Go?
It went awesomely. And also poorly.
At the time of the previous entry in this series, we were operating just above 5000 production containers. That number has not stopped increasing, and today, we run more than 14,500 containers in Riot-operated regions alone. Riot devs love to make new things for players, and the easier it gets for them to write, deploy, and operate services, the more they create new and exciting experiences.
In true DevOps fashion, teams owned and were responsible for their services. They created workflows to deploy, monitor, and operate their services, and when they couldn’t find just the thing they wanted, they didn’t shy away from inventing it themselves. This was a very liberating time for our developers as they were rarely blocked on anything that they couldn’t resolve on their own.
Slowly however, we started noticing some worrying trends. Our QA and load testing environments were getting less stable every month. We would lose an increasing amount of time tracking down misconfigurations or out-of-date dependencies. Isolated, each event was nothing critical, but collectively, they cost us time and energy that we would much prefer to spend on creating player value.
Worse, our non-Riot shards were starting to exhibit not only similar difficulties but a whole set of other problems. Partner operators had to interface with an ever-increasing number of developers and onboard an ever growing number of microservices, each distinct from the others in different ways. Operators now had to work harder than ever to produce working and stable shards. These non-Riot-operated shards had a much higher incident rate directly attributable to incompatible live versions of microservices or other similar cross-cutting problems.
Riot’s Development And Operational Reality
Before we discuss how we solved packaging, deployment, and operations, let’s take a minute to explore the context in which Riot operates. None of this is unique to Riot, but the overlap of all of these details informs how we organize ourselves in order to ship value to all our players.
Developer Model
Riot engineers love to build things! To facilitate them doing just that, we’ve adopted a strong DevOps mindset. Teams build and own their backend services, ensure support for them, and triage when they don’t perform as expected. By and large, Riot engineers are happy to be able to iterate quickly and also happy to be held accountable for their live services. This is a pretty standard DevOps setup and Riot isn’t bucking the trend on anything here.
Stateful Sharding Model
For historical, scaling, and legal reasons, the backends for Riot products are organized in shards. Production shards are typically deployed geographically close to their target audience. This has a number of benefits, including improved latency, better matchmaking, limited failure domain, and a clear off-peak time window in which to perform maintenance. Of course, we also operate many development and QA shards both internally and externally, like the League Public Beta Environment (PBE).
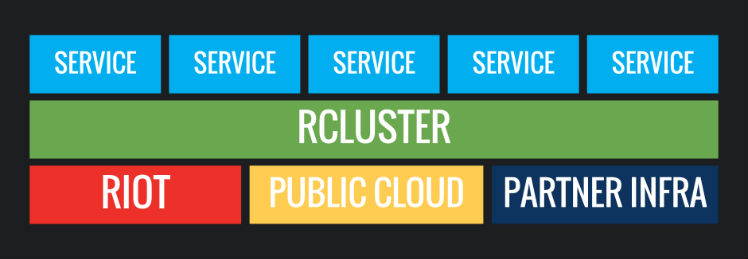
Operations Model
This is where things get somewhat more complex. While Riot is the developer, for compliance and knowhow reasons, we partner with local operators for some of our shards. Practically, this means that Riot developers must package up every component of a shard, deliver that to the operator, and instruct them how to deploy, configure, and operate all of it. Riot developers do not operate, have access, or even have visibility into those shards.
Iterating on a Solution
Attempt #1 - New League Deployment Tooling
For our first attempt at improving the situation we took a greenfield approach and attempted to craft a deployment and operations story for Riot leveraging open-source components and minimal Riot-specific features. While the effort successfully deployed a full League of Legends shard, the way the tools were designed did not behave the way developers and operators expected them to. Teams voiced their dissatisfaction with the tooling which proved to be too difficult to adopt for operations and too constrained for developers.
And so, the painful decision was made to retire the tooling after the first shard was deployed. While this might seem aggressive, it allowed us to fully retire the new tooling quickly as all teams still had their own maintained deployment systems and hadn’t fully cut over.
Attempt #2 - More Process
Since our first attempt wasn’t the resounding success we hoped for, we turned to the time-honored tradition of adding process. Broad communications, clear release dates, documented processes, change management meetings and rituals, and the ever-present spreadsheets moved the needle somewhat but never felt good. Teams liked their DevOps liberties and the sheer volume and velocity of changes forced a heavier process on them. While the situation improved for our partner operators, we weren’t reaching the operational bar and the quality of life that we desired.
