
Using Perforce in a Complex Jenkins Pipeline
Hi, I'm Guy "RiotSomeOtherGuy" Kisel, a software engineer at Riot. You might remember me from Running an Automated Test Pipeline for the League Client Update. I work on the Riot Developer Experience team - our responsibilities include providing Jenkins servers and related infrastructure for engineers to use for building, testing, and shipping their software to the millions of players that play League of Legends. We’re sort of like a traditional build team, except that we provide self-service tools for engineers to manage their own builds instead of building their software for them.
We recently encountered issues integrating Jenkins Pipeline and Perforce and wanted to share our experiences and eventual workarounds. Integrating Pipeline with Git is relatively straightforward, but integrating Perforce presented us with an entirely new set of problems, like conflicts between concurrent jobs on the same build node, and difficulty syncing the right changelist multiple times in a single pipeline.
In this article, I’ll walk you through the problems we faced and how we created a Jenkins Pipeline library to work around them. I hope this article will be valuable for anyone who finds themselves in a similar problem space. Our pain is your gain! We should rename this article “Riot Overflow.”
We’ll start with a bit of context about Git, Perforce, and Jenkins. Git is popular across the tech industry, but Perforce is somewhat less common outside of specific industries like gaming. Jenkins is also very popular, though it’s facing heavy competition from alternatives such as Travis CI. Then we’ll dive into the problems we encountered with integrating Jenkins Pipeline with Perforce, including solutions we developed for each problem. And finally, we’ll conclude with some general learnings we discovered along the way.
Context: Git, Perforce, Jenkins
I came to Riot from outside the gaming industry, and before I started here, I'd never used Perforce.
At Riot, we provide both Perforce and Git as version control solutions so that development teams can choose the solution that fits best with their needs. We value developers having the flexibility to choose the tools and technologies they want, within reasonable limits. We use Perforce for products like the League of Legends game server, game client, and build tools. We use Git for microservices and miscellaneous tools. There are other version control tools out there, but Perforce and Git cover all of our use cases.
Later in this article, I’ll dive into the specifics of integrating Pipeline and Perforce, but first, let’s quickly explore why we’re using Perforce (also commonly referred to as P4) in the first place. As compared to Git, Perforce tends to be better for giant monorepos that contain a lot of binary data, such as art assets or compiled C++ libraries. Perforce allows for fine-grained access control, such as the ability to give artists full access to art assets but read-only access (or no access) to source code in the same repo. Git is great for repos that contain pure source code and can even support binary data via Git LFS, but currently Perforce is often more stable and performant than Git LFS. For game development, Perforce has historically been a solid solution that works well because games are often large monorepos full of a mix of source code, art, tools, and artifacts. Engineers and artists from the games industry often have years of experience with Perforce and sometimes have less experience with other version control systems.
For more details and opinions on Perforce vs Git, check out these articles:
- https://www.atlassian.com/git/tutorials/perforce-git
- https://www.perforce.com/blog/hth/when-git-tool-stack-falls-over
- http://ithare.com/choosing-version-control-system-for-gamedev/
- https://www.theregister.co.uk/2017/01/06/splunk_bitbucket_git_perforce/
- http://stevehanov.ca/blog/index.php?id=50
Perforce and Git behave pretty differently in a continuous integration context. Comparing their behavior will help us establish the problem space.
Git vs. Perforce
Git
First, let’s look at Git. In a build job for a Git repo, the Jenkins workspace on the build node is typically a complete, independent copy of the Git repo. Once you’ve cloned the repo, you usually don’t have to worry about the state of the original repo. Git repos tend to be smaller than Perforce repos, so it’s no big deal to clone a repo, build it, then delete the Jenkins workspace. Git clones are usually also pretty simple in Pipeline syntax. You can either just use "checkout scm” or something slightly more complex like “git branch: branch, credentialsId: sshCredsId, url: repoUrl”.
Perforce
Now, let’s look at Perforce. For detailed info on Perforce terminology, see the Glossary tab in the Perforce Command Reference. For Jenkins terminology, see the Jenkins Glossary.
In a build job for a Perforce repo, the Jenkins workspace on the build node has a one-to-one relationship with a Perforce workspace. For example, I could have a Perforce workspace named "guys-code" that points at a directory on my PC named "C:/guys-code-dir".

