Voyager: A Search Engine Approach to Understanding Real-Time Player Issues
[Editor's note: this article is available in the team's original Korean/한글 here.] As members of Riot Engineering in the Korean office, serving the local League of Legends community is our top priority. One pillar of our team’s mission is to understand and respond to player issues as quickly as possible. The sheer size of the Korean player base, however, presents a challenge to that goal, and the dynamic, ever-evolving nature of the game only adds to the complexity of the problem. To maintain high-quality service, we must be able to quickly evaluate and prioritize many different issues based upon their severity, urgency, and frequency.
Fortunately, we’re facing this challenge armed with information. We receive a massive amount of valuable information directly from players in the form of message board posts and support tickets. These first-hand, real-time accounts from players experiencing pain can help us detect and resolve service issues—but only when we’re able to navigate the immense amount of data efficiently and quickly. The problem then comes down to this: how can we monitor and analyze this vast amount of data in real time?
In this post, we’ll present our solution to this problem: a real-time, text-based search engine project we call Voyager. We’ll share the story of how we built the system and how we developed it to be more sustainable and efficient. In addition, we’ll discuss some of the challenges unique to processing the Korean language. We hope it’ll be interesting and useful to anyone approaching challenges in the domain of real-time text indexing and processing.
Real-time monitoring of a live service
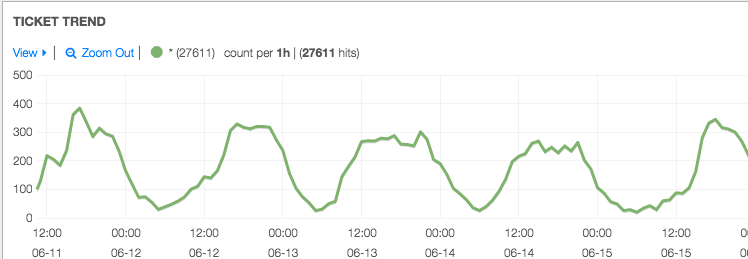
Before we talk about its design, we first want to shed further light on how we use Voyager. Consider the screenshot below:
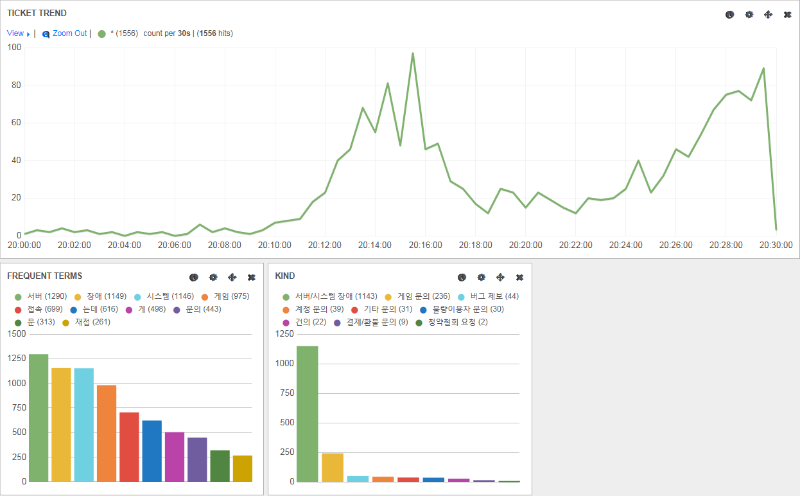
In the top graph, we can see the number of player support tickets over time—at a glance, it’s clear there’s an issue affecting players when there’s a sharp increase in ticket number. In the lower left, a bar graph displays frequently seen terms in the tickets, aggregated from real-time indexing of the ticket text. These frequent terms are enormously helpful in live triage scenarios. In this example, monitoring of the game platform signalled issues in the login queue. Since the most frequent terms in tickets are “server,” “game,” and “connection,” this information directed our engineers to first troubleshoot game connection drops, which indeed was the root of the problem. Beside the frequent terms bar graph, a second graph shows the kind of tickets coming in, which can help confirm our hunches. Without real-time text analysis, identifying the problem and arriving at a solution would have taken much longer than it actually did.
Some problems are rooted on our side, but Voyager can also help with issues originating from external causes. For example, in September 2014, a login queue rapidly formed alongside a sharp drop in the total number of concurrent players. However, we found no alarms sounding from our individual servers. While our monitoring wasn’t helpful in identifying the problem, Voyager began reporting a new and frequent term in support tickets: the name of a major Korean ISP. Instead of spending time diving into our platform looking for the elusive root cause, we could let our players know exactly what was happening.
