
Supercharging Data Delivery: The New League Patcher
Hi, my name is Javier Blazquez, and I’m a software engineer on the Core Tech team on League of Legends. My team works on things like performance and determinism.
For the past 8 years, League has been using a patching system called RADS (Riot Application Distribution System) to deliver updates. RADS is a custom patching solution based on binary deltas that we built with League in mind. While RADS has served us well, we felt we had an opportunity to improve some key areas of the patching experience. We knew we could deliver updates much more quickly and more reliably by using a fundamentally different approach to patching, so we set out to build a brand new patcher based on content-defined chunking.
To compare our old and new patching solutions under the same conditions, we’ve been rolling out the new patcher incrementally over the past several months. This has allowed us to validate our assumptions about the effectiveness of a content-defined chunking approach. Now that we’ve completed the rollout and have measured a ten-fold improvement in patching speeds, we’d like to share some details about how it all works.
In this article, we’ll be discussing a few key elements of our new patcher, such as how the core algorithm differs from binary deltas, how we were able to maximize download speeds for players, and how we designed a scalable patch generation system that allows us to deploy a new version of League in minutes instead of hours.
Delivering Updates
Binary Deltas
Binary deltas are a common way of delivering updates. A binary delta - or binary diff - represents the difference between two versions of a file. You start with the two versions you want to diff, compare their contents, and then generate a binary patch. This patch allows anyone with a copy of the old file to convert it to the new version by reusing as much data as possible.
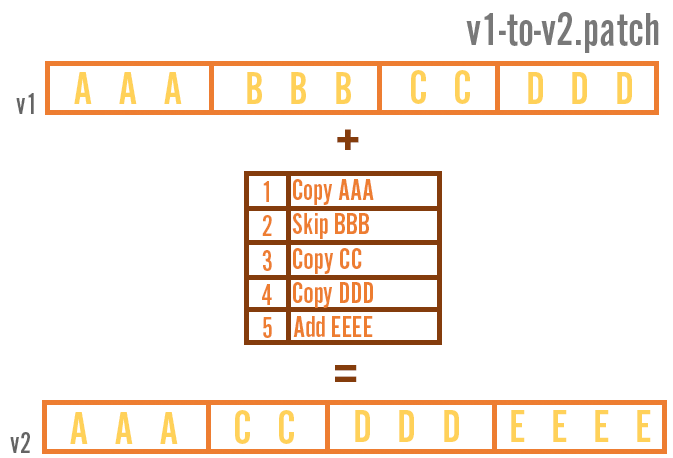
You can use tools like xdelta or bsdiff to create binary patches - for RADS, we used a similar tool called JojoDiff.
Binary patches can be very small, which helps deliver updates quickly. But you end up needing a lot of them when players try to update from very old versions of the game.
You have several options here:
-
Create a patch to go from version N-1 to N.
-
Pro: Every time you release a new version of the game you only need to generate one patch.
-
Con: If a player is M versions behind then they need to apply that many patches. This can really slow down update speed.
-
-
Create a patch to go from every previous version to the latest.
-
Pro: Players only need to apply one patch.
-
Con: Every time you release a new version you have to create many patches. This gets super expensive for a game like League which has released hundreds of versions over the past decade.
-
-
Use a skip list construction to create patches that can skip multiple versions.
-
Pro: You only have to generate a couple of patches with every release and players can update to the latest version in log2(M) steps.
-
Con: This is more complex and requires more upfront work than the other two options.
-
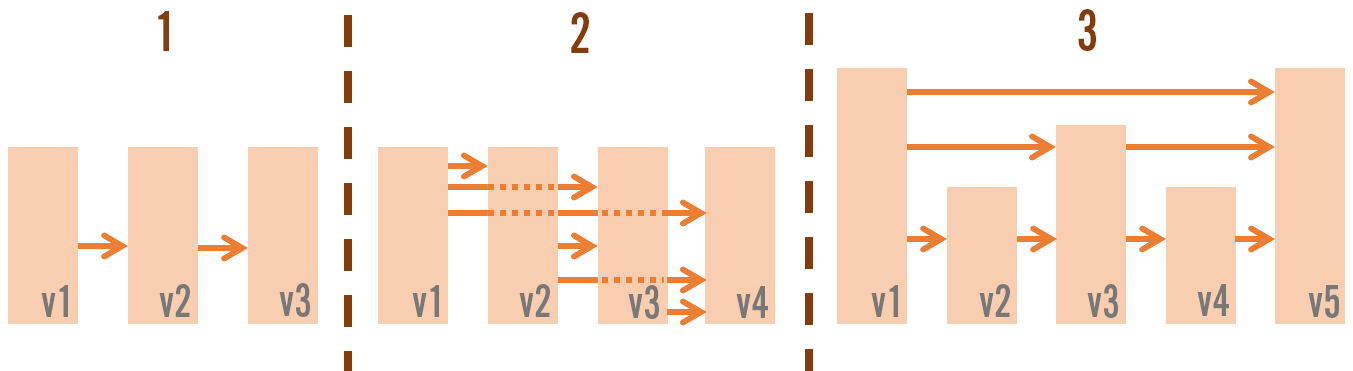
RADS uses the second option, and limits it to the previous 8 versions. This means any player who is at one of these eight prior versions can update to the latest one in a single step. But for players with older installations, RADS resorts to downloading files in their entirety, even if only a tiny part has changed. This causes some players to end up downloading a lot more data than others simply because they don’t play as frequently.
