Running Online Services at Riot: Part II
Our names are Kyle Allan and Carl Quinn, and we work on the infrastructure team here at Riot. Welcome to the second blog post in our multi-part series describing in detail how we deploy and operate backend features around the globe. In this post, we are going to dive into the first core component of the deployment ecosystem: container scheduling.
In Jonathan’s first post of this series, he discussed Riot’s history of deployment and the struggles we faced. In particular, he outlined how the difficulties we experience deploying software have grown - especially due to “manual server provisioning per-application” as we’ve added more and more infrastructure to support League of Legends. Then, along came a tool called Docker that altered our approach to server deployments (among other things) - the outcome of our iteration became Admiral, our internal tool for cluster scheduling and management. (We found out just yesterday that VMware has similar software with the same name - great minds think alike.)
It’s important to note that this journey with application deployment is far from over - it’s constantly evolving and we’re preparing for the next leg (potentially an adoption of DC/OS, discussed later). This article presents the story of how arrived at this point and why we’ve made the decisions we have - hopefully so others can learn from them as well.
What is Scheduling and Why
When Docker was released and Linux containerization became a more widely understood technology, we recognized that we could benefit by moving towards a containerized implementation of infrastructure. Docker container images provide an immutable, deployable artifact that can be built once and deployed in dev, test, and production. Additionally, dependencies of images running in production are guaranteed to be exactly as they were during testing.
For the purposes of this article, another benefit is especially important: Docker allows for the decoupling of the unit of deployment (containers) from the unit of compute (hosts) through the leveraging of a scheduler to allocate containers to hosts (hopefully in an intelligent manner). This eliminates the coupling between server and application - a given container can be run on any number of possible servers.
With our backend services packaged in Docker images, and deployable at any time and scale to a fleet of servers, we should be able to adapt to change quickly. We can add new player features, scale out features that are getting heavy traffic, and rapidly roll out updates and fixes. When we consider deploying services inside containers to production, there are three major problems we need to solve for, each of which we’ll address in this article:
-
Given a cluster of hosts, how is a specific set of them chosen to receive a set of containers?
-
How are these containers actually started on a remote host?
-
What happens when containers die?
The answer to these three questions is that we need a scheduler - a service that operates at the cluster layer and executes our container strategy. The scheduler is a key component in maintaining the cluster, ensuring that containers are running in the right places, and restarting them when they die. For example, we might want to launch a service such as Hextech Crafting, that needs six container instances to handle its load. The scheduler is responsible for finding hosts with enough memory and CPU resources to support these containers and doing whatever operations are needed to get those containers running. If one of those servers ever goes down, the scheduler is also responsible for finding a replacement host for the affected containers.
When we decided to leverage a scheduler we wanted the ability to prototype quickly, in order to understand if containerized services would work well for us in production. Additionally, we needed to ensure that existing open-source options would work in our environments or that the maintainers would be willing to accept our adaptations.
Why Write Our Own
Before we began writing the scheduler that became Admiral, we surveyed the landscape of existing cluster managers and schedulers. Who was scheduling containers across clusters of Docker hosts and how were they doing it? Could their technologies solve our problems as well?
We looked at a few projects during our initial research:
-
These technologies were fairly mature and oriented for large scale, but were complicated and tricky to install. This made them hard to experiment with and evaluate.
-
At the time, they had very limited container support, didn't track the rapid evolution of Docker, and didn't play well in the Docker ecosystem.
-
They didn’t support container groups (pods) which we felt we’d need for bundling sidecar containers with many of our services.
LMCTFY => Kubernetes
-
Kubernetes had just evolved from LMCTFY. While it looked promising, it wasn’t clear if its future evolution would match what we needed.
-
Kubernetes didn’t yet have a constraint system that could do container placement like we needed.
-
Fleet was recently open-sourced and not as mature as it is today.
-
Fleet seemed to be more specialized toward the deployment of system services as opposed to general application services.
We also prototyped a small command line tool that spoke to the Docker API over REST, and we successfully demonstrated how we could use this tool to orchestrate deployments. We then decided to move forward with writing our own scheduler. We borrowed some of the best bits of the researched systems, including the core ideas behind Kubernetes’ Pods and Marathon’s constraint system. Our vision was to track the architecture and functionality of these systems, influence them when possible, and eventually try to converge with one of them in the future.
Admiral Overview
We began writing Admiral after creating a foundational deployment JSON-based metadata language called CUDL, or “ClUster Description Language.” This became the language that Admiral spoke in its RESTful API. Two major components of CUDL are:
-
Clusters - a set of docker hosts.