Real-time full-text search with Elasticsearch
We store player support tickets in an SQL database, and, ideally, queries to it could enable the use cases we discussed above. Nice and simple, but that’s not how it goes in practice: although relational databases are great if you know exactly what you’re searching for, they’re terribly slow when you need to search for substrings within text. Before Voyager, the Korean Player Support team’s searches could take anywhere from a few seconds to a few minutes to locate keywords within the database. At times, the entire ticket service became unresponsive because searching applied such a heavy load on the database. Such an impact on our ability to support players wasn’t acceptable.
Voyager, as a full-text search engine, stores and searches for keywords in a full corpus of text articles. It completes these operations in under one second and returns every recent ticket containing the provided keyword. As seen in the examples above, it also provides useful statistics around keyword frequency, related keywords, and related ticket count over time.
At the heart of Voyager is Elasticsearch, an open-source, distributed, full-text search engine based on the Apache Lucene project. While Elasticsearch shares many strengths and weaknesses with Lucene, its true strength comes from its distributed nature. You can shut down any single node in a cluster and that cluster will still serve users with just a small hiccup. The performance of the cluster also scales with the number of nodes, which makes it easy to handle increasing data load.
Kibana: a user-friendly interface to Elasticsearch
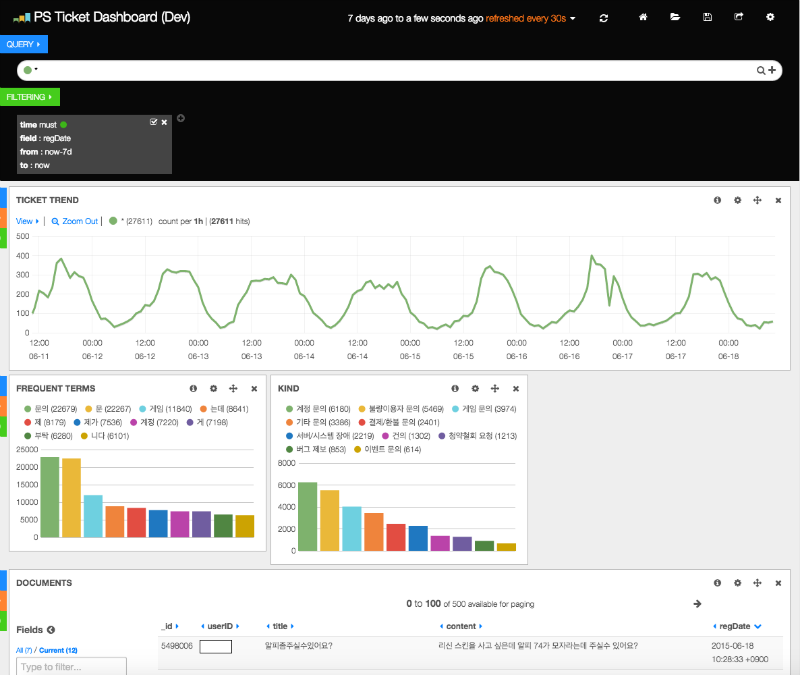
For vizualization, we use an in-browser HTML-5 based UI called Kibana. For Voyager, Kibana presents a clean dashboard interface on current tickets and trends. This dashboard is highly configurable: panels of any data summary can easily be added or rearranged.
For example, the “kind” panel in the screenshot above displays a bar graph with the number of tickets sorted on the “kind” column. The “ticket trend” panel at the top is a line graph showing the number of tickets over time. Preconfigured arrangements of panels can be saved so users can quickly access the information they frequently need.
The most fascinating part of Kibana is its ability to reflect the speed of the Elasticsearch cluster underneath. If “Leona” is entered in the search bar, each panel immediately updates to display graphs and information related to only that champion. This feature supports our team in getting instant insights into real-time player issues. With simple searches in Kibana, our team tracks daily trends, related keywords and categories, and relevant tickets.
Indexing the Korean language
Here’s where our system gets a bit complicated. Given an entry of text data, a full-text search engine like Elasticsearch tokenizes every sentence into a list of keywords. These keywords then index that particular record of data for later retrieval on user queries. This process faces particular challenges in the Korean language due to its agglutinative nature.
Agglutinative languages do not insert breaks between nouns and grammatical elements. For example, "바이는 정글러이다" means "Vi is a jungler" in Korean. Here, "바이" means "Vi," and "정글러" means "jungler." The grammatical elements of the phrase — "는" and "이다" — represent syntactical functionality that is achieved by word sequence in the English language.