Attempt #3 - Metadata
At this point, we decided to try a different approach. As we had been focusing on the developers as the main audience for our tools, we started investigating how a deployment/operations system focused on partner ops personnel would work. We crafted tooling that would allow developers to add standardized metadata, such as required configurations and scaling characteristics to their Docker containers’ packaged microservice. This created forward progress. Operators had a more standardized way of understanding required configurations and deployment characteristics of services and relied less on the developers for day-to-day operation.
At this point, the rate of failures, incidents and extra downtime across local and partner operational sites showed improvement, but we were still encountering frequent and avoidable deployment and operations failures.
Attempt #4 - Riot’s Application and Environment Model
We eventually took a new approach, changing the focus from individual services to entire products. This led us to creating a high-level declarative specification and set of tools that act on it. Before we look at what makes this specification and tooling different, let’s look at what went wrong with the previous three attempts.
Reflecting on What Went Wrong
Deploying And Operating A Product, Not A Service
While embracing DevOps and microservices gave us many upsides, it created a risky feedback loop. Development teams made microservices, deployed them, operated them, and were held accountable for their performance. This meant they optimized logs, metrics, and processes for themselves and in general rarely considered their services as something that someone without development context or even engineering ability would have to reason with.
As developers kept creating more and more microservices, operating the holistic product became very difficult and resulted in an increasing number of failures. On top of that, the fluid team structure at Riot was leaving some microservices with unclear ownership. This made knowing who to contact while triaging difficult, resulting in many incorrectly attributed pages. Partner regions ops teams became overwhelmed by the increasing number of heterogeneous microservices, deployment processes, and organizational changes.
Understanding The Why
We’ve inspected failures across Riot-operated-regions and the non-Riot-operated regions, and distilled the differences in failure frequency into one key observation:
Allowing unaligned streams of changes into a distributed system will eventually lead to preventable incidents.
Failures start to happen when teams are looking to coordinate across their boundaries, where dependencies require bundling a release with multiple changes. Teams either employ human processes to create release cycles, coordinating releases through program management rituals, or they can ad-hoc release changes that break at smaller scale, leading the teams to scramble while they figure out a compatible arrangement of versions.
Both have their pros and cons, but tend to break down in large-scale organizations where tens of teams need to continuously ship hundreds of microservices representing a shared product in a coordinated manner and where those microservices are allowed to use different development practices. Even worse, trying to apply those processes with a partner operator becomes prohibitively difficult due to their lack of context on how the pieces all fit together.
The New Solution: Riot’s Application and Environment Model
Given that the previous attempts failed to produce the desired outcome, we decided to eliminate partial state manipulation by creating an opinionated declarative specification that captures the entirety of a distributed product - an environment. An environment contains all the declarative metadata required to fully specify, deploy, configure, run, and operate a set of distributed microservices collectively representing a product and is holistically and immutably versioned. For those wondering, we picked “environment” because it was the least overloaded term at Riot. Naming things is hard.
With the launch of Legends of Runeterra, we proved that we could describe an entire microservice game backend, game servers included, and have it deploy, run, and be operated as a product in Riot regions as well as in partner data centers across the globe. We also demonstrated the ability to achieve this while improving the upsides of the DevOps methods we’ve grown to love so much.
Opinionated on what?