This can be a little confusing - they both use the word “workspace,” but they have different meanings. A Jenkins workspace is just a directory on disk in a build node that’s used for storing files for a build. A Perforce workspace is a specification of paths and files from the Perforce repo along with metadata about their current state on disk.
Throughout this article, I’ll specifically be using the terms “Jenkins workspace” and “Perforce workspace” to minimize confusion. Perforce workspaces have both local- and server-side statefulness. The server-side state normally tracks the local state to allow for syncing optimizations, which are useful with large repos. For example, if we know the local Jenkins workspace already contains the latest version of most of our files, we don’t need to sync them from the Perforce server.
While a Git clone in Pipeline is simple, a Perforce sync in Pipeline potentially involves many settings. These settings allow for powerful customizations, but they can be tricky to configure correctly. The settings do have some default values, but the default values don’t work well in many of our use cases.
Using Perforce with Jenkins
Jenkins and DSLs
We use Jenkins extensively, as you can tell from some of our previous articles. A long time ago, we mostly used manually-created freestyle jobs that ran build scripts checked out from version control. Later, we moved on to Jenkins Job DSL, which allowed us to version control our jobs, and even do some dynamic job generation. Over the last few years, Jenkins Pipeline has taken over as the primary way to use Jenkins in the open source world, and we’ve transitioned internally to follow this trend. Most of our new Jenkins usage is Pipeline as it’s better supported and more future-proof. It’s also just a really nice way to write build automation.
Mixing Pipeline and Perforce
Riot Tech’s practice is typically to provide a selection of technologies and tools as first-class, fully-supported citizens in our ecosystem, and teams are welcome to mix and match any of those technologies to suit their needs. We realized we needed to build an accessible integration between Pipeline and Perforce when we encountered a team working closely with the League of Legends engineers. They chose to use Perforce for easier code sharing with League, which has had a pretty stable build pipeline for a while without investing heavily in Pipeline. This new team decided to use Pipeline because of network effects, but because they were the first team to heavily mix Perforce and Pipeline, they ended up running into some early adopter problems.
The Pipeline + Perforce integration problem space and solutions
Initially we directly used the regular Perforce plugin with Jenkins Pipeline and it worked well. As the build pipelines became more complex and more developers joined the project, we began running into several issues that became increasingly difficult to deal with. Builds were failing regularly for mysterious reasons that sometimes resolved themselves and sometimes needed to be resolved via time-consuming manual deletions of Perforce workspaces and Jenkins workspaces. We eventually realized we needed to take a few steps back and consider all of the issues together.
Let’s walk through each of the problems we encountered along with the solutions or workarounds we came up with.
Concurrency
Problem
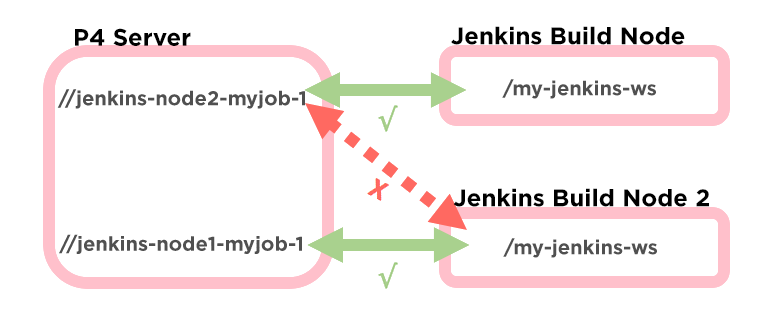
In Jenkins it’s common practice to run multiple builds concurrently on the same node to more efficiently utilize resources. When you have two or more of the same job running on the same node, Jenkins automatically handles this by creating an additional Jenkins workspace.
For example, if our original Jenkins workspace path is ".../my-job-name", the additional Jenkins workspaces will be named ".../my-job-name@2", ".../my-job-name@3", and so on. Unfortunately, the job is not necessarily automatically updated to use a new Perforce workspace for each of these concurrent Jenkins workspaces.
This can result in the same Perforce workspace being reused for multiple Jenkins workspaces, which corrupts the Perforce server-side workspace state to no longer accurately reflect the state of the Jenkins workspace. The Perforce plugin attempts to work around this by defaulting the Perforce workspace name to "jenkins-${NODE_NAME}-${JOB_NAME}-${EXECUTOR_NUMBER}".
