Technology Interns in 2020: General Game Tech & Tooling/Infrastructure
The Riot internship program exists to help players drive their professional and personal development. This is the second post in the 2020 intern series - be sure to check out the first post as well.
Thanks to all our interns for their hard work and excellent projects this summer!
General Game Tech
Sylvia Hua
Role: Software Engineer
Team: Commerce
Hi! My name is Sylvia “Hide on Peanut” Hua. I study computer science at Rensselaer Polytechnic Institute, and this summer I’m on the Commerce team as a software engineer intern. The Commerce team builds the tools that allow players to buy virtual currency like RP, Coins, and VALORANT Points.
This summer, I focused on UI & UX improvements. The main goal was to keep players interested during the purchase flow, and set up a clear visual language. This is vital so purchase decisions are simple enough that players know exactly what they’re buying. My project polished the RP purchase page while integrating with APIs from other teams in the backend.
Clarifying Purchasing Amounts
One interesting change I made is to reinforce the player’s perception of how much they will gain when they make the payments. In the past, we only displayed the virtual currency amount that players were purchasing, along with the total price. After the improvement, players will have a more straightforward view of how much they’re gaining.
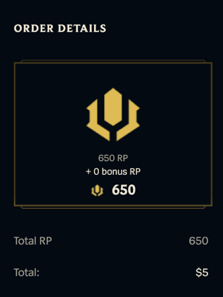
Previous iteration
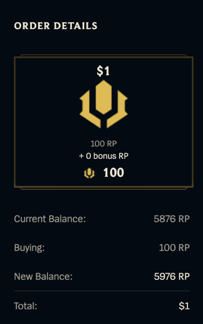
Current iteration
To implement this feature, I first needed to figure out where virtual currency data was stored. The Content Access Platform manages this, and provided me with an API for access. Then I just needed to build up an API call in our backend, pass the value to the frontend, and render these elements in the purchase detail page. The challenging part was that for each game and shard, we needed to call a different URL and use a unique authorization token. As we now have multiple games (and will have more games in the future) this feature needed to be scalable and maintainable. To accomplish this, I used a JSON file to maintain all these properties. The Spring framework can directly map the JSON file to Java objects, simplifying the configuration management. After everything on the backend is set, the frontend retrieves the player’s balance.
Overall, I really had fun at Riot this summer and I enjoyed every minute working with my team. Everyone is super supportive and also very playful. I really enjoyed getting to meet Rioters outside of my team and learning about different kinds of projects. I truly appreciate the opportunity to work at Riot and it definitely made my summer incredible.
Ken Lu
Role: Software Engineer
Team: Content Access Hub
Hello! I’m Ken “Chocoduk” Lu and I study computer science at the University of Michigan. This summer I was a software engineer intern on the Content Access Hub team. This team provides the infrastructure behind players’ abilities to purchase items like skins, champions, and battlepasses.
The Content Access Hub owns the backend behind how players make purchases and refunds with in-game currency to gain access to content within the game. A central aspect of CAH is building game-agnostic tools for other development teams like APIs or supporting services. My project focused on simulating a purchase and refund from a player’s perspective through the use of a scripted monitor running at a set interval and reporting on failures as well as collecting analytics for the monitor like average duration.
The main technology utilized in my project is a service called New Relic Synthetics, which is a platform for synthetic monitoring of a service. Synthetic monitoring is a form of testing where developers simulate a user’s actions in real-time to gain a more accurate understanding of metrics like availability and latency, and in the case of failures, be able to respond faster. For my project, I created a script to test the functionality of CAH’s Orders and Refunds API from the perspective of a player account and created the corresponding monitor on New Relic. New Relic also stores data on each monitor run which I queried to obtain statistics on the success rate and latency percentiles to send to our internal analytics platform.