-
Packs - the metadata required to start a set of one or more containers. Similar to a Kubernetes Pod plus Replication Controller.
Clusters and packs have two different aspects: spec and live. Each aspect represents a description of a different phase of the container lifecycle.
Spec, representing the desired state of the element
-
Posted to Admiral from some external source of truth, such as source control
-
Immutable once delivered to Admiral
-
Spec Clusters and Hosts describe the resources available in a cluster
-
Spec packs describe the resources, constraints and metadata required to run a service
Live, representing the realized state of the element
-
Mirrors actual running objects
-
Live Clusters and hosts mirror running Docker daemons
-
Live packs mirror running Docker container groups
-
-
Recoverable by communicating with the Docker daemons
Admiral is written in Go and is compiled and packaged into a Docker container when run in a production datacenter. Admiral has several internal subsystems, most of which are shown in the diagram below.
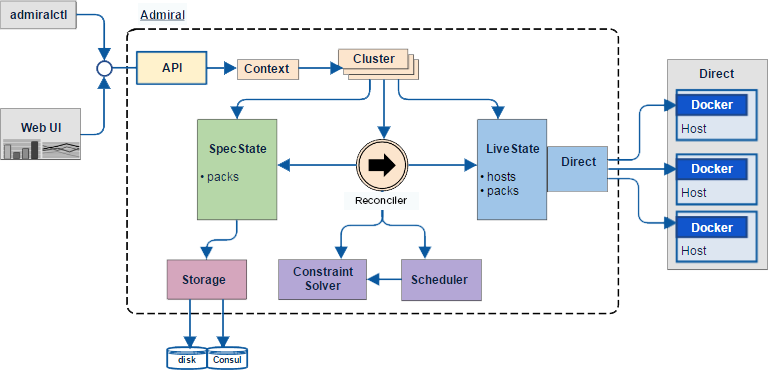
From a user’s perspective, interactions with Admiral take place using its provided admiralctl command-line tool which communicates with Admiral through a REST API. With admiralctl, a user can access all of Admiral’s functionality via standard verbs: POST’ing new spec packs to schedule, DELETE’ing old Packs, and GET’ing current state.
In production, Admiral stores spec state using Hashicorp’s Consul which we regularly backup in case of a catastrophic failure. In the event of a complete data loss, Admiral is also able to partially rebuild its spec state using information from the live state retrieved from the individual Docker daemons.
The reconciler lives at the heart of Admiral and is the key subsystem that drives the scheduling workflow. The reconciler periodically compares the actual live state with the desired spec state and, when there is a discrepancy, schedules the actions required to bring the live state back in line.
The livestate and its driver package support the reconciler by caching live host and container state and providing communication with all of the Docker daemons on the cluster hosts over their REST APIs.
Scheduling In-Depth
Admiral’s reconciler operates on spec packs, effectively transforming them into live packs. When the spec pack is submitted to Admiral, the reconciler acts to create containers and start them using the Docker daemon. It is through this mechanism that the reconciler achieves our first two high-level scheduling goals described earlier. When the reconciler receives a spec pack, it:
-
Evaluates the cluster’s resources and the pack’s constraints, finding an appropriate host(s) for the containers.
-
Knows how to start a container on a remote host using data from the spec.
Let’s walk through the example of starting a container on a Docker host. In this example, I’ll be using my local Docker daemon as the Docker host and interacting with a local instance of the Admiral server.
First, we use the `admiral pack create <cluster name> <pack file>` command to start a pack. This command targets a specific cluster and submits the spec pack JSON to the Admiral server.