Binary delta systems optimize for small patch sizes. While this seems valuable at first glance, it comes with a number of important tradeoffs. That’s why we started looking at alternative approaches with different tradeoffs that we were more comfortable with.
Content-Defined Chunking
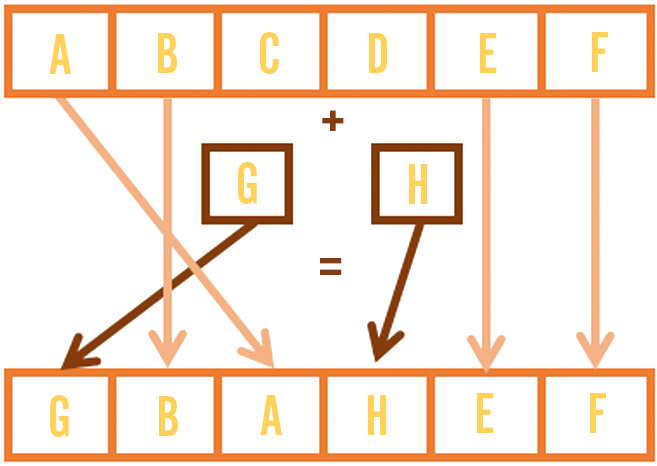
With content-defined chunking, you first split the file into a series of variable-size chunks. You then compare the list of chunks that you have with the list of chunks in the new file and download the ones that you’re missing. You can then reconstruct the new file by writing chunks in the appropriate order, reusing some of the data you already had.
The algorithm we use for content-defined chunking is based on FastCDC, which provides a very fast rolling hash. It operates at over 1 GB/s per core.
What makes this content-defined is that you split up the file only at the locations where the data satisfies a particular condition. You typically compute a rolling hash across the file and split at each location where the hash evaluates to certain values. For example, if you want chunks that are 64KB on average you would split wherever the hash value ends with 16 zero bits. The boundaries depend on the actual contents of the file, so you’ll end up with some larger and smaller chunks, but on average they should be close to what you’re aiming for.
The Benefits
The main benefit of choosing boundaries this way is that your chunks barely change when data shifts within a file. If you blindly split at 64KB boundaries, for example, then a single byte added at the beginning would change all the chunks throughout the file, which would be terrible for patch sizes.
A patching system based on content-defined chunking gives you a very important advantage over binary deltas: you can update any old version of the game to the latest one efficiently and in a single step. This was important to us because we want it to be just as easy for someone to jump into a game if it’s been a few years as it would be for someone who played that morning. You can also update a partially updated or corrupted installation equally well. You can even roll updates back quickly if you need to go backwards in time for some reason. All that matters is which chunks you have and which chunks you need.
The Tradeoffs
A tradeoff that you’re making with this system is patch sizes. Because the unit of patching is the chunk, if even a single byte in a chunk has changed from one version to another, you have to download the entire chunk. In a worst case scenario where every single chunk has changed in some way, you would need to download the entire game again. Luckily, we haven’t seen anywhere near that with League. Actually, patch sizes with the new patcher have been reasonably close to the old one.
Prior Art
Content-defined chunking is commonly used in systems where data deduplication is important, such as with backup software. This is because it can easily detect that two chunks are identical across several files and only store one copy of the chunk. But it’s also used in file transfer programs like the venerable rsync to know which parts of a file have changed and transfer only those.
Unlike rsync, we can precompute the list of chunks that comprise each version of League because we don’t need bidirectional transfers. We can publish that list on a CDN and distribute it to clients so they can figure out what data they’re missing. This means we don’t need special server software either. In that sense the system is more similar to zsync.
We call the process of creating this list of chunks patch generation.
Generating Patches
RADS
Generating a patch with RADS involved many different steps that were quite expensive. We first had to binary diff each file against its 8 previous versions. The Game folder in League only contains 400 files, but they’re pretty large, so diffing them can take a while.