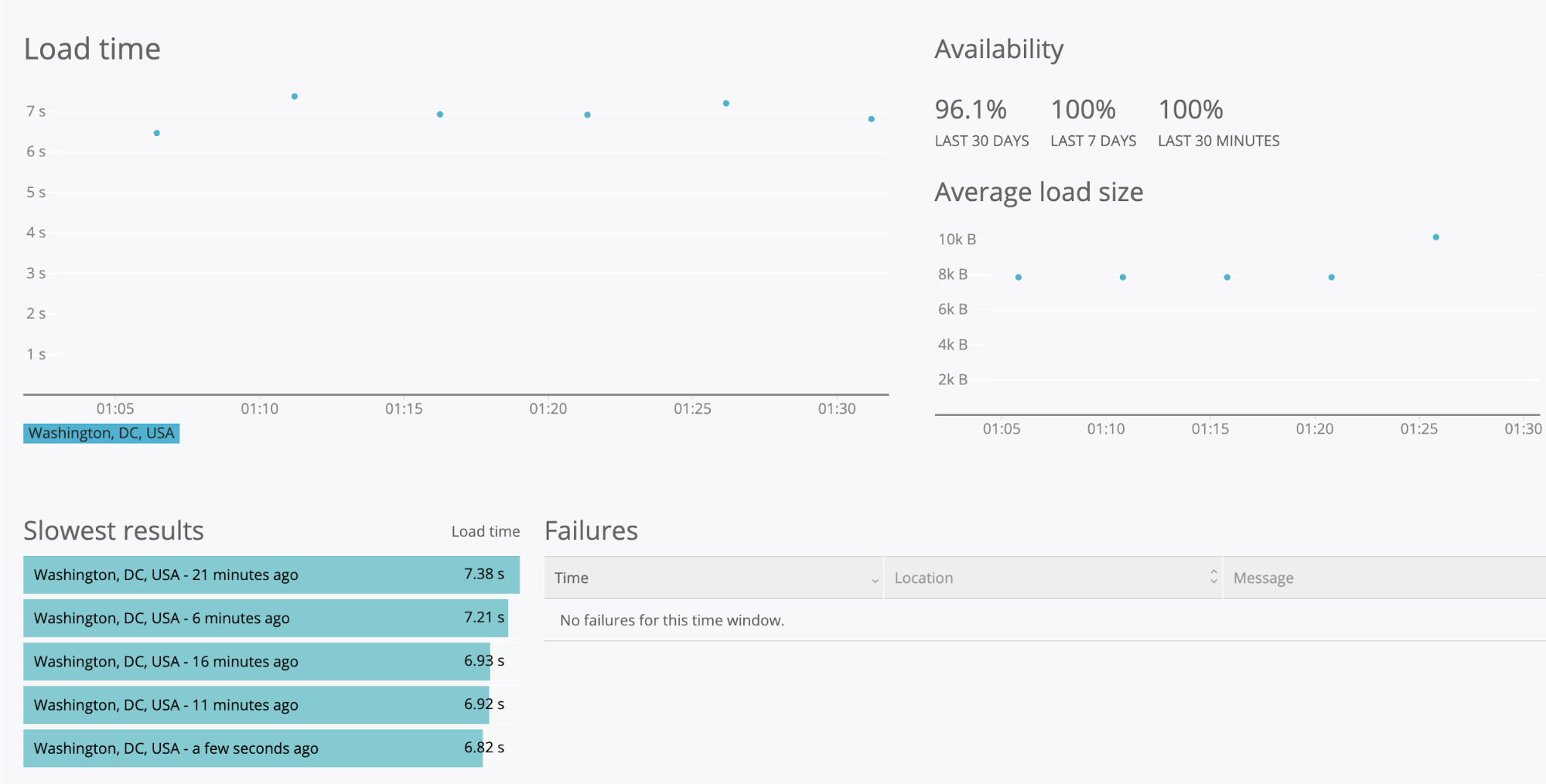
The New Relic interface with availability statistics and durations
The main challenge in my project was refactoring my script to incorporate RMS. RMS, the Riot Messaging Service, is how player clients receive updates on the status of their transactions. Previously, I had only been polling at a set interval for updates on the status of a given order/refund request, which is a less accurate representation of the real-state. To successfully utilize RMS, I had to acquire an RSO token and open a socket to listen to messages asynchronously, which added a lot of complications with callbacks and javascript promises, especially since I wanted to incorporate the old polling method as a backup in the case where RMS took too long or didn’t respond. In addition, because Javascript is single-threaded but functions can be asynchronous, it was challenging figuring out a way to correctly layer the order in which I wanted certain checks and further calls to be made.
Another aspect of the project which was really interesting was the use of Terraform, which is a way to manage infrastructure through code as its own scripting language. It’s a really interesting way to declaratively set-up and edit infrastructure like the New Relic monitors, Slack channels, etc. through the command line and a few files. I also managed to deploy the Terraform scripts to AWS, allowing other team members to share the infrastructure state and make changes to it remotely.
One final aspect of the project that was really interesting was figuring out how to handle analytics reporting through the use of New Relic Query Language, a custom query language similar to SQL. It was a challenge planning how queried data could be separated into different facets to report different buckets of data based on the region, server, or game. In addition, I learned to add custom data fields through New Relic that I could query later to report data that the default fields couldn’t provide.