The specification describes the hierarchical relationships between service bundles, or environments.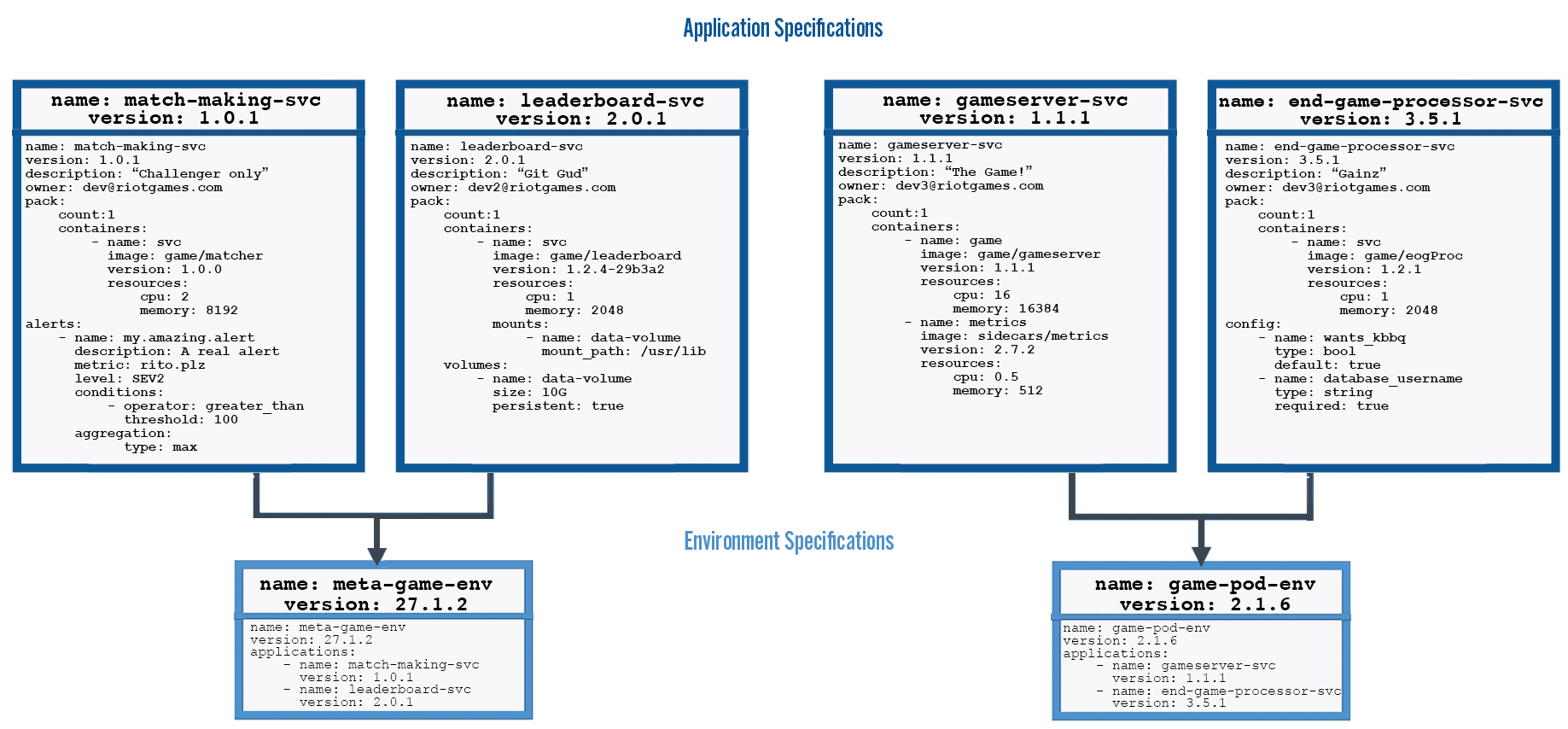
Application Specifications Bundled into Environment Specification
Declarative and High Level
One of the benefits of a declarative specification is that it’s operator friendly. One of the difficulties partner operators called out was their inability to understand, tweak, and potentially automate how an entire game backend is deployed. The declarative nature of the specification meant it didn’t require an engineer to have scripting or programming expertise to make changes to the majority of what's in the specification.
Keeping the specification high level helped decouple the definition of a game backend from the underlying implementation. This enabled us to move from our in-house orchestrator/scheduler called Admiral to a Mesos-based scheduler, and to consider migrating to Kubernetes with minimal impact on game studios. It also enabled our partner operators to swap in their infrastructure component when needed. For example, it lets an operator use a different metrics aggregation system without requiring microservice instrumentation changes.
Immutable and Versioned
We found that to deploy and operate effectively in a fast-paced DevOps world, having a shared language to refer to services and environment is crucial. Versioning services and environment and their associated metadata allowed us to ensure that the correct version of everything was deployed in all locations. It allowed our partner operators to know with certainty and to communicate back to us which version was running. Further, when applied to a whole environment, it provides a well-known set of services that can be QAed and marked as good. This bundling removes any chances that a dependency is missed while communicating a new release to partners.
Making those versions immutable ensures that we maintain this common language. If the same version of a service is deployed in two different shards, we now know with certainty that they are the same.
Operationally Focused
Since our aim was to improve the quality of service that partner operators could offer to their players, we quickly realized that deploying software is only the first step. Understanding how to triage, operate, and maintain the live system is equally as important.