We then had to compress and bundle up those binary patches into BIN files. We also had to compress each original file for when a client can’t patch an existing copy. Then we had to upload all those files to a staging server and from there sync them to each CDN origin.
Many of these steps weren’t parallelized, which made the process even slower. It generally took several hours for our build machines to go through this process.
Our New Patcher
The chunking patcher uses a much more streamlined process. We start by applying the content-defined chunking algorithm to each file to determine which chunks it has. We don’t need to compare files against their previous versions; all that matters is which chunks are in the new files that we want to ship. We only need to perform a single pass over the latest data, which is very fast.
Once we’ve determined the list of chunks, we hash and compress them. The 64-bit hash value is used as the unique identifier of a chunk. This allows us to quickly determine when a chunk is found in more than one location so we can deduplicate it. We’re able to deduplicate almost 10% of the chunks in League this way, which helps with the size of the initial download.
Compression
For compressing chunks we use Zstandard. We compress using level 19, which gives us very good compression ratios while keeping decompression speeds high. Decompression speed is important when downloading chunks on the client. Other algorithms such as LZMA would have a better compression ratio but CPU usage during decompression would be much higher.
After compression, we bundle chunks together into a small number of files that will end up on the CDN. These bundles are just concatenations of related chunks that clients will usually download in bulk. We compress each chunk separately so clients can download some chunks individually if that’s all they need.
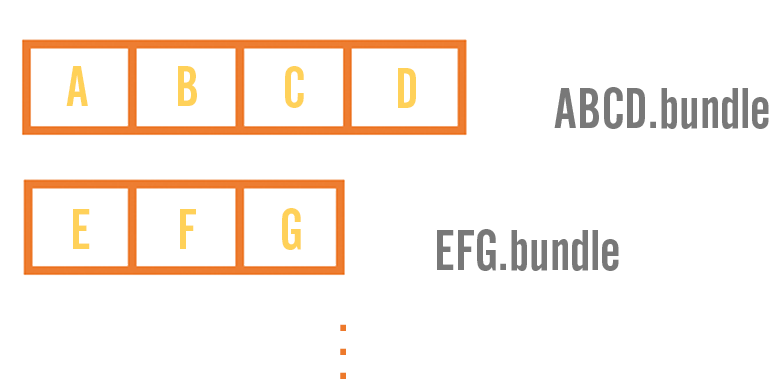
Bundling
Bundling is important for improving download efficiency. League consists of over 300,000 chunks, but we group them into less than 5,000 bundles. This means players can download the entire game using no more than 5,000 HTTP requests. If we stored each chunk separately on the CDN then players would need to make over 300,000 separate requests, each of them for a tiny amount of data. This would slow down updates due to the overhead of the protocol.
Bundles are named after their unique 64-bit identifier. We compute this ID based on the IDs of the chunks in them, so two bundles with the same contents will have the same name. This allows us to share a lot of files across versions, which helps keep those files cached on the CDN edge servers for longer. We can also skip uploading a bundle to the CDN if it already exists from a previous version. This improves patch generation speeds significantly, since we need to upload less data and don’t even have to bother compressing those chunks in the first place. Each version of League shares over 85% of the bundles with the previous version.
Writing the Release Manifest
Once we’ve finished bundling everything, the next step is to write the release manifest. The manifest stores information about all the files, chunks, and bundles that are part of a release and it’s about 8 MB. The manifest uses the FlatBuffers binary format to store this information, which allows us to load it very quickly on the client. We can also evolve the schema as needed while maintaining compatibility.
As a final step, we upload the bundles and the manifest via a large multipart HTTP POST to a C++ service called patchdata-service. This service runs in AWS and is in charge of deploying the data to S3, which serves as our global CDN origin. The service also performs a number of checks on the uploaded data to make sure it’s valid and then digitally signs the release manifest. Clients will only load a release manifest if it’s properly signed.
Putting It All Together
While it may look like a very sequential process, all of the steps described above actually happen in parallel. The patch generation process is built as a multithreaded pipeline. We feed the files to deploy on one end and bundled data starts arriving in S3 for the earlier files while we’re still chunking later files. The whole process takes only about as long as the slowest part, which is normally compression.