You’ll notice that almost immediately after running the command, a container has been started on my machine. This container was started using the parameters in my pack file which is shown here:
{
"name": "dat.blog_scout",
"description": "A pack of the Scout service for usage in our engineering blog post.",
"service": {
"location": "dev.local.test",
"discovery": {},
"appname": "dat.scout"
},
"containers": [
{
"image": "datd/scout",
"version": "1.0.0",
"ports": [{
"internal": 8080,
"external": 8080
}]
}
],
"count": 1
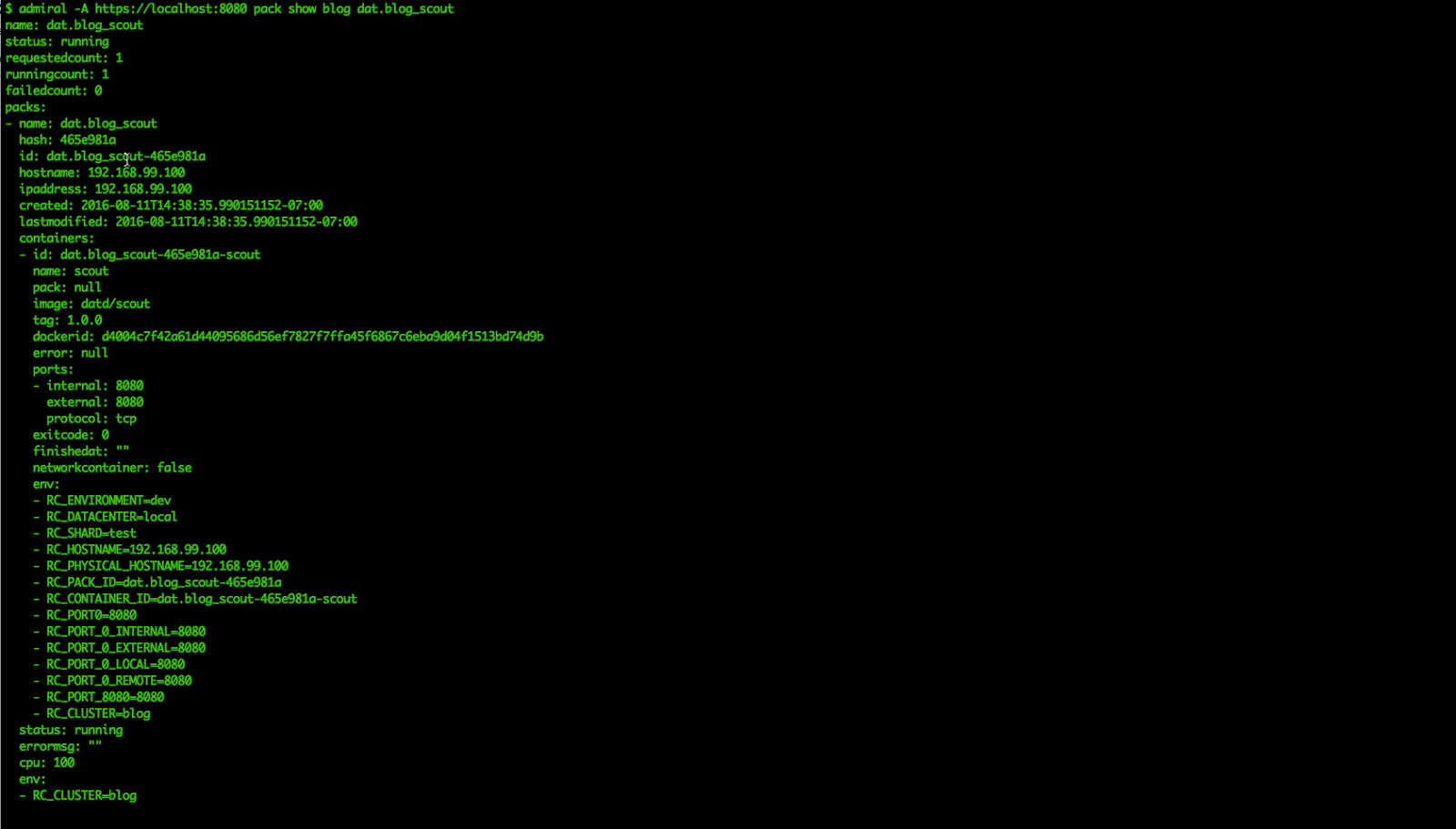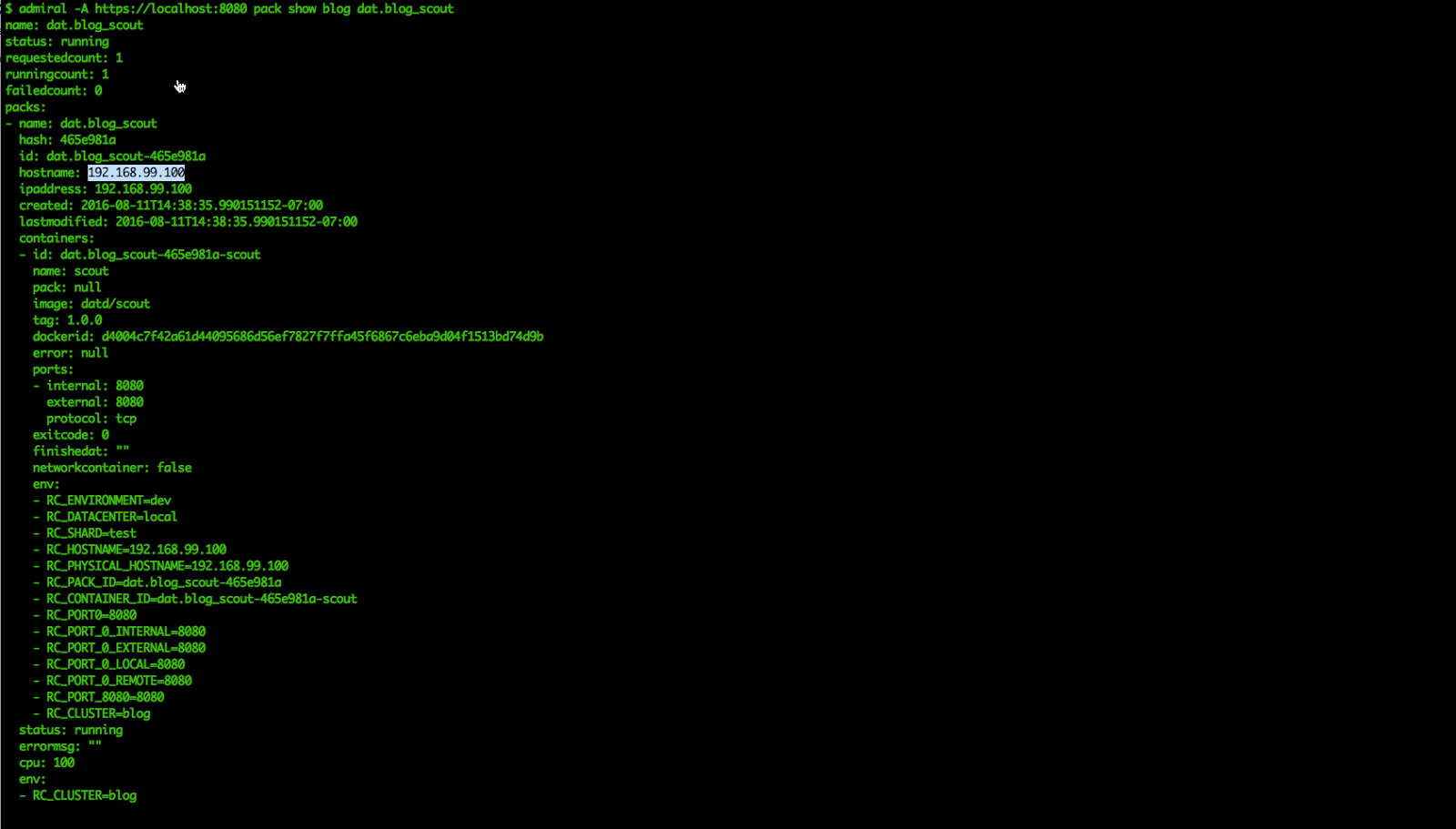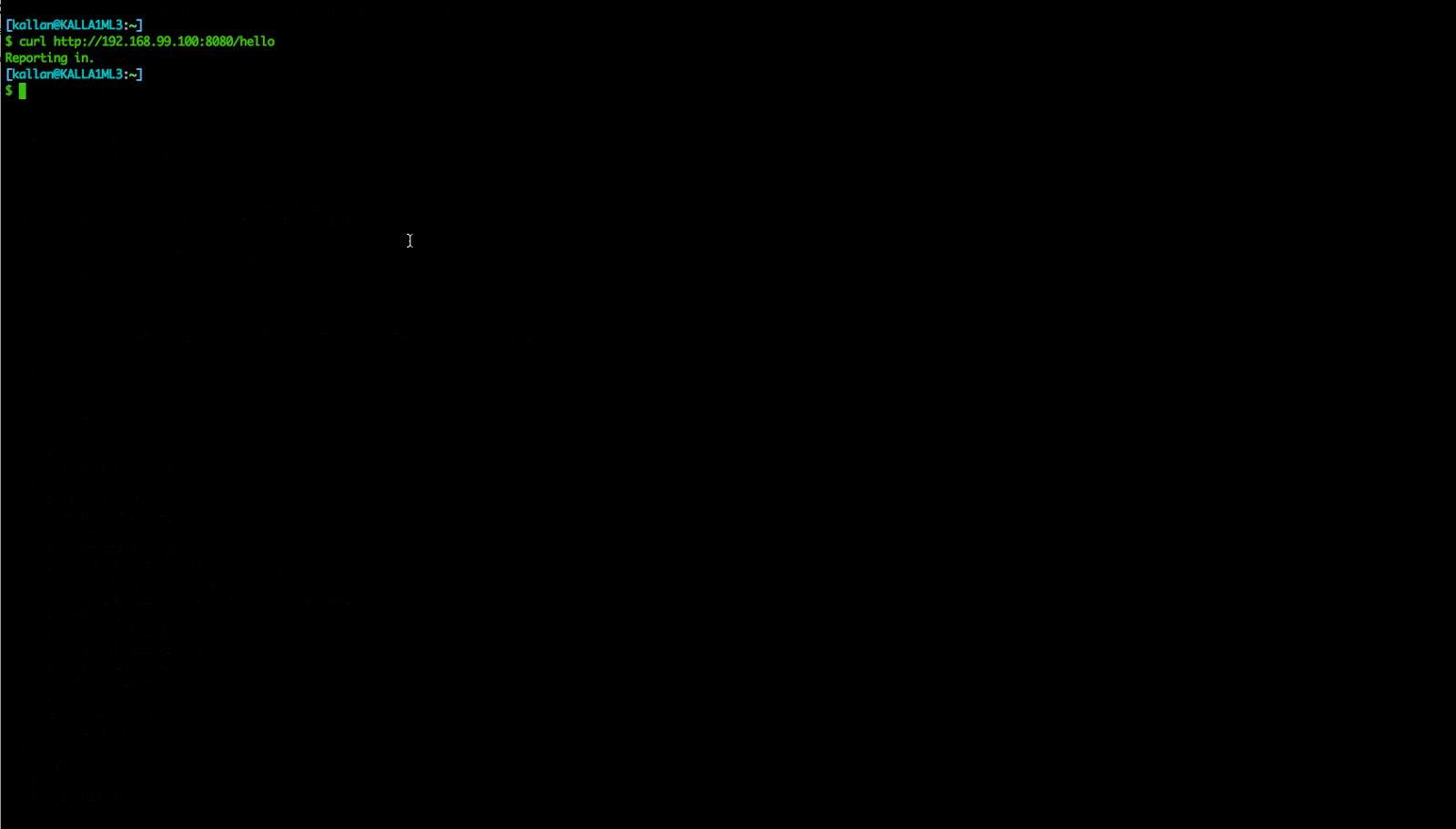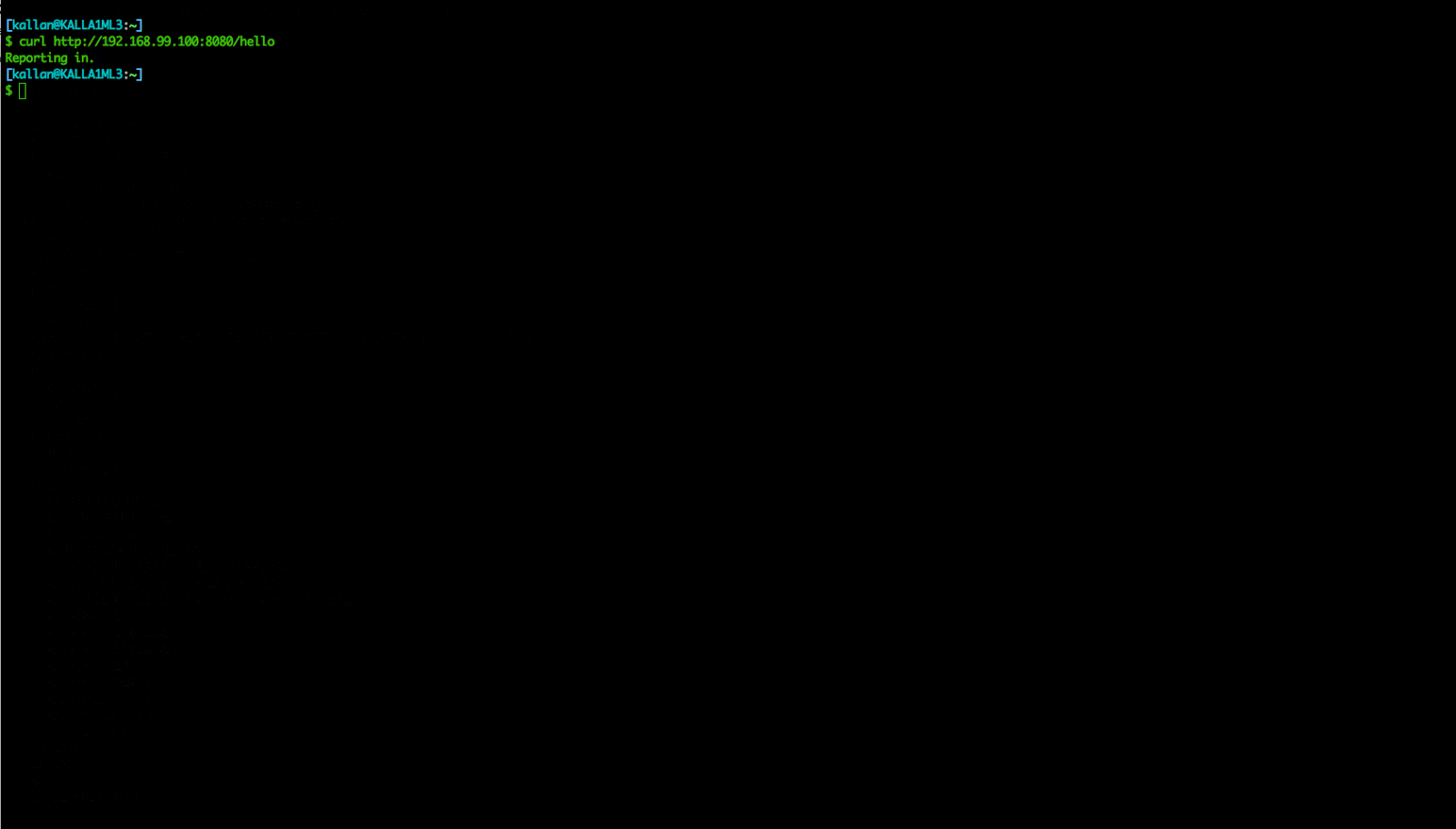
}Next, after we’ve called `admiral pack create` we can use the `show` command to view the live pack created by Admiral. Here, the command is `admiral pack show <cluster name> <pack name>`.

Finally, we can verify that our pack is working by hitting the service within the container. Using the information from the `admiral pack show` command, we can piece together a simple curl to hit our service:
Within Admiral, the reconciler is always running, ensuring our cluster’s live state always matches the desired spec state. This allows us to recover when a container fails and exits due to a crash, or when a whole server becomes unavailable due to hardware failure. The reconciler is working to ensure our states match so players never experience an interruption. This function solves our third and final problem described earlier: when a container unexpectedly exits, we quickly recover and the impact remains minimal.
Below, I show the existing container started via the `admiral pack create` command. I then proceed to kill the container, stopping its execution. Within a few seconds, a new container (with a different ID) is started by the reconciler as it realizes that the live state does not match our spec state.

Resources and Constraints
To best allocate containers, the scheduler must have insight into the cluster of hosts. There are two key components to solving this problem:
Resources - a representation of a server’s available resources including memory, CPU, I/O, and networking among others.
Constraints - a set of conditions included with a pack that give the scheduler details about restrictions on where the pack can be placed. For example, we might want to place an instance of a pack:
-
On every host in the entire cluster
-
On a specific host named ‘myhost.riotgames.com’
-
In each labeled zone in the cluster
By defining resources on our hosts, we give the scheduler flexibility in deciding where to place containers. By defining constraints on our packs, we limit the scheduler’s choices so that we can enforce specific patterns into our cluster.
Conclusion
For Riot, Admiral is a crucial piece of our continuing evolution of deployment technologies. By leveraging the power of Docker and a scheduling system we’re able to deliver backend features to our players much faster than before.
In this article, we examined some of the features of Admiral in-depth and showed how we are scheduling containers across a cluster of machines. As Jonathan mentioned in his first post, the open-source world has moved quickly to a very similar model. Moving forward, we’ll be transitioning work off Admiral and focusing on deploying DC/OS - which has become one of the leading open-source applications for scheduling container workloads.
If you’ve been on a similar journey, or feel like you have something to add to the conversation, we’d love to hear from you in the comments below.
For more information, check out the rest of this series:
Part I: Introduction
Part II: Scheduling (this article)
Part III: Networking with OpenContrail and Docker
Part III: Part Deux: Networking with OpenContrail and Docker
Part IV: Dynamic Applications - Micro-Service Ecosystem
Part V: Dynamic Applications - Developer Ecosystem
Part VI: Products, Not Services