Historically, we relied heavily on runbooks. Those were maintained with a varying degree of success by the developers, who documented everything from required configuration values to high-level architecture. In order to equip the partner operators with the full knowledge required to configure and operate every service we decided to bring as much of the information contained in those runbooks to the forefront of our service specification. This greatly reduced the time partner regions spent onboarding new services and insured they were informed about all important changes as microservices were updated.
Today, partner operators use the spec to be informed about operational metadata, including required/optional configurations, scaling characteristics, maintenance operations, important metrics/alert definitions, deployment strategies, inter-service dependencies, and an increasing amount of other useful information.
Handling shard differences
Of course, shards aren’t exact copies of each other. While we want to keep them as close to each other as possible, there is always some configuration that has to differ. Database passwords, supported languages, scaling parameters, and particular tuning parameters have to vary per shard. To support this model our tooling deploys an environment specification using a layered override system allowing operators to specialize particular deployments while still knowing that they are all derived from the known good version. Let’s see how that works!
Example
A simple game backend could be comprised of two environments, one for game servers and the other for meta-game services (leaderboards, matchmaking, etc). The meta-game environment is comprised of multiple services: leaderboard, matchmaking, match history, and more. Each service is comprised of one or more Docker images, equivalent conceptually to a Kubernetes pod. The same hierarchy is true for all environments and philosophically, an environment encapsulates - without exception - everything needed to deploy, run, and operate a game backend, and all its dependencies, on any supported infrastructure or cloud.
The specification also includes all the metadata required to run and operate an entire environment. A growing set including configuration, secrets, metrics, alerts, documentation, deployment and rollout strategies, inbound network restrictions, as well as storage, database, and caching requirements.
Below we have an example of two hypothetical game shard deployments in two regions. You can see that they’re both comprised of a meta-game environment, and a game-server environment. The game-server-prod environment in the EU shard is trailing the equivalent one in the Americas shard. This provides a common language for game and operation teams to describe and compare different game shard deployments. The simplicity is maintained with the ever-increasing number of services per environment, enabling the deployment of tens of shards reliably.

Examples of Game Shard Deployments
Our Next Step: Latency Aware Scheduling
We’d like to be able to describe expected and acceptable latencies between services, and have the tooling optimize for which underlying regions and lower-level PaaS services would meet those needs. This will lead to some services being co-located in the same rack, host, or cloud region vs. allowing them to be distributed across others.
This is highly relevant for us due to the performance characteristics of game servers and supporting services. Riot is already a multi-cloud company, leveraging our own data centers, AWS and partner clouds, but we rely on statically designed topologies. Card games and shooters have different profiles, and not having to handcraft topologies that optimize for one scenario or the other frees up engineering time that can be spent focusing on games.
Final Words
We were facing decreasing stability across our games, predominantly in partner-operated game shards. Tooling teams bundled open-source deployment tools and added metadata to containers, while game teams implemented centralized release processes. These approaches addressed symptoms, but not the root cause which meant we were failing to hit the quality bar we aimed for.
The solution that we eventually landed on introduced a new specification that captured the entire topology, hierarchy, and metadata of an entire game backend and all its dependencies. This approach worked because it led to consistent, versioned releases of bundled containers, their dependencies, how they should be interacting with one another, and all the supporting metadata that was required to launch and operate an entire game. The immutability led to deterministic deployments and predictable operations.
As a platform team, our aim is to pick systems and building blocks that create virtuous cycles where feature development work naturally results in easy to operate products. Marrying the agility of the DevOps model with ease of operating an entire product is the key to long term organizational agility. Our approach to environment bundling directly improved our operational metrics, and more importantly improved the quality of the player experience. We are excited to see how the rest of the industry addresses similar problems. We’ve seen ideas and projects coming from both the CNCF (Cloud Native Computing Foundation) and from big cloud vendors, like the Microsoft Open Application Model Spec. We’re hoping some of those projects supersede our homegrown specification, and converge towards an industry-wide solution.
In a future article, we’ll explore the Riot spec in more detail, looking at examples and discussing tradeoffs and Riot-specific shortcuts in our design.
Thanks for reading! If you have questions, feel free to post them in the comments below.
For more information, check out the rest of this series:
Part I: Introduction
Part II: Scheduling
Part III: Networking with OpenContrail and Docker
Part III: Part Deux: Networking with OpenContrail and Docker
Part IV: Dynamic Applications - Micro-Service Ecosystem
Part V: Dynamic Applications - Developer Ecosystem
Part VI: Products, Not Services (this article)