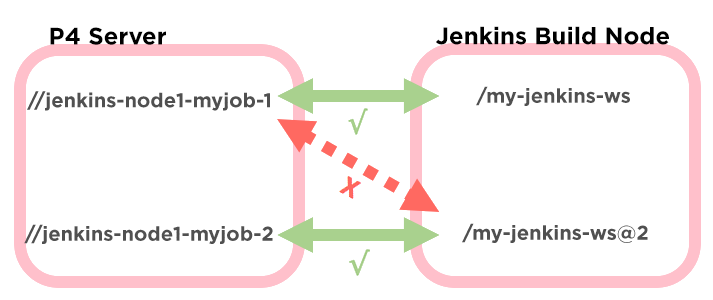
The @2 in the Jenkins workspace name does not actually mean that the EXECUTOR_NUMBER is 2. The two values are unrelated to each other, so the Perforce plugin defaults can still result in corrupted Perforce workspaces. The plugin does attempt to work around this by changing the value of EXECUTOR_NUMBER when doing variable expansion, which works well in most cases. However, this doesn’t help us because we need to do additional path modification to solve other issues, such as shortening our path lengths.
Solution
We name the Perforce and Jenkins workspaces based on the job name, the stage name, and the number Jenkins assigns to automatically-generated concurrent workspaces. We were running into issues with long or complex stage names causing excessively long paths on Windows (a common build environment in the games industry), so we hash the stage name and just use the first four characters of the hash to get something consistent but unique-ish for our purposes. Four characters is not many, so if we have lots of workspaces and stages we could inadvertently fall victim to a birthday collision. For persistent workspaces on non-ephemeral build nodes, we also add the node name. Finally we add the name of our Jenkins instance in case we have the same job on different Jenkins instances. Once we’ve created this workspace name, we use the Pipeline “ws” step to switch to a new Jenkins workspace that’s guaranteed to be safe for concurrency. Because we create a new Jenkins workspace, the Perforce sync wrapper accepts a closure of code to run within the Jenkins workspace.
def riotP4Sync(Map config = [:]) {
def humanReadableName = safePath("${JOB_NAME}-${STAGE_NAME}")
def jenkinsWorkspaceName = safePath("${JOB_NAME}-") + workspaceShortname(env.STAGE_NAME)
// we create a custom workspace to work around two issues:
// 1. this lets us make sure our workspace is safe for concurrent runs of the same pipeline on the same machine
// 2. this lets us have separate workspaces for each stage in a pipeline that does a sync
ws(jenkinsWorkspaceName) {
echo "[INFO] [riotP4Sync] Running in ${pwd()}"
// if we zero index then we never get a "1" workspace :(
def workspaceNumber = 1
// jenkins puts @<number> at the end of a workspace when running pipelines concurrently
if (pwd().contains('@')) {
workspaceNumber = pwd().split('@').last()
if (!workspaceNumber.isInteger()) {
error("${workspaceNumber} is not an integer! Something went wrong in riotP4Sync. PWD is ${pwd()}")
}
}
def p4WorkspaceName = safePath("${humanReadableName}-${workspaceNumber}")
echo "[INFO] [riotP4Sync] Using P4 Workspace ${p4WorkspaceName}"
...
}
Broken workspace cleanup
Problem
If the Jenkins workspace on disk is in a bad state, it’s easiest to just delete the workspace. But if we delete the workspace, the Perforce plugin might not sync the right files in the default plugin behavior, and instead we need to force it to sync everything. For old style Freestyle Jobs using the old Perforce plugin there was a “one time force sync” button which looked like this:

But this isn’t a built-in option for the newer plugin or for Pipelines.
Solution
After switching to our safe Jenkins workspace, we first check to see if there are any files or folders in the current directory. If we find files, we can assume the workspace is in a healthy state and continue with a regular sync. If there are no files, we do a Force Clean sync to ensure we grab all of the files in the viewspec or stream. This makes corrupted workspace cleanup as easy as just deleting all the affected workspaces and letting them automatically recover on the next build.
def filesInWorkspace = true
try {
// see if we're in an empty dir. if so, we should do a fresh sync.
filesInWorkspace = sh(returnStdout: true, script: 'ls').trim()
} catch (err) {
echo '[WARN] [riotP4Sync] checking for files in workspace failed'
}
// see if we're in an empty dir. if so, we should do a fresh sync.