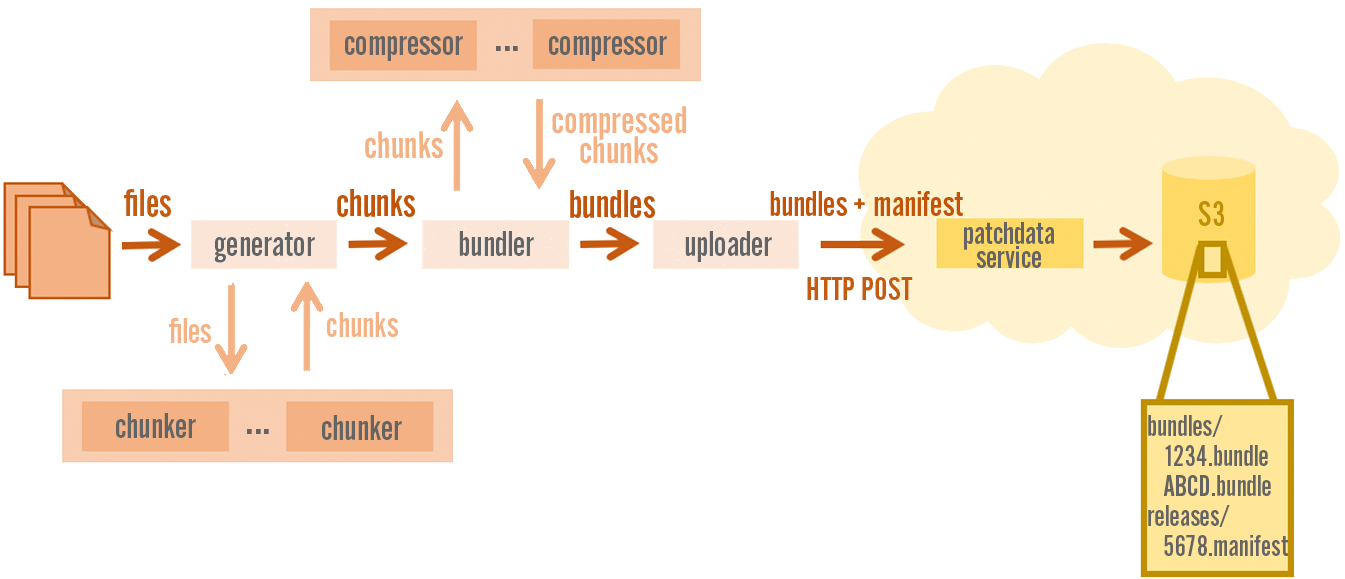
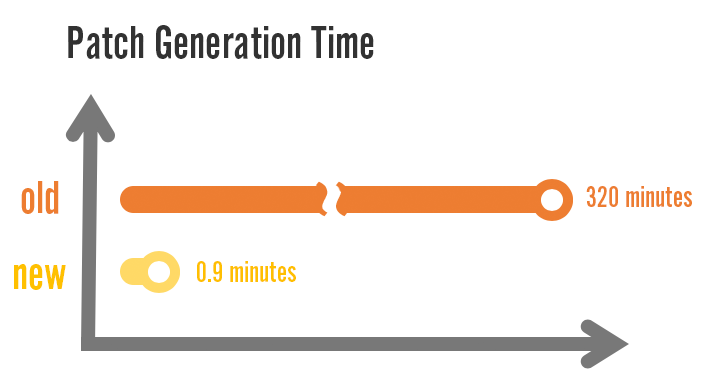
We can deploy a new version of League of Legends in less than a minute instead of the five hours it used to take, which is a massive win for our ability to get hotfixes out quickly.
Handling Downloads
The fundamental job of the patcher is to do whatever is necessary to transform the existing League installation to the desired state. This may involve downloading new chunks, updating existing files, deleting old files, and so on.
Preparing to Update
The update algorithm is always the same:
-
Figure out what we already have.
-
Find out what we need.
-
Download anything that we’re missing and transform the installation.
To know what we already have we use a small SQLite database. This database stores information about all the files and all the chunks that we have locally. We use this because it's fast, small, and provides great atomicity and transactional semantics and excellent corruption detection and recovery. These are important properties for us because we want to make sure that updating League doesn’t corrupt an installation or leave it in an inconsistent state, even in the case of a power loss.
We update this database every time we make a change to any of the files on disk. By storing this information in the database we can find out what we already have very quickly. Otherwise we’d need to scan all the game files every time just to see what we need to patch, which would be very slow. The database is basically used as a cache summarizing the contents of the game installation directory. Because it’s just a cache, we can always rebuild it if we lose it for some reason.