Overall, I really enjoyed my time here working with my team and my project. The work was really fulfilling and I felt I got a lot of experience with working on a team and the project cycle as well as growing a lot technically. My team has been super supportive in all my efforts and always open to questions. Finally, the intern events were really fun and I loved talking with other interns and playing games together. It was an awesome experience all around!
Chris Benson
Role: Software Engineer
Team: AI Accelerator
My name is Christopher “Miss Militia” Benson and I’m a master’s student at Carnegie Mellon University. Over this summer I worked primarily as a research intern for the AI Accelerator team, which is an R&D team focused on cutting-edge computer science.
The AI Accelerator team is empowered to take on more high risk, high-impact projects that could take multiple years to bear fruit. Our work spans a wide range of technologies from AI to procedural generation to GANs, but recently has been particularly focused on using reinforcement learning (RL) to create agents that play Riot’s games at a high level. From generating data on unreleased patches and balance changes to catching bugs, these RL agents provide valuable insights about our games which can supplement playtesting data, which is slow and expensive to procure.
My project was purely R&D as it was focused on a non-Riot game. I worked on developing deep RL agents to play a game called NetHack, which was recently released on the popular RL research platform, Gym, by the Facebook AI Research (FAIR) lab. Nethack is an extremely difficult single-player, procedurally generated, synchronous, stochastic roguelike game played in the terminal with ASCII art.
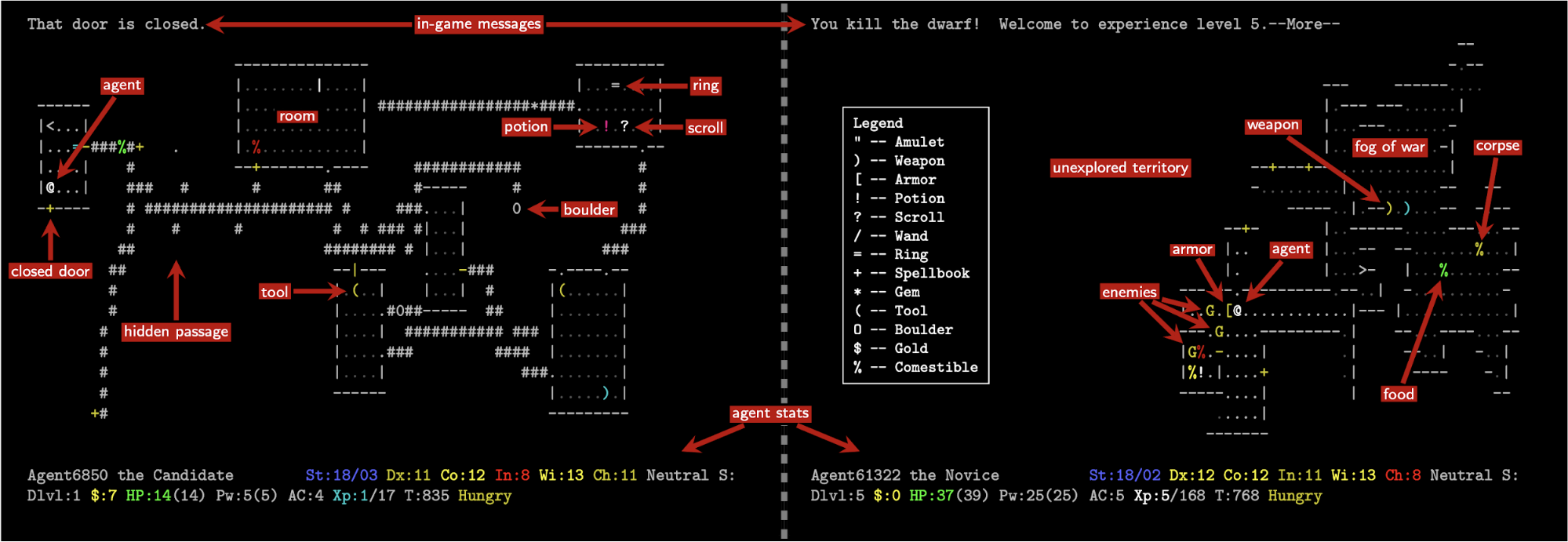
Example NetHack Gameplay, source https://arxiv.org/pdf/2006.13760.pdf
My work also focused on eventually incorporating outside knowledge corpora, such as the extensive NetHack Wiki, into the RL agents through natural language processing (NLP).
We trained a model using the architecture shown below, which incorporates features from the players stats, the entire visible level floor, and the immediate area surrounding the agent. We later added in the ingame message as a feature, with plans to incorporate more advanced NLP techniques as future work for the project. The features combine and are fed through an LSTM cell, which helps the agent preserve memory from state to state. The outputs of the LSTM are then fed through a final multilayer perceptron (MLP) layer to convert to the action space in order to select the next move. 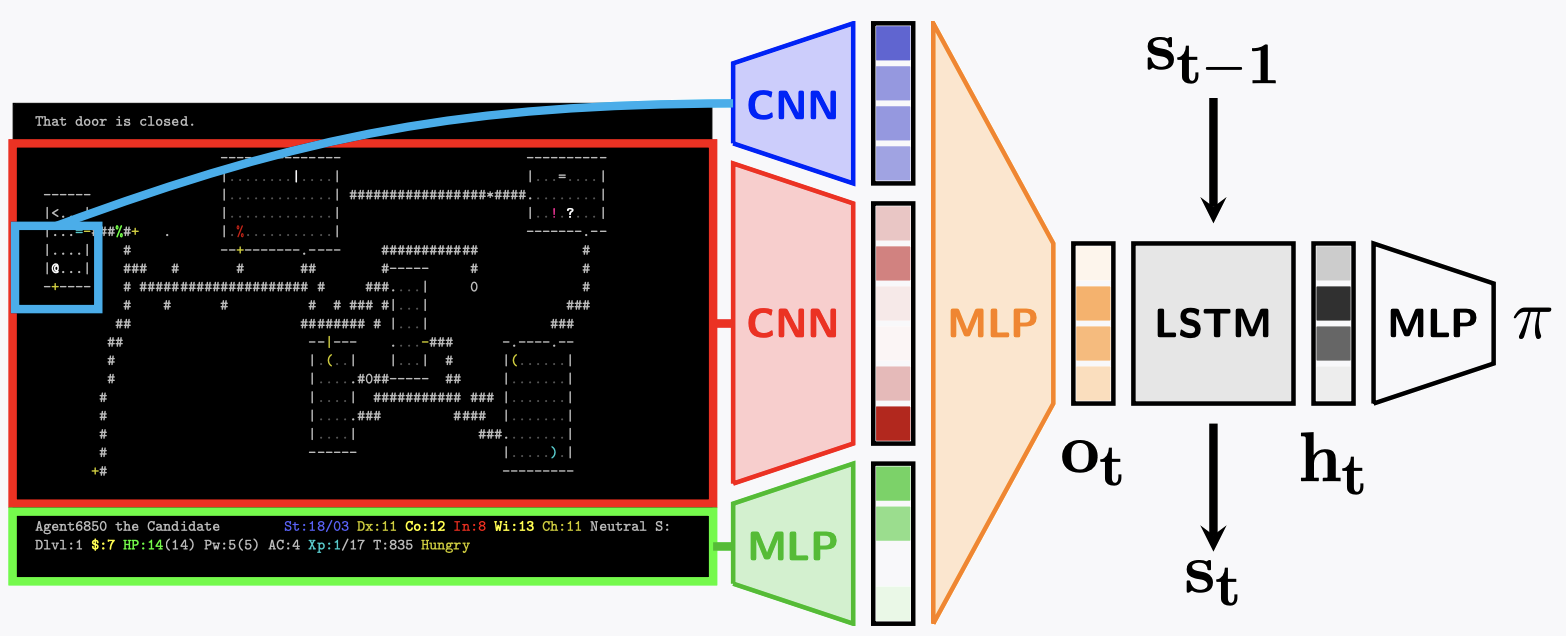
Initial Baseline Model, source https://arxiv.org/pdf/2006.13760.pdf
The model was built using Tensorflow, and trained on AWS using an inhouse distributed RL platform which leverages Kubernetes. We set up a system so that the reward function for the agent can be easily customized to promote different ingame behaviors, such as collecting gold, exploring deeper floors, eating food, etc. Furthermore, we set up templates so that additional reward signals can be added in the future to encourage even more complex gameplay.
As others have mentioned, while it was unfortunate that the internship was made remote due to COVID, I nevertheless had a wonderful experience working at Riot and learned so much. I came into the summer with very little RL experience, but my team did a fantastic job bringing me up to speed and really made me feel like a part of Riot from day one.
Tooling/Infrastructure
Justin Wang
Role: Software Engineer
Team: Social Infrastructure
Hi! My name is Justin Wang, and I’m currently a student at UC Berkeley. This summer, I was a software engineer intern on the Social Infrastructure team. Social Infrastructure (SI) is responsible for many of the services for social systems, like friends lists, text chat, voice chat, etc. SI also is responsible for building out new services to address the needs of existing and new games alike.
SI’s primary language of choice is Erlang, a relatively niche functional programming language lauded for its emphasis on scalability and reliability. Most people, myself before this internship included, are completely unfamiliar with Erlang, a condition that made my experience this summer all the more gratifying and learning-intensive. Instead of having a traditional self-contained intern project, I was able to integrate directly with the team and realize solutions for both long standing and novel problems, some of which I’ll describe below.
Internal Social Graph
One of the problems I worked on was moving changes in Riot’s internal social graph of players to an internal analytics platform. This was a great project because - while the changes made to the codebase were auxiliary and toggleable - it gave me the opportunity to become familiar with the modus operandi of both SI and Riot engineering, from the design of the social graph service to how live services are discovered and configured. In addition to writing code, I was also able to experience the deployment process, and moved my changes through internal testing environments into production, where it currently operates today. I also built a command line tool in Go for interacting with the aforementioned social graph service. While initially created to simplify testing-related HTTP requests, this tool has also enabled player support to resolve many impacted friends and block lists.
Push Notifications
I also contributed to a new push notifications service created in response to Riot’s increasing mobile footprint. This service aims to maximize Riot’s ability to utilize push notifications. The combination of the popularity of mobile gaming and the player registration process presented a certain problem: users are (re)registered upon application installation, so reinstallations will create redundant entries for the same user. A simple fix would be to cycle out old entries upon a new registration, but then over-querying the log of users would result in thrashing the underlying database. The solution was that each new registering user would be added to a queue with certain configurable probability. Queue entries were queried for registrations exceeding a configurable upper limit, and those entries were deleted. The emphasis on configurability is to allow for adjustments once the service is live: if it’s observed that few users ever reach the upper limit, the probability of being added to the queue can be lowered to reduce resource consumption, and if multi-device users seem to be the norm, the upper limit can be adjusted to avoid deleting valid entries. In general, I’m very grateful to have worked on live systems with considerations like this, as these are problems that hardly appear elsewhere.
Conclusion
Outside of work, we interns participated in several events, and the ones I enjoyed the most were Lunch and Learns, where we were able to learn about several Riot initiatives from those that had made them a reality. It was especially fascinating to reconcile our understanding of these initiatives as players and fans to what really happened behind the scenes. Away from intern activities, I am also appreciative for Riot’s culture of open dialogue, which I was able to experience both in the steady communications between leadership and other Rioters and in the numerous one-on-ones that I had both within and outside of SI. Finally, and most importantly, I’m very grateful for the amount of support and trust shown to me by my manager, Kyle Burton, and the entire engineering team at SI.
Will Keatinge
Role: Software Engineer
Team: RDX Operability
Hello! I’m Will Keatinge and I’m currently studying computer science at Rensselaer Polytechnic Institute. I spent this summer as a software engineer intern on the RDX: Operability team. The Operability team makes it easier for developers to build and monitor their services.
This summer, I built a service in Go that pulls data from several different sources of truth at Riot to provide an API for determining the teams, contributors, products, and code repositories associated with a service. For example, League of Legends is powered by hundreds of different microservices; if one of these services starts triggering alerts it can be very tricky to track down what that specific service does and which team can help bring it back to a healthy state.
Once I finished the API, I also built an integration into Console, the tool used to inspect running services at Riot. The integration now allows developers to search for a service and immediately see the code repositories, teams, products, and contributors associated with that service.
Figuring out who owns a service requires pulling data from all sorts of different systems at Riot. My service searches Github for related code repositories, looks at deployment artifacts, searches the Riot Data Model GraphQL API (which has information on every employee and every product at Riot), and looks at network blueprints (configuration files that specify which services can communicate with one another). Each of these different sources of information provide a small part of the picture, and my service brings all that information together in an easy-to-use API.
One of the most challenging parts of this project was making the API performant. Figuring out who owns a service requires lots of API calls, many of which cannot be parallelized. For this reason, I settled on a caching architecture. Instead of looking up services on demand, every service is looked up twice a day and the result is cached. With this design, instead of waiting 10-20 seconds for a lookup request to complete, the results can be served almost instantly from the cache.
I really enjoyed my time at Riot, as it was an incredible learning experience. Bringing a new service from idea to production - while daunting - taught me so much about how services are deployed, configured, and monitored at Riot. I absolutely could not have done it without the incredible support from my team at every step of the process.
Robert Tan
Role: Software Engineer
Team: IT Design & Development
Hi! I’m Robert “Ragekid” Tan, a computer science major at the University of Toronto. This summer, I was a software engineer intern at Riot on the IT Design & Development team, a fairly new team that is responsible for many of Riot’s internal IT products, such as Slackbots and other tools to aid workflow.
AmumuBot
My intern project this summer was AmumuBot, a Slackbot that delivers Slack channel suggestions to Rioters based on the interests that they’ve listed elsewhere. One of the best parts of Riot is the sense of community, and in the midst of the WFH situation, the team felt that it was extremely important to prioritize each others’ mental health. A great way to achieve that is through Slack communities for Rioters with similar interests.
A couple of things needed to happen before the final Slackbot could be written. First, I needed to create an ETL to aggregate Slack channel data into our datastore on a regular schedule. Next, I needed to design and propose a graph database schema (we use Neo4J) to store connections between Slack channels, topics, and Rioters. This step also required a change in the way we currently story Rioter interests. Once this was all in place, I needed to actually make the connections between Slack channels and topics. Due to time constraints, I used a modified keyword matcher that runs together with the ETL. Once these were all in place, I needed to leverage Slack’s development platform (I used Bolt) to create a Slackbot that utilizes the stored connections in the database and deliver them to Rioters on a specified schedule.
One of the core challenges for this project revolves around the concept of graph databases. Our team leverages Neo4J to represent the relationships between all types of data at Riot in the form of nodes and edges. The schema I eventually settled on looked something like:
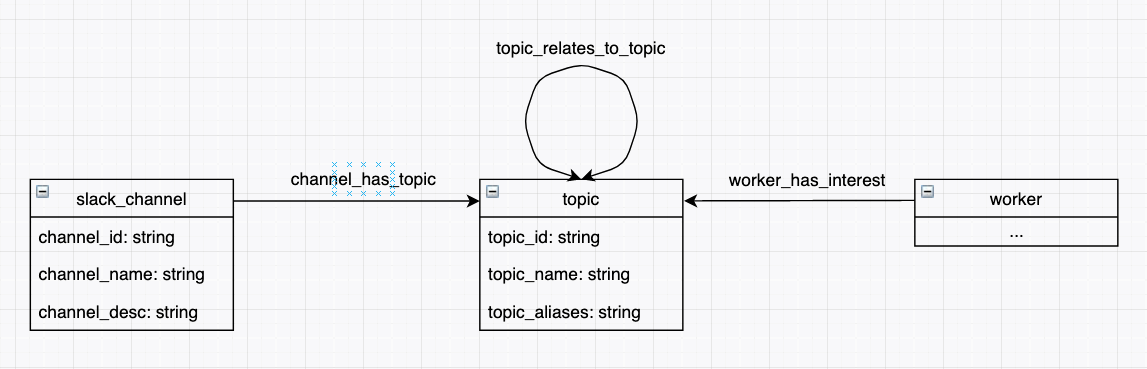
Where edges are represented by arrows and nodes are represented by the boxes. Each node also contains fields that store information related to the node. From here, the problem of finding a channel that a Rioter might be interested in is as simple as finding paths between “slack_channel” nodes and “worker” nodes (if we forget about the direction of the arrows for now).
The algorithm that associated Slack channels with topics also required quite a bit of thought. Initially, the idea was a simple regex matching process that matched any topics to the channel name and the channel’s description. However, this method fails because shorter topics can get erroneously matched with certain channel descriptions. For example, if we have a topic named “C” or “Art”, it may get matched with any channel descriptions that contain the character “c” or descriptions that contain words like “part”. One workaround for this is to match the whole word only, but this also fails because we want “Team Fight Tactics” to match “Teamfight Tactics” and similar cases. The final matching algorithm eventually took into account several factors to reduce the number of false positive and false negative matches. Some of these factors include: the ratio between the length of the topic and the length of the description, number of occurrences of the topic in the description, and whether the topic comprises multiple words.
Throughout the project, I also had the opportunity to work with other exciting pieces of tech on the infrastructure side. Infrastructure and deployment is almost never something we learn in school. To deploy the bot, I simply wrote a YML file containing the configurations, and Terraform deploys them onto AWS with a single command. AWS Lambda is another exciting piece of technology that the bot heavily leverages. In essence, it allows us to invoke a function, run it, and tear it down - no need for servers. The event handler is invoked by HTTP requests Slack sends based on various events. This setup required minimal amounts of effort on the infrastructure and deployment side, while setting up logging automatically.
Mini Hackathon
On top of my intern project, our team also organized a miniature hackathon, where I worked on a gachapon-style game with League of Legends characters on Slack to brush up on my Slackbot development skills.
Xiaxuan Tan
Role: Software Engineer
Team: Cloud Services Integration
Hi! I'm Xiaxuan Tan, a master’s student at the University of Southern California majoring in computer science. This summer I worked as a software engineer intern on the RDX Cloud Services Integration team. Our team focuses on providing Riot developers an easy and unified way to access cloud services.
Cloud Services Integration allows users to create, update, and delete cloud resources like MySQL databases and Kafka clusters by defining these resources in a specification file and deploying with a command-line tool. My project was to enhance the current toolings and allow users to bootstrap their MySQL databases in a convenient way. Specifically, so Riot developers can define what schemas and database users to create in a database in that same specification file.
Before this project, Riot developers had many ways to initialize a database which might vary greatly across teams. By modeling the bootstrap configurations into a few lines of YAML, our cloud provisioner can take care of creating schemas and users.
This feature required coordination of a couple of services, so the first step was to define data structures and parsers so that YAML blocks could be consumed and messages could be forwarded between components. As the database deployment could take a very long time, our cloud provisioner handles requests asynchronously and polls the status of resources periodically. The moment the database is brought up, we do the initialization, making sure that the database is ready before our users run applications on it.
In a nutshell, I spend a fruitful summer here in Riot: implementing a project, bringing it online, collecting feedback, and revising. What's more, I really enjoy how people collaborate and thrive together here. What I learned was not just how to write programs, but also soft skills like communication, teamwork, and customer orientation.
Ashwin Pathi
Role: Software Engineer
Team: RDX Service Lifecycle
Hey! I’m Ashwin “LaG 4G LTE” and I’m a computer science major at the University of Virginia. This summer I worked as a software engineer intern on the Riot Developer Experience: Service Lifecycle team. The main goal of the Service Lifecycle team is to make the deployment of microservices easier, faster, and more consistent across Riot’s global array of data centers.
The Service Lifecycle team owns Riot’s deployment service, which is a collection of tools and services that abstract and streamline the deployment process of microsystems across various data centers. My specific project was about optimizing ready checks, which is an important part of our deployment process. This involved making a new microservice, and working on the codebase of our deployment service, both of which were largely coded in Golang.
In our current architecture, we determine if a deployment process has successfully started up through ready checks, which essentially polls specific endpoints on deployed services to determine whether they started up successfully.
Initially, our deployment service was in charge of performing ready checks directly on each candidate. However, network connections between our deployment service and candidates can get expensive if they span data centers. To alleviate this, I was tasked with creating a dedicated ready check service that would forward requests from our deployment service to each deployed service, and be present in every datacenter. Whenever a deployment service would make a cross datacenter request, the request would be proxied through the associated ready check service at that datacenter. This would offload network complexity onto the ready check service instead of the deployment service, and reduce the total number of expensive network connections that we would have to manage. Here’s what the network connections looked like before the change:
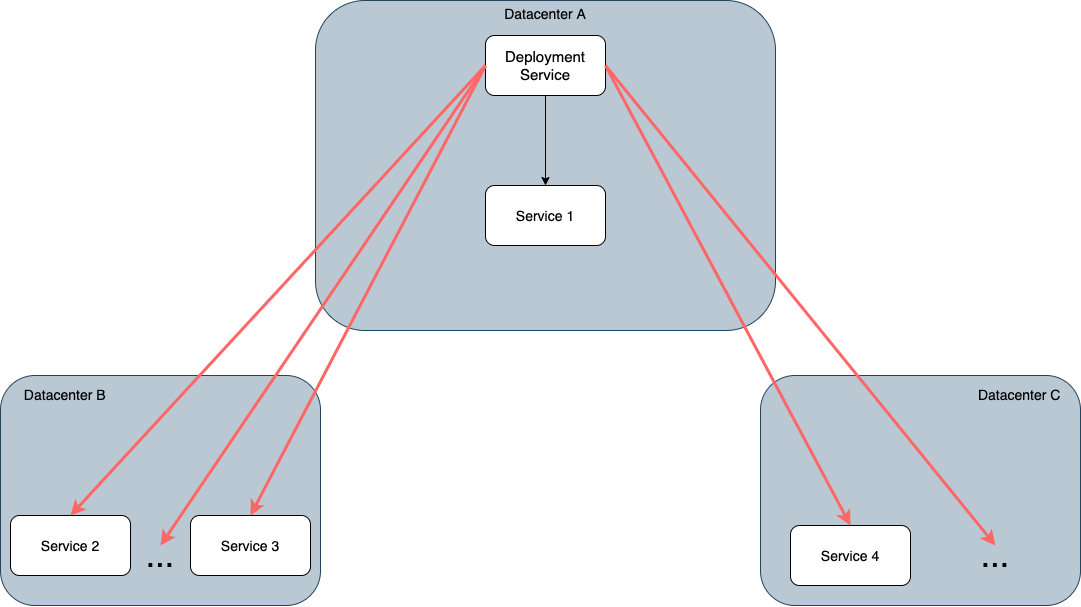
And this is what the network connections would look like after adding in the ready check service:
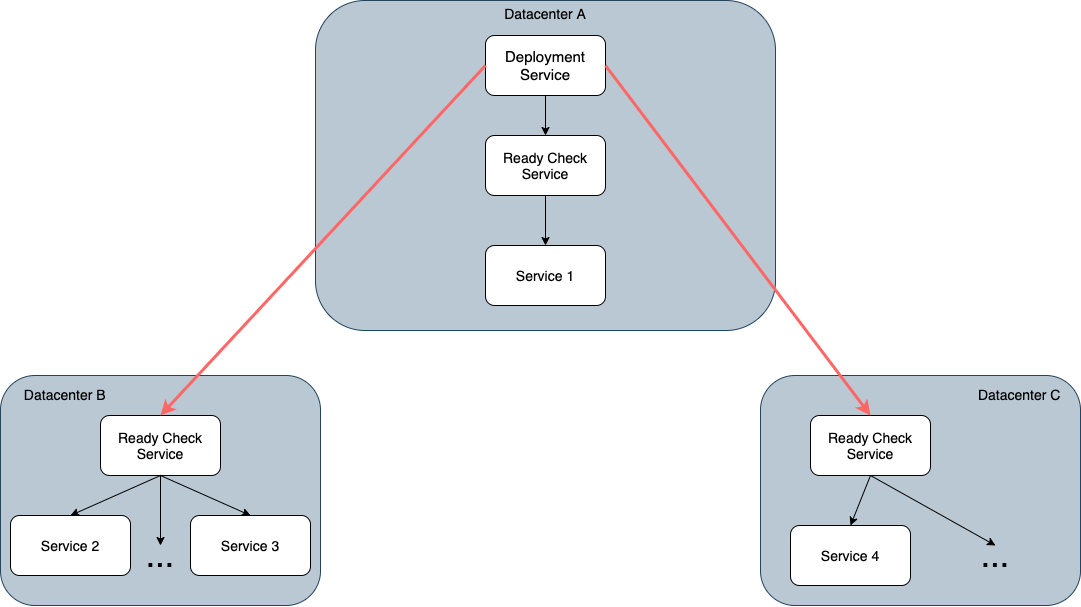
Since the goal of my ready check service was to ensure that the deployment service doesn’t contact any cross data center service directly, I opted to use a reverse proxy. To implement this, I used an aptly named Golang object called ReverseProxy, which handles an entire request round trip from the client to the intended destination, and back to the client. What’s interesting about Golang’s reverse proxy is its extensibility. The proxy itself can be constructed to have several middleware layers, which act as methods that sequentially process the incoming request. In the case of my service, the layers were fairly straightforward - one layer for authentication, another layer for request rewriting logic, and a final layer for error handling. The proxy itself was bound to an API endpoint on my service, which meant that any well-formed request to my service at that specific endpoint would be automatically routed through the proxy.
As part of my project, I also had the chance to directly work with and modify Riot’s deployment service. This involved dynamically adding new network connections, and writing new code to form and send a request to the right ready check service if the feature was enabled. Since the ready check service is a reverse proxy, creating the request was extremely simple, and none of the response handling code had to be changed. This is because the response was effectively the exact same as if the deployment service had called it.
The most challenging technical aspect for me this summer was designing and architecting my solutions to work seamlessly with Riot’s existing infrastructure, and working with Golang for the first time. Lots of my time was spent thinking about the best way to approach a problem, prototyping solutions, and generally getting acclimated with how Riot operates their microservices. I learned a ton about Golang and networking while working here, and it was definitely rewarding to actually have my first Golang project be somewhat impactful.
Though my work this summer was challenging, it was also extremely fun! I really enjoyed my time at Riot, and a large part of that was because of the people I worked with. Everyone on my team was super helpful and really great to be around. From playing games, to helping me out with coding, to just chatting about random stuff, the people on my team and the rest of the people at Riot really made my experience this summer amazing!
Check out the rest of our 2020 intern series:
Part I: League of Legends, TFT, & VALORANT
Part II: General Game Tech & Tooling/Infrastructure (this article)