if (!filesInWorkspace) {
defaultConfig.syncType = 'ForceCleanImpl'
}
Persistent vs ephemeral workspaces
Problem
At Riot we provide both ephemeral workspaces (in the form of Docker Jenkins) and persistent workspaces (in the form of virtual machines). Our ephemeral workspaces are great for a number of use cases (such as small repos where caching is not important), but we still have many builds that depend on running in persistent virtual machines. In a persistent workspace, we want to preserve and reuse existing files whenever possible. The Perforce “have” list is a powerful feature for tracking which files already exist in a workspace in the right state and therefore don’t need to be synced again. However, this same “have” list causes problems with ephemeral workspaces because once we shut down our Docker build node, the workspace state is no longer meaningful. If we maintain a “have” list for ephemeral workspaces, then on the next build we’ll only sync the changed files and the rest of the files will be missing.
Solution
Customizing behavior based on the nature of the build node is a pretty simple fix compared to the other issues. If we detect we’re running on the Jenkins instance that uses ephemeral build slaves, we set “have = false”. This tells Perforce not to bother populating the list of files that have been synced to the Perforce workspace. It might be better in the long term to determine somehow whether we’re running in a Docker build node so that we can take advantage of this behavior in Jenkins instances that have both ephemeral and persistent nodes. Another option we haven’t taken advantage of yet is to mount persistent volumes to Docker build nodes.
if (riotCommon.isOnDockerJenkins()) {
// if we're on dockerjenkins we don't care about existing files
defaultConfig.have = false
}Multiple syncs in a pipeline
Problem
We have a few pipelines that do multiple Perforce syncs over the course of a single pipeline. For example, one of the pipelines builds multiple different platforms in parallel, so it uses multiple different build nodes and does a separate sync to each node. By default, the Perforce plugin will just sync the latest changelist, which can result in the same pipeline syncing multiple different changelists if someone checks in during a build.
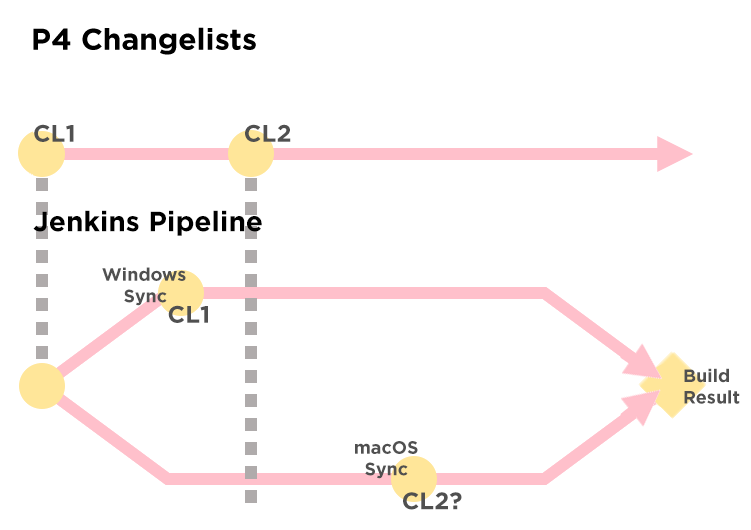
Solution
We track the current changelist as a global variable in the Pipeline library. Initially it’s unset and we just sync the latest changelist. After our first sync, we read the changelist number from the environment and write it back to the global variable. For any syncs after this, we just use the changelist from the global variable. There is some potential here for a race condition if two concurrent syncs start at roughly the same time at the start of the pipeline, but if this happens they’re highly likely to sync the same changelist anyway. For extremely high changelist rates it might be worth implementing a lock around the first sync but this hasn’t been necessary yet. Another potential approach is to shell out to the P4 CLI and ask it for the latest changelist while mutexed before doing any syncs.
Additionally, earlier we named our Perforce and Jenkins workspaces uniquely based on the stage name. This way, each stage that syncs from Perforce has a unique workspace state, which allows different stages to sync different viewspecs or streams safely.
// we want this to be global
@Field currentChangelist = ''
def syncConfig(p4Config) {
p4sync(
...
pin: currentChangelist,
...