The schema is pretty simple:
> sqlite3 "C:\Riot Games\League of Legends\Game.db"
SQLite version 3.28.0 2019-04-16 19:49:53
Enter ".help" for usage hints.
sqlite> .schema
CREATE TABLE files (
path_id integer primary key check(path_id != 0),
path text not null check(length(path) != 0),
size integer not null,
timestamp integer not null,
permissions integer not null,
symlink text not null,
chunking_version integer not null,
min_chunk_size integer not null,
chunk_size integer not null,
max_chunk_size integer not null,
type integer not null
);
CREATE TABLE chunks (
path_id integer not null,
offset integer not null,
id integer not null check (id != 0),
size integer not null,
foreign key (path_id) references files(path_id),
primary key (path_id, offset)
) without rowid;Verification
Despite our best efforts, sometimes the database may not faithfully represent the contents of a League installation. For example, if some other software modifies League files or if someone deletes something in there by mistake, the database will no longer be accurate. This is why we always perform a quick verification process that determines whether something is obviously wrong with the installation. This process is very fast - on the order of 100ms - because it just needs to read filesystem metadata.
Every time a player launches League, we check that all the files are on disk and that they have the expected size and timestamp. While we can’t detect all possible problems such as bad sectors or a file modification that preserved the timestamp, this helps detect the most common issues. Going further and scanning the contents of all the files would be too expensive, so we only do that when a player selects the Initiate Full Repair option in the client.
If we detect that something is wrong with the database, then we run a repair process to rebuild it, which we’ll talk about later. For now, let’s assume that the database is accurate.
Updating
Now that we know what we already have, we have to find out what we need. This information is in the release manifest. With the manifest we can compare the list of chunks that we have with the list of chunks that we need and craft an update plan. The update plan captures all the steps that we’ll need to perform to update the installation to the desired state. We can use the plan to perform the update, or we can use it just to estimate how much we’d need to download or how much disk space we’d require.
With the update plan in hand we can start the update process. The most important part of the process is to update files on disk with their new contents, which we do in place. Performing the update in place means that we don’t need any extra disk space. It also reduces the amount of I/O that we need to perform by avoiding extra file copies.
Slicing
We update files in discrete steps by writing one slice at a time. A slice is a contiguous region of a file that needs to be updated with new chunks. The chunks can come from the CDN if they’re new to the latest release, or they can come from existing files on disk if we already have them somewhere. We assemble all the chunks we need in the right order into a memory buffer and then write out the buffer to disk with a single large write.
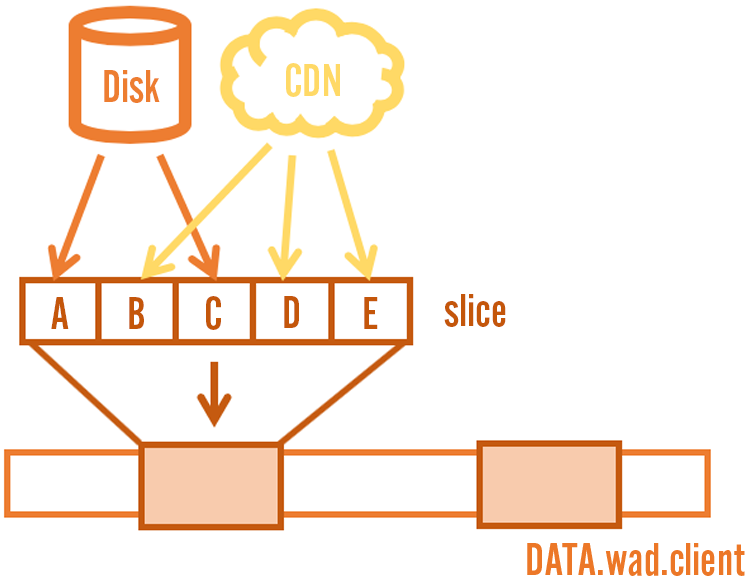
Slices are up to 64 MB in size and they always start and end at chunk boundaries. We limit the size of a slice so we don’t use too much memory when updating very large files.
After writing each slice we update the database with the information about the new chunks that now occupy that space. This makes it easy to safely cancel the update in the middle because the installation is always in a known state, even if it’s not fully updated yet. The next time a player launches the client, the patcher knows exactly what’s left to do.
Downloading
While we’re busy writing new data to disk, we’re also downloading the chunks that we’ll need from the CDN. We download chunks in the order that we’ll need them and we always try to run slightly ahead of the writes to disk. We limit the amount of chunks we’re downloading to 128 MB so memory usage doesn’t grow unbounded in case the disk is very slow and the connection is very fast.
We use 8 concurrent HTTP/1.1 connections to download chunks in parallel, which helps improve speed and avoid head-of-line blocking. We don’t currently use HTTP/2 because libcurl - which we use for downloads - has some known issues that would impact our download speeds, and it wouldn’t help with head-of-line blocking at the TCP level anyway. We think HTTP/3 would allow us to use fewer concurrent connections thanks to the QUIC protocol, so we’re excited to try that out when it becomes widely available.
We ran a series of A/B tests and found that 8 connections appears to be the sweet spot for us, more than doubling download speeds for many players compared to a single connection:

Over those HTTP connections to the CDN we send a series of multipart range requests to download the chunks that we need. If we need all the chunks in a given bundle then we can download the whole thing, but if we only need some of them then we’ll send a range request to retrieve the appropriate byte ranges. Asking for multiple ranges helps reduce the number of HTTP requests we make when we need a lot of discontiguous chunks.
We try to spread out the HTTP connections so we’re always downloading from multiple CDN edge servers at the same time, or even multiple CDN providers if possible. This makes the patcher more resilient to problems with a given edge server, and helps it find the fastest CDN providers in each region. Every minute we query DNS to get the most up-to-date list of servers available and try to spread out connections that way.
We also retry failed requests aggressively. We don’t consider any network error to be fatal and will keep retrying with a delay as long as necessary, though we cancel updates if we’re unable to make any progress after a couple of minutes. This helps the patcher ride out temporary connectivity issues and complete the update in many instances where RADS would have previously given up.
Repairing
Sometimes things don’t go according to plan. The update process assumes that the contents on disk match exactly what’s recorded in the database. When they don’t, we first have to fix that. We call that a repair.
The repair process is super helpful to proactively fix problems with the installation that would otherwise cause the game to crash later. A full repair takes less than two minutes on average, and much less with a fast CPU and an SSD.
Partial Repair
The first kind of repair happens when the verification process detects that there’s a mismatch between the database and disk. We call this kind of repair a partial repair, because it only needs to scan the files that appear to be inconsistent. Some files may be missing from disk, or they may have the wrong size or timestamp. If a file is missing then we simply delete its records from the database, since clearly we no longer have those chunks. We then gather the inconsistent files and rechunk them to rebuild the list of chunks they contain. Rechunking is simply running the content-defined chunking algorithm over those files. We then update the database with the list of chunks that we found, at which point the database matches what’s on disk again.
Full Repair
The other kind of repair - a full repair - happens when the patcher is happily updating the installation but then encounters a problem that it can’t handle. For example, it may be trying to read an existing chunk from a file but the file is unreadable. Because it’s possible that this is not the only problem with the installation, we rechunk all of the files to see what else might be wrong. If a file is unreadable then we delete it so we can redownload it later. When the full repair completes we have a new database that faithfully matches what’s on disk.
Results
We put a lot of effort into using machine resources efficiently. Network I/O, disk I/O, and CPU usage are all overlapped whenever possible. We also changed our data packaging process to ensure a stable file layout across versions, reducing the amount of disk I/O needed. Coupled with our fundamentally simpler algorithm, the end result is an update process which is much faster than what we had before.
We compared game update times for each type of patcher - RADS and our content-defined chunking patcher - using patch 9.9. For context, these times basically represent how long a player has to wait before they can actually play - including the time to download new data and the time to apply the updates to files on disk.
The patch size was 68 MB for RADS and 83 MB for the new patcher. Despite the larger download size, the average player was able to update the game in less than 40 seconds, compared to over 8 minutes with the old patcher.
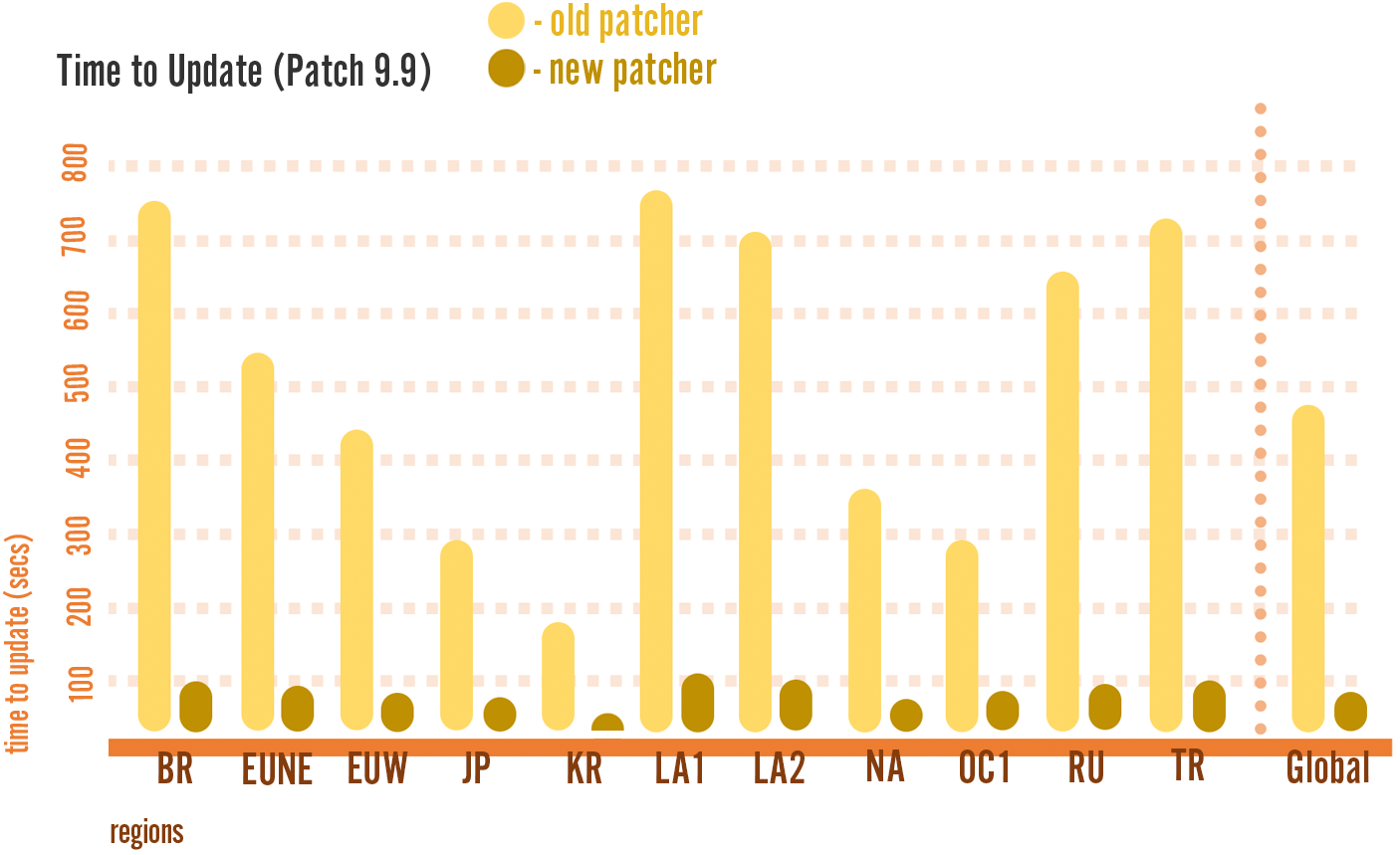
Depending on the region, players saw update speeds that were up to 14 times faster than before:
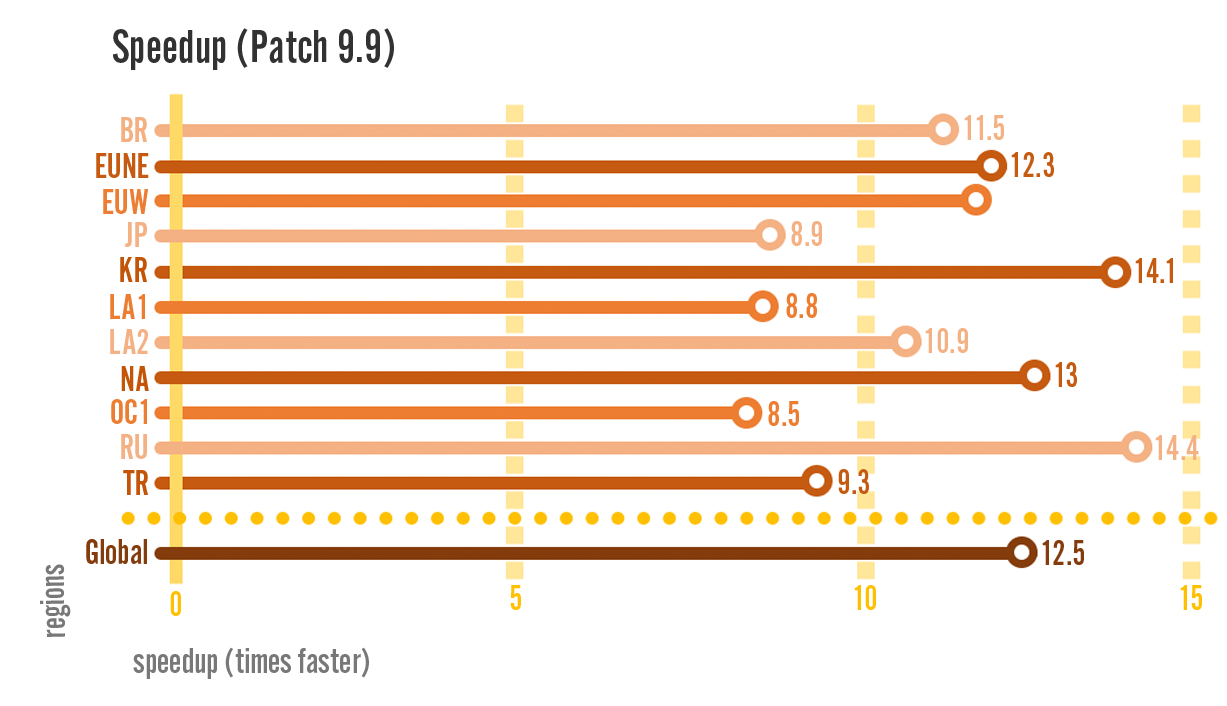
Updates were consistently faster across all the regions and percentiles that we checked.
While having fast updates is great, it wouldn’t be worth it they failed so frequently that players can’t actually get in game. We were happy to see that the rate of update failures - that is, the percentage of players who encountered an error while updating - was also reduced significantly.
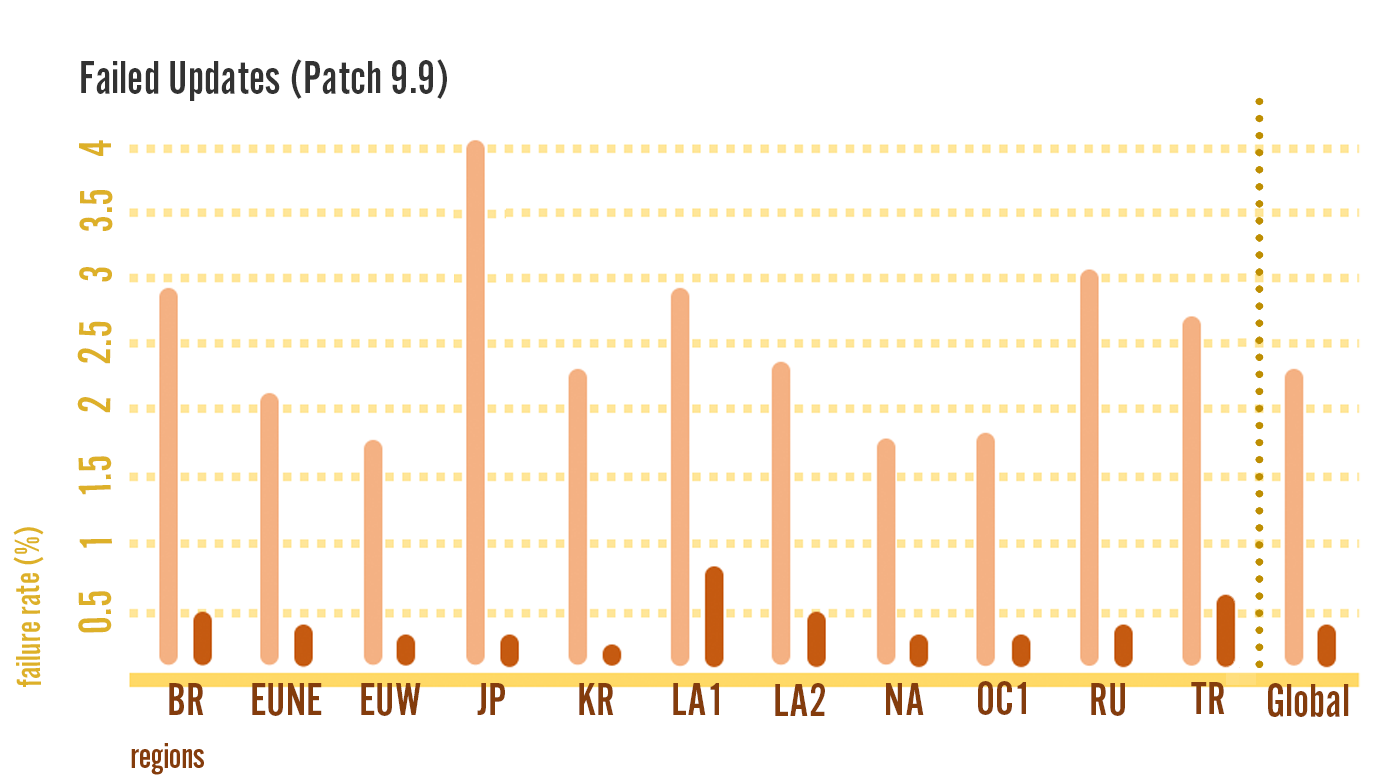
The failure rate dropped from 2.2% to 0.3%, with the majority of the remaining failures being connectivity issues. Put another way, players saw up to a 95% reduction in errors depending on the region.