We want to avoid inserting these grammatical elements into the system when indexing Korean text because they would only add unwanted noise to search results. However, when tokenizing a Korean sentence, it’s difficult and often ambiguous to separate a verb or noun from related grammatical elements. It’s even more difficult if the sentence to be parsed contains words not found in the dictionary. Despite LoL’s popularity in Korea, the word “jungler” isn’t in dictionaries—many other jargon words from internet or gaming communities are also absent.
Fortunately, recent open-source efforts to solve the problem of identifying grammatical elements in Korean text have made great progress, such as the Lucene Korean Analyzer. Because it’s intended to work with Lucene (which Elasticsearch is based upon), we were able to develop a plug-in to leverage the Korean Analyzer algorithm to properly tokenize Korean text. We’re grateful to the project for its help in better serving players here in Korea.
At the same time, we still have room to improve in this area. Consider the Korean name for the champion Sona "소나" and how it could also be tokenized as "소" (cow) + "나" (conjunction postposition, a grammatical element). While the Korean Analyzer successfully identifies the grammatical element, both possibilities remain. Because of this, even if we were only interested in results related to "소" we might get results related to "소나" too. In the near future our team plans to tackle adding further context-sensitivity to the algorithm.
Index partitioning
As I’ve mentioned, speed is of the essence but maintaining speed can be difficult with the volume of data we receive. Partitioning indices thoughtfully can help. An index is a collection of data distributed over the entire Elasticsearch cluster. The more data a single index receives, the more time-consuming writing and searching in that index becomes. To prevent performance decay over time as data piles up, we partition the index on a monthly basis.
Partitioning is a prioritization exercise: it places a higher value on data from the last month over older data. Searching over the entire time period is therefore slower, while searching over the last month is faster. It is highly inefficient to manually perform index partitioning every month. For this type of task, Elasticsearch provides an index template API. Here’s the HTTP PUT request we use to create the monthly preconfigured index:
curl -XPUT 'http://voyager.riotgames.com/_template/ps_ticket_template' -d '
{
"template": "ps-ticket-*",
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1,
"analysis": {
"analyzer": {
"default": {
"type": "standard"
},
"ko_analyzer": {
"type": "custom",
"filter": ["lowercase", "arirang_filter"],
"tokenizer": "arirang_tokenizer",
"analyzer": "arirang_analyzer"
}
}
}
},
"mappings": {
"ps_ticket": {
"_all": {"analyzer": "ko_analyzer"},
"properties": {
"_id": { "type": "integer" },
"userID": { "type": "string", "index": "not_analyzed" },
"kind": { "type": "string", "index": "not_analyzed" },
"title": { "type": "string", "analyzer": "ko_analyzer" },
"content": { "type": "string", "analyzer": "ko_analyzer" },
"answered": { "type" : "boolean" },
"deleted": { "type" : "boolean" },
"regDate": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss Z", "include_in_all": false},
"editDate": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss Z", "include_in_all": false},
"answerDate": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss Z", "include_in_all": false},
"ipAddress": { "type": "string", "index": "not_analyzed" }
}
}
}
}
'The “template” field informs Elasticsearch to apply this template to new indices with names that match the “ps-ticket-*” string. You can see we set the custom analyzer and tokenizer to “arirang,” which is provided by the plug-in we created for the Lucene Korean Analyzer.
The “mappings” section configures analyzer settings for different fields. In some cases it isn’t appropriate for Elasticsearch to consider all the data available to it. If a user searches for Singed, they certainly aren’t interested in receiving every ticket submitted by a user named DontChaseSinged. That’s just noise. In the request above, certain fields like “userID” and “ipAddress” are marked as “index”: “not_analyzed” in order to be ignored on searches. Other fields with essential content, like “title” and “content” are marked with “ko_analyzer” for proper tokenization and searching.
Conclusion
In this article we took a brief look at the interface, architecture, and maintenance of Voyager, as well as some real-life examples of how this search engine helped us better tackle live issues in Korea to serve the local community.
As you’ve seen above, the greatest benefit of Voyager is that it enables us to comprehend the collective voice of many Korean players experiencing service issues in real time. Voyager has already helped us improve our response time and reliability in resolving live issues while saving valuable resources. Though Voyager certainly has room for improvement and iteration, we hope this article was useful for anyone facing similar challenges. When there’s a problem, the answer might be found nearest to the problem; in our case, it’s the players we serve, since they’re the ones most impacted by any issue we might have.