)
currentChangelist = env.P4_CHANGELIST
}
Overly complex settings
Problem
As I mentioned before, the Perforce plugin allows for a lot of customization which means many adjustable settings. While this is powerful, it can also be confusing for engineers who aren’t familiar with all the intricacies of Pipeline and Perforce. This isn’t strictly a problem, but there’s still room here to make it more developer-friendly.
Solution
We set default values for almost everything. The only absolutely required parameters are a credentials ID and a viewspec or stream.
Reusable Solutions
Jenkins Pipeline Shared Library development
Jenkins Pipeline is extensible via Shared Libraries. These libraries can be defined globally and become implicitly available in all pipelines running on our Jenkins servers. This is a really powerful way for us to provide and update Pipeline features for our engineers. The downside is that any changes we make are instantly applied to all pipelines, so we have to be very careful not to introduce breaking changes.
In order to safely test our global libraries, we have a Dockerized locally runnable Jenkins we call Jenkinsdev, which we explain in this tutorial: Building Jenkins Inside Ephemeral Docker Containers. Jenkinsdev is a Git repo that we can clone to our dev machine. All I have to do is run “make build”, “make run”, and open up localhost in my browser. Once it’s up and running, I can point Jenkinsdev at my branch of our global shared libraries and safely test without impacting the main Jenkins instances. Only once I’ve successfully tested my changes in Jenkinsdev do I merge them to make them available to engineers. Jenkinsdev comes with a convenient set of test jobs baked in for testing basic Jenkins and Pipeline features like spinning up a Docker build node or building a Java project.
Another easy way to test global libraries is to point a job at a branched version of the libraries.
Because we provide our libraries globally, even though we developed our Perforce Groovy wrapper specifically for one team, it’s automatically available to all Riot software development teams. Many of the commonly used features in these libraries came about the same way - developed to solve a specific problem, but shared with everyone by default.
Collaboration across teams
Identifying and fixing these issues required collaboration across multiple teams. The problem space is pretty broad, and it’s difficult for any one person to have the appropriate knowledge to tackle it all alone. Instead, most of the work and knowledge came from three of us working together:
- I (Guy) provided the Jenkins knowledge and worked on our global Pipeline libraries
- Jules Glegg, the tech lead on the project that needed help, handled integrating my library changes with the project’s Pipeline
- Alan Kwan, our local Perforce expert, provided a lot of helpful Perforce knowledge and advice

Leveraging open source software
We benefited heavily from the open-source nature of the tools we’re working with. While Perforce itself is a closed source commercial product, the Perforce plugin for Jenkins is open source. This means that though the documentation for the plugin is light, we were able to dive into the source code to understand the plugin’s functionality so we could figure out how to work around problems.
Jenkins and Pipeline are also open source. While we spent most of our time in the Perforce plugin source code, being able to hop into the Jenkins and Pipeline source code occasionally was helpful. It’s also just nice to benefit from fixes and bug reports from developers around the world.
Conclusion
Coming from a background of mostly using Git, I’m personally not super comfortable with Perforce. Git is much more popular in the open source world, so it often has better integrations with open source tools like Jenkins. Despite this, there are many use cases we've run into where Perforce is the more appropriate option. And to stick to our philosophy of enabling engineers to use their languages and tools of choice, we value investing time in making integrations as easy as possible.
These workarounds could potentially be submitted back to the Perforce Plugin for Jenkins. Why didn’t we do this already? Mostly just for rapid iteration. It’s really easy to iterate within a Pipeline library, but somewhat more difficult to do so when it involves modifying a plugin. Now that this is in place and working, it might be worth taking the time to research implementing these fixes upstream. This would likely be a significant undertaking, in part because our fixes are implemented as a Groovy library, but the plugin is written in Java. Additionally, our solutions can be fairly opinionated and make some assumptions because we built them for our own use, but the plugin is designed for configurability and customization and therefore opinionated behavior might be undesirable.
Creating this integration and iterating on it has highlighted the importance of collaboration based on subject matter expertise. No one person at Riot has the expertise to tackle this problem alone. By working together and combining our knowledge, we can make it work.
Our implementation of these workarounds has worked well for us so far - builds are running many times a day using this code, and we’ve gone from fielding several Jenkins-Perforce integration issues a week to less than one a month. Additionally, the developers using these workarounds are now able to focus on developing their products instead of having to regularly troubleshoot build issues unrelated to their work.
If you have suggestions for improvements, we’d love your feedback.
Thanks for reading! Check out this github page for the actual source code.