
Scalability and Load Testing for VALORANT
Hi, I’m Keith Gunning, lead engineer on the Core Services team for VALORANT. My team is responsible for making sure VALORANT’s platform can scale to support our growing playerbase, with high uptime and sufficient monitoring to quickly detect and fix problems.
When VALORANT was still early in development, we had high hopes that in the future we’d launch with high initial popularity. From the beginning, we prioritized scalability to make sure we could support the number of players we were hoping for. Once VALORANT entered full production, we began working in earnest on a load test framework to prove out our tech. After many months of work, we successfully ran a load test of two million simulated players against one of our test shards, giving us the confidence we needed for a smooth launch. This article explains how we load tested our platform, and how we tackled the scaling challenges we encountered along the way.
VALORANT’S Infrastructure
Two key pieces of VALORANT’s infrastructure allow us to support a large number of players - the game server executable and the platform.
The game server executable controls the frame-to-frame gameplay of in-progress matches. To run a large number of games simultaneously, we need to run thousands of these game server executables, one for each running match. This Tech Blog post by Brent Randall from the VALORANT Gameplay Integrity team explains the efforts made to hyper-optimize the game server executable, allowing it to run over three 128-tick games of VALORANT per CPU core, minimizing the number of total CPUs necessary to host every game.
The second piece of infrastructure, which I’ll refer to as the VALORANT platform, is a collection of microservices that handles every other part of VALORANT besides moment-to-moment gameplay.
Here's a list of services the platform includes:
-
party membership
-
matchmaking
-
Agent selection
-
provisioning matches to datacenters based on ping
-
processing and storage of game results when games are finished
-
unlocking Agent contracts and Battlepasses
-
store purchases
-
loadout selection
These platform services, together with the game provisioner pods, form a VALORANT shard.
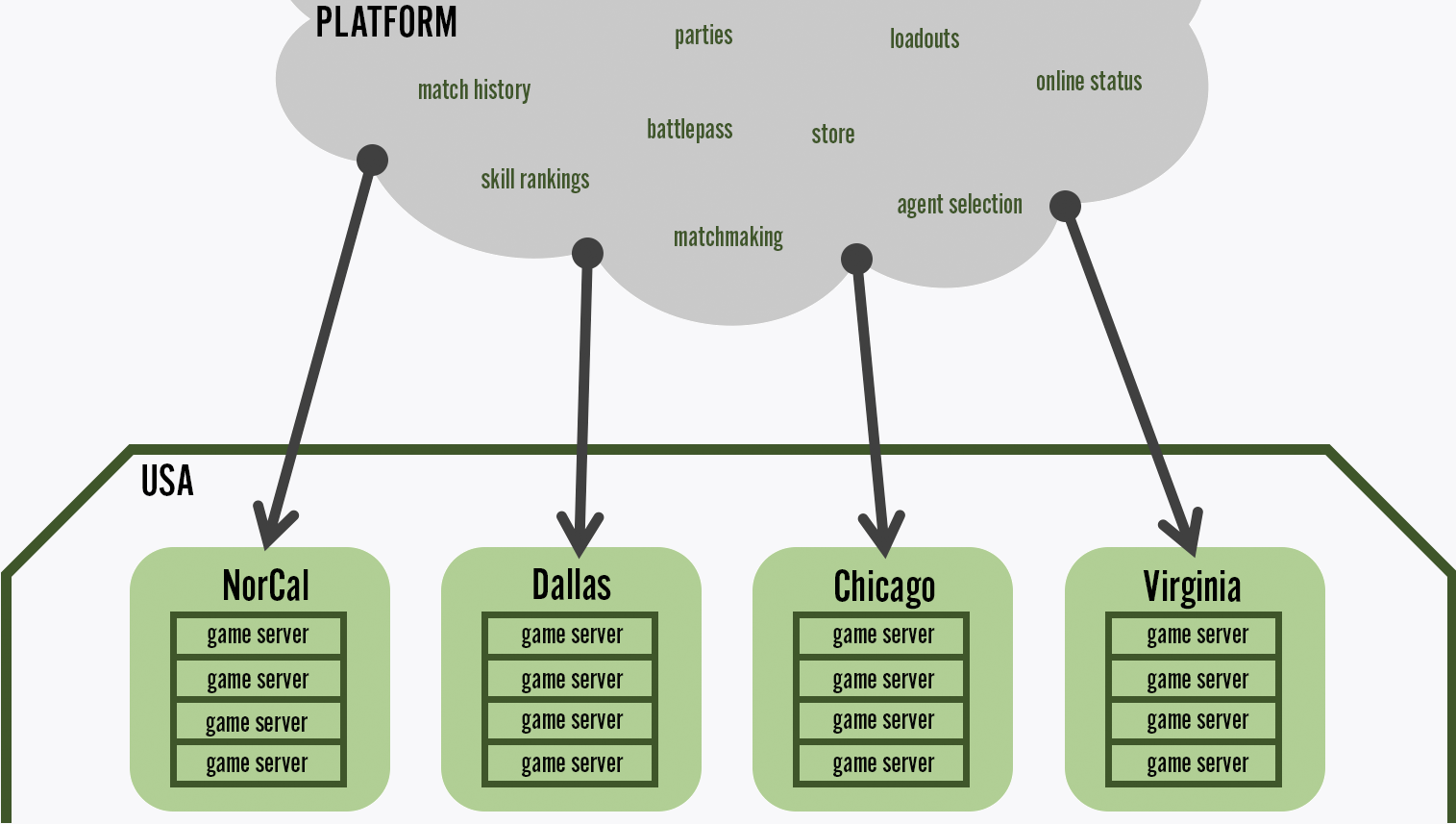 Each shard's platform manages a set of geographically distributed game server pods
Each shard's platform manages a set of geographically distributed game server pods
A Closer Look At The VALORANT Platform
Each piece of the platform’s functionality is encapsulated in a microservice, a small program responsible for only its own specific VALORANT feature. For example, the personalization service stores the list of gun skins, sprays, and gun buddies players currently have equipped, and not much else. Some features require several microservices to communicate with each other. For example, when a party queues up for a ranked game, the parties service will ask the skill ratings service to verify that the players in the party are within the allowed rank spread to play a competitive match together. If so, it will then ask the matchmaking service to add the party to the competitive queue.
VALORANT chose to create a platform composed of microservices based on what we had learned from League of Legends. In the early days of League, the platform was a monolithic service that could do everything. This made development and deployment simple, but came at a cost. A bug in one subsystem could bring down the whole platform. There was less flexibility to independently scale up individual subsystems, and individual subsystems couldn’t be built, tested, and deployed independently. League has since upgraded to a more flexible microservices model to address these problems. Following in League’s footsteps, VALORANT avoided the pitfalls of a monolithic architecture by splitting functionality into smaller microservices from the start.
Microservices
The VALORANT platform consists of over 30 microservices. Each shard needs a certain number of instances of each microservice to handle peak numbers of players. Some microservices are busier and require more instances than others to distribute the load. For example, the parties service does a lot of work, since players are constantly joining, leaving, and changing the state of their parties. We have many instances of the parties service running. The store’s microservice requires fewer instances, since players buy from the store much less frequently than they join parties.
To support the high load we were hoping for on launch day, we needed to answer several questions. How many instances of each microservice would be necessary? Did any microservice have a serious performance problem that couldn’t be solved by just deploying more instances of the service? Did any service have a bug that only manifested when handling large numbers of player requests at the same time? We also needed to make sure that we weren’t wasting money by overprovisioning too many instances of services that didn’t need it.
Microservice Testing
Each of our microservices has its own tests to validate the correctness of its functionality. But because player actions can require complex chains of calls between services, testing each service by itself in a vacuum isn’t enough to prove that the platform as a whole can handle the load generated by all the various types of player requests. The only way to know for sure that the platform can handle load from real players is to test it holistically with real player requests. And since it was infeasible to get millions of human players to test our still in-development game, we decided to do the next best thing: Simulate virtual players that would mimic the behaviors of actual players.
Diving Into Load Testing
When VALORANT first entered production, we had only tested with about 100 players simultaneously. Based on stats from League of Legends, optimistic estimates from our publishing team, and our future plans to expand into many regions, we decided that we wanted to make sure we could support at least two million concurrent players on each shard.
Running two million instances of the actual VALORANT client that real players use wasn’t a feasible solution. Even if we disabled all graphical rendering, the overhead of creating this many processes was still excessive. We also wanted to avoid cluttering the client with all the extra code needed to run simulated automated tests. To maximize performance and ease of maintenance, we instead created a simulated mock client called the load test harness, specifically designed for simulating large numbers of players.
Load Test Harness
The load test harness needed to make all the same requests to the VALORANT platform that a real player would. But it didn’t need to simulate any of the game logic or rendering, since we already had the game server load test to validate those pieces. The need to efficiently simulate large numbers of concurrent network requests was the key requirement that informed our technical decisions when designing the load test harness.
Writing in Go
We chose to write the harness in Go for a few reasons. First, its concurrency model allows for large numbers of routines to run concurrently and efficiently on a small number of threads, letting us simplify implementation of player behaviors by running parallel routines for every simulated player. Second, Go’s network I/O model that automatically handles blocking network calls using asynchronous ones under the hood allows us to easily run a large number of concurrent blocking http requests on a limited number of threads. And finally, Go is a widely supported language at Riot that our team has expertise in. In fact, almost all of the services composing the VALORANT platform are written in Go for these same reasons.
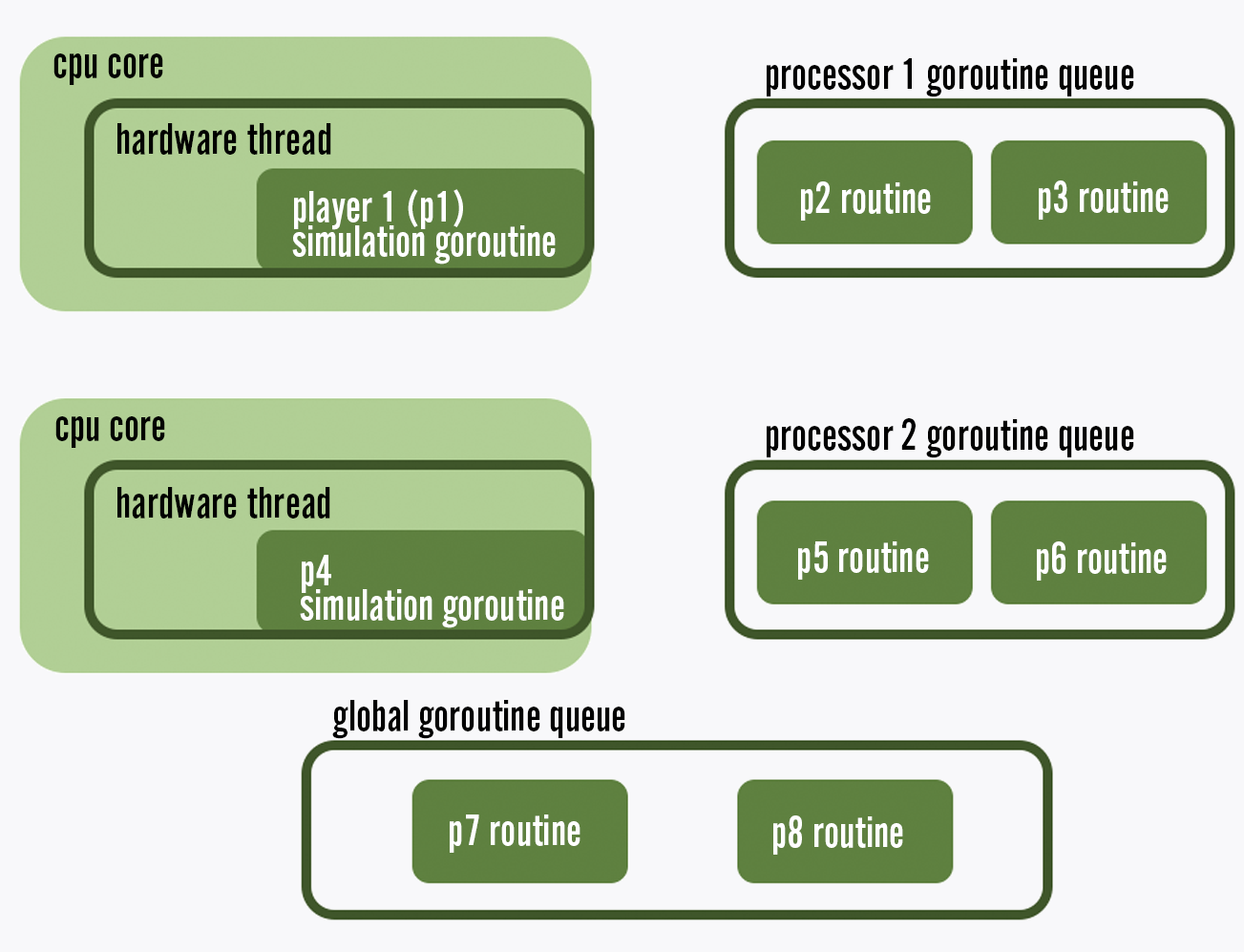
Go's scheduler distributes lightweight routines across a smaller number of hardware threads to reduce overhead
Harness Components
There are three main components to the load test harness: a simulated player, a scenario, and a player pool. Let’s take a look at how each of these work.
The first component of our harness is a simulated player. This simulated player aims to mimic the load of a single real VALORANT client as closely as possible. The player runs the same background polling loops that a regular client would run. Some examples of this background polling include login token refreshing, dynamic configuration polling, and matchmaking queue configuration polling. The player also includes helper functions to run discrete operations that might be performed by a real player, such as buying from the store, equipping a gun skin, joining a party, queueing for a match, and selecting an Agent.
The second component of the harness is a scenario. A scenario defines a set of actions commonly performed by players in sequence. For example, the MatchmakingScenario contains logic instructing a simulated player to queue for a match, join an Agent selection lobby when the queue pops, select an available Agent, lock in the Agent, and connect to the game server when it’s provisioned. The StorePurchase scenario fetches the store catalog and then purchases an available offer. The LoadoutEdit scenario equips some gun skins.
The third key component of the harness is the player pool. The pool creates new player objects at a configurable rate, meant to approximate the login rate of real players. Logged in players are added to a pool of idle players. Idle players are pulled out of the pool at a configurable rate and assigned to perform scenarios. Once a player finishes its assigned scenario, it returns itself to the idle pool. Before launch, we used data from League of Legends to estimate how frequently we expected players to perform operations like queueing for matches and buying content, and we configured our player pool to assign these operations to idle players at that same rate.
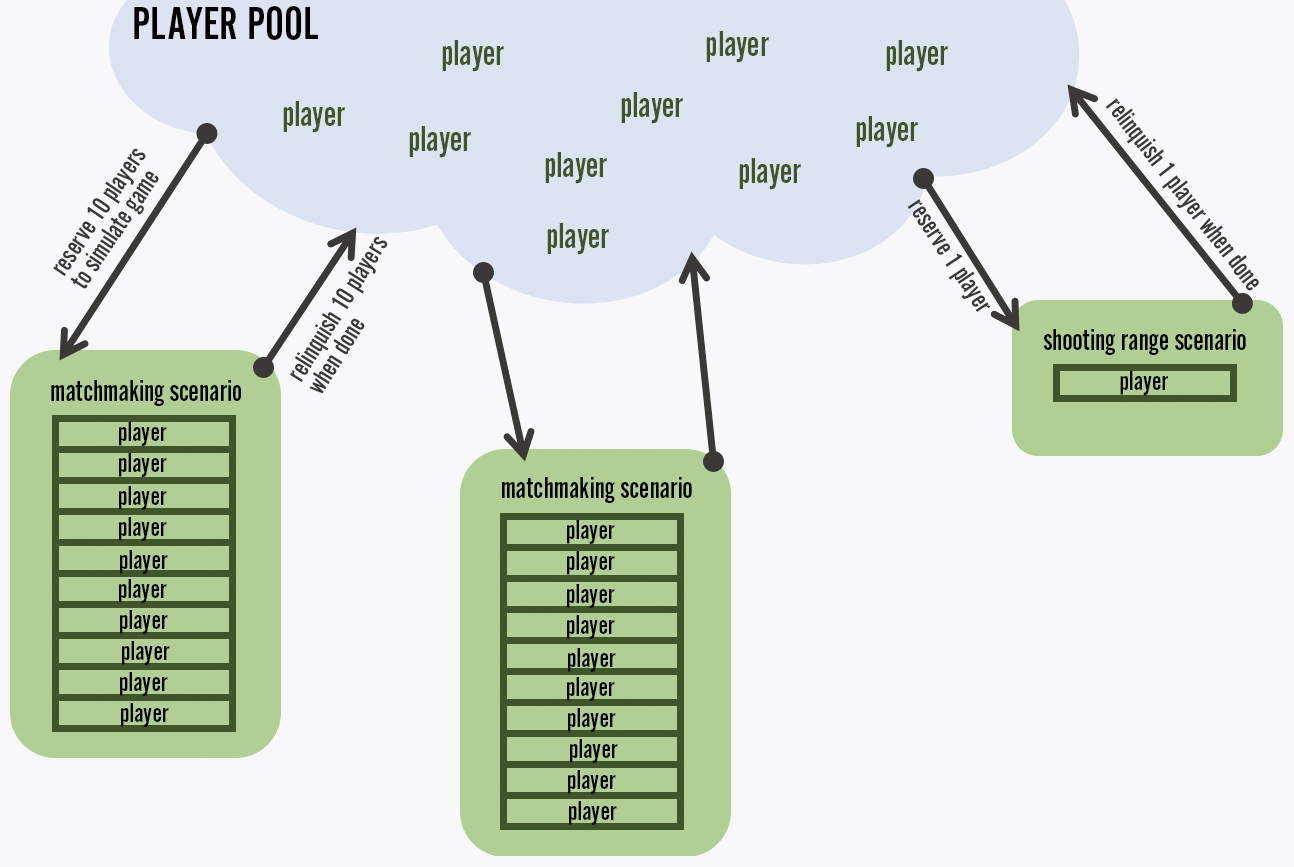
Each concurrently running scenario reserves a number of players from the pool depending on the scenario type and configuration
Prepping for Tests
Our first load tests involved just a single harness. We deployed one instance of the harness and ramped up the number of players to see how many we could simulate. After some careful optimizing and tweaking, we found that we could simulate 10,000 players on one harness process running on four physical CPUs. To simulate two million players, we would need 200 harness processes. We asked Riot’s Infrastructure Platform team to provision a compute cluster that could handle this for us. With Amazon AWS, they deployed a new instance of the Riot Container Engine, a piece of Riot tech that uses Apache Mesos to schedule Docker containers on top of heavy-duty Amazon EC2 compute nodes. Thanks to this cluster, we were able to provision 200 Docker containers of our harness, allowing us to test at the concurrency numbers we were looking for.
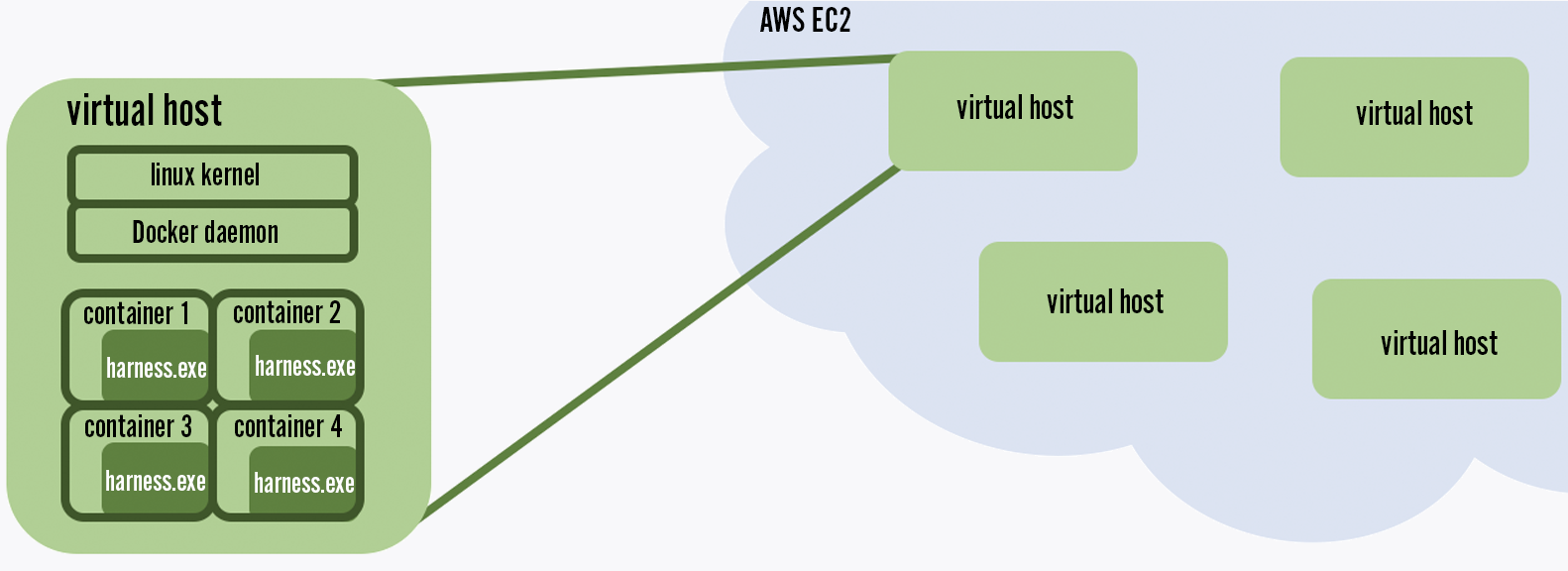
Our load test environment uses Amazon AWS, Riot Container Engine, and Docker to deploy a large number of load test harness processes into the cloud
Simulating Game Servers
Before we could run a full-scale load test with multiple harnesses, there was one final piece we needed to put in place - the game servers.
We had already set up a test environment including enough instances of our platform services to begin testing against. Our harnesses were ready to simulate two million clients. But actually running two million players’ worth of game servers would prove to be a challenge. Several factors made it impractical for us to use real game servers in our load testing environment.
-
Reimplementing gameplay logic and network protocols in the load test harness to interface with real game servers would be complicated and time consuming.
-
Sending and receiving all that additional network traffic would significantly increase the networking and computing resources needed by the harness, reducing the number of players we could simulate.
-
Deploying that many real game servers would require many thousands of cloud CPUs, which we wanted to avoid having to provision if possible.
So instead, we created a simple mock game server, written in Go, which could emulate the same provisioning process and end-of-game results recording that a real game server could, without any of the actual gameplay logic. Because these mock servers were so lightweight, we could simulate over 500 mock games on a single core. When a party of simulated players requested to start a game on the load test environment, they simply connected to the mock game server and did nothing for a configurable amount of time before ending the game.
In this way, we simulated every part of the game provisioning flow without relying on real game servers.
Building Out & Running The Load Tests
With all these pieces in place, we were ready to run a load test. For our very first load test, we ran one thousand simulated players, recorded all the performance issues we ran into, and set out to address them. Once we resolved those issues and this test passed, we doubled the player count for subsequent tests, and repeated the process of identifying and fixing issues. After enough cycles of doubling our target player count, we eventually reached our two million player goal.
Reaching this goal was a huge accomplishment. It was also a huge relief, since platform scale validation was the final hurdle we had to clear before we could announce our launch. Watching real players get their hands on the game was incredibly exciting - it felt so good to see our work pay off. Our relatively smooth launch day was proof of the quality of the tech we had built.
So how did we get there? Let’s take a look at some of the issues we encountered as we increased our scale targets, how we identified them, and how we addressed them.
Extensive Monitoring
Because simulated players can’t talk or file bug reports, the first step to identifying our scale issues was to set up extensive monitoring, dashboarding, and alerting to let us monitor the health of our platform. Each of our microservices emit metrics events for successes and failures of all operations, runtimes for all operations, CPU and memory levels, and other information. We store all these metrics in New Relic, and use Grafana to create dashboards displaying the data. We also set up New Relic alerting rules that will send us Slack messages if any of our metrics go outside our expected thresholds. For each load test, we counted the test as a pass only if every metric stayed within bounds for the full duration.
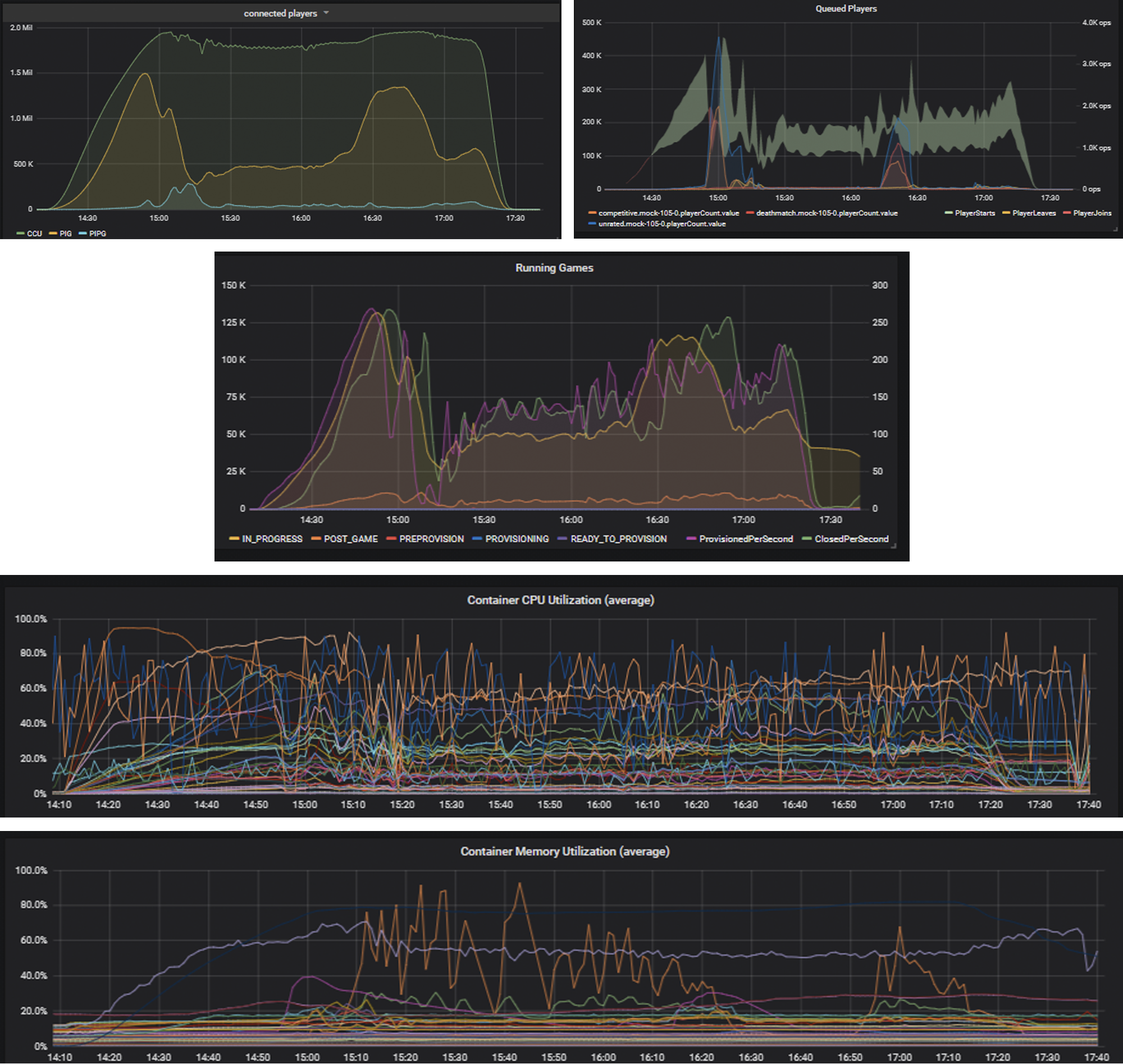
A portion of our dashboards showing the results of a successful two million player, three hour load test
Scalable Databases
One topic that came up early on as a potential performance concern was our need for scalable databases. VALORANT needs to reliably store a lot of information about player accounts, like skill ratings, match histories, loadout selections, and Battlepass progress.
The easiest way to store all this data would be to put all player info into a single database. This would be easy to implement, very safe because updating all the info at once in an all-or-nothing manner makes it easy to avoid data corruption, and scalable up to a point by just upgrading to bigger and better database server hardware when available. Unfortunately, there’s a limit to how far this strategy can scale. Once you’ve bought the biggest hardware available and it’s still not enough, there are few options left. We decided not to go with a single database because we wanted to make sure we could scale horizontally, meaning we could increase our capacity by adding more smaller servers, rather than trying to further upgrade one big one.
Layers of Horizontal Scaling
The first part of our strategy for horizontal scaling is to split a player’s data such that each piece of data was owned by a single service. For example, the match history service saves the data for a player’s match history, and only that data. The loadouts for that player are stored separately in another database, owned by the loadout service. Spreading the data out like this gives each service the opportunity to scale up its database independently. It also reduces the impact of issues by isolating data owned by each service; an issue with the store database may slow down the store, but won’t affect match history performance.
Doing things this way does come at a cost. Because data isn’t collocated, we can no longer rely on atomic transactions to update multiple pieces of data at once. Safely updating each of these multiple data sets in a single operation requires ledgers for in-progress operations, idempotence to retry operations on failure, intermediate lock states, and other such complexities. But the added complexity is worth it to allow us to scale further.
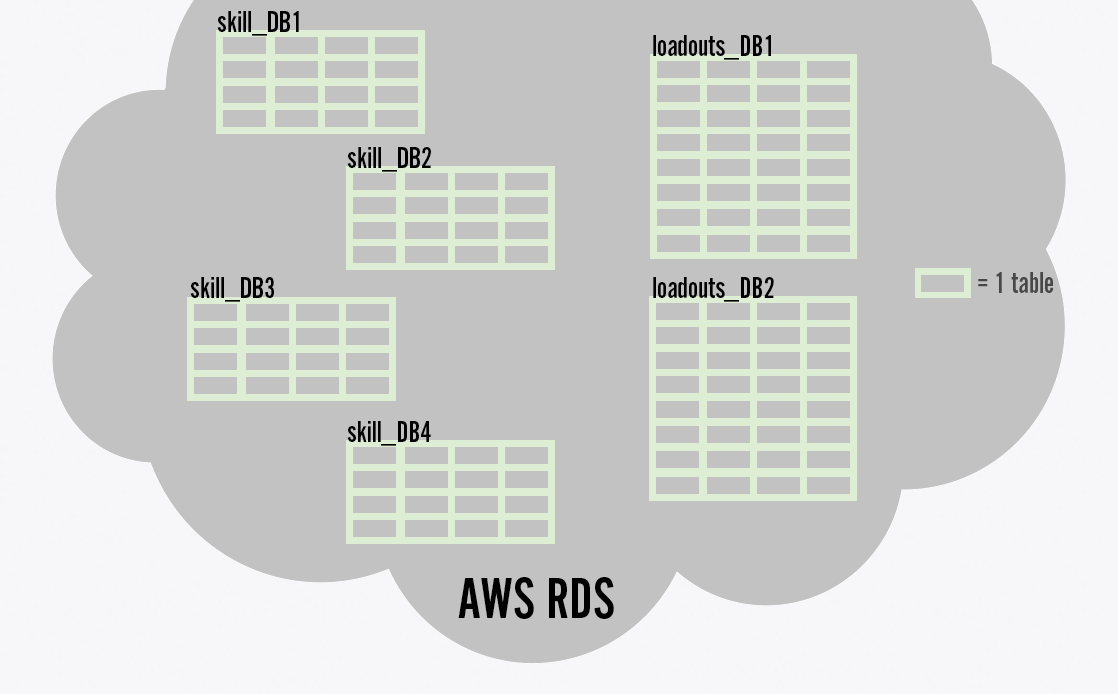
Player data is split across multiple tables in multiple databases to allow for horizontal scaling.
For extremely high numbers of players, even splitting data by the service type that owns it isn’t enough to ensure horizontal scaling. When an individual service can’t performantly handle saving the data for all of its players in a single database, we split the data again, such that each individual database needs to handle only a segment of players. Each VALORANT player has a unique ID, so in the simplest case, we can reduce our database load by half by storing odd-numbered players on one database, and even-numbered players on a second database. In practice, we ended up segmenting players into one of 64 tables by hashing each player’s ID and using the modulo of that hash to determine their table index. We don’t need nearly 64 databases per service, but by segmenting players into 64 tables ahead of time, it’s very easy for us to horizontally scale by just adding more databases and moving tables from one database to another. For example, we can again halve our database load by switching from storing 32 tables on each of two databases, to 16 tables on each of four databases.
Load Balancing Across Service Instances
Splitting load by segmenting players by ID is a strategy we repeated again for load balancing across service instances. VALORANT microservices are stateless, meaning that any instance of a service can handle a request from any player. This is a useful property, as it allows us to load balance incoming requests by assigning them to services round-robin. It also lets our services run without needing large amounts of memory.
One challenge, though, is how to handle player processing that doesn’t originate from an explicit request from a client. As an example, our session service needs to change a player’s state to offline if that player suddenly stopped sending heartbeats without explicitly disconnecting, perhaps because they crashed or lost power. Which session service instance should measure the duration of non-responsiveness for each player and change their state to offline when that duration reaches a threshold? We answer this by assigning players into one of 256 shares based on the modulo of their player ID hash. We store a list of the 256 shares in a Redis shared memory cache. As services start up, they will check this list, and claim a portion of the shares by registering their own instance ID in the list. When new service instances are deployed to further spread out load, the new instances will steal shares from existing instances until each instance owns a roughly equal number of shares. Each service will then handle the background processing for all the players in the shares that it owns.
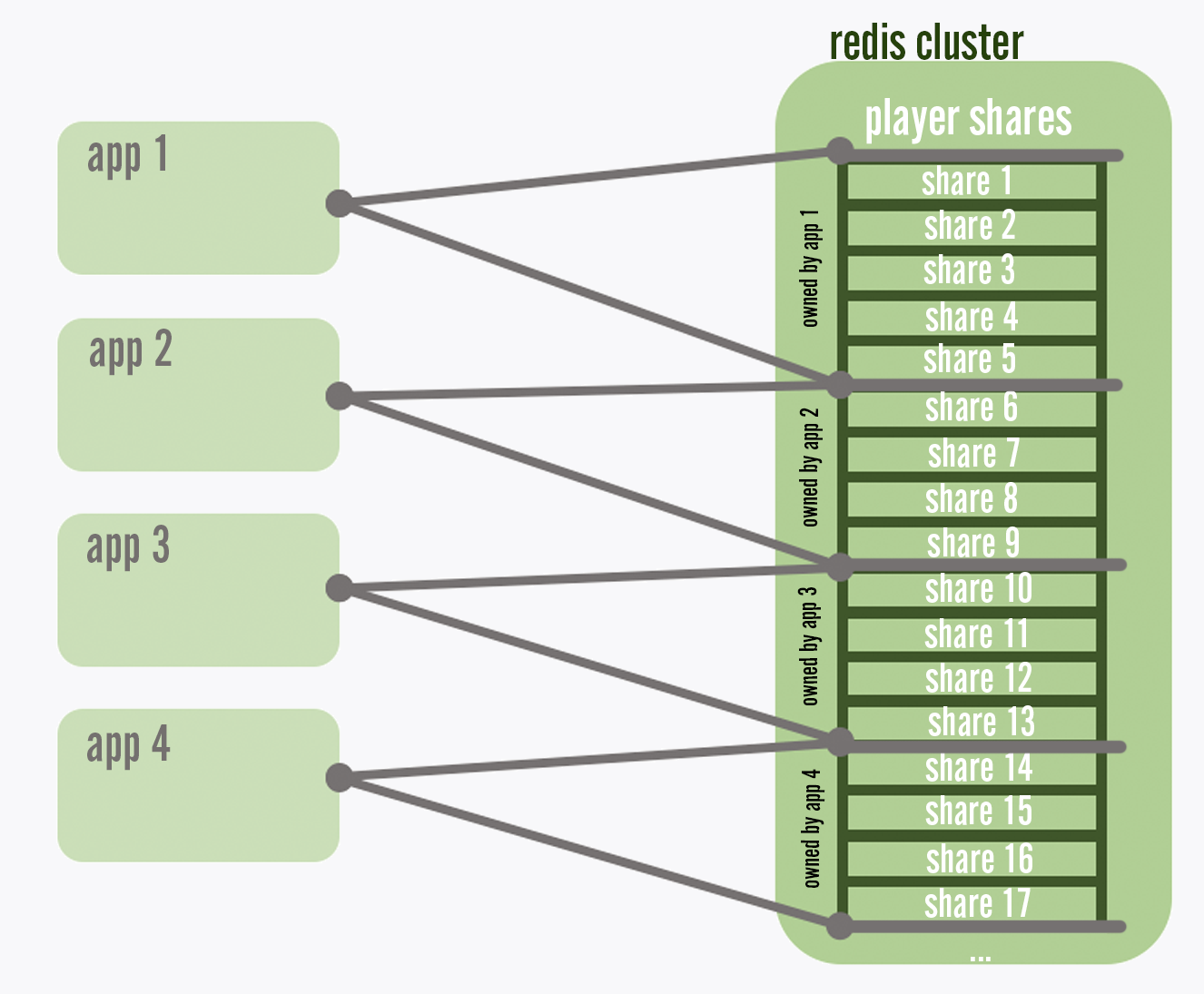
Each app reserves its own segment of players from a central list so that each player's background processing happens exactly once
Caching
Another important technique we applied to improve our scalability was caching. We cache the result of certain computations in several places to avoid having to repeat them when we know the result will be the same each time.
There were several places where we introduced caches. Each service that frequently returns the same results has a caching layer in its http response handler, which can save the result of calls and return the previously saved result instead of recomputing it. Additionally, services that call other services to fetch data include a cache on the calling end. If a service needed to query the same data twice, it checks its own cache of previously returned results and uses those instead if available. We can even cache at our network edge before requests enter our platform at all. Before reaching our platform, requests from clients first flow through Cloudflare, and then through an nginx server for load balancing. We can optionally enable caching at these layers to reduce the number of requests that reach our platform at all. In practice, we found few cases where we needed to rely on network edge caching. In most cases we were able to hit our performance goals with our own in-app caching alone, making the logic for cache eviction much simpler.
Looking Back
It took us many months to scale the platform up to our desired levels, and we cut it close on our deadline. We had less than two weeks to go until launch when we hit our first successful 2-million CCU loadtest. Nonetheless, the load test results gave us the confidence we needed to ship our game. We scaled up our live shards to the same presets that we had landed on in the load test environment and prepared for launch day.
So, how did we do? It turns out, pretty well. Aside from a minor issue with parties and matchmaking that required a small code fix to address, VALORANT’s launch day went smoothly. Our hard work paid off!
Making a scalable platform takes more than just one team. Reaching our scalability goals was only achieved thanks to every single feature team on VALORANT contributing to making their microservices performant. The biggest value of our load tests and dashboards was that they empowered all our devs to make informed decisions about how to build their own services.
I want to also thank all the central teams at Riot who maintain the technology and infrastructure that we use to deploy our services. VALORANT couldn’t have launched without support from them.
Thanks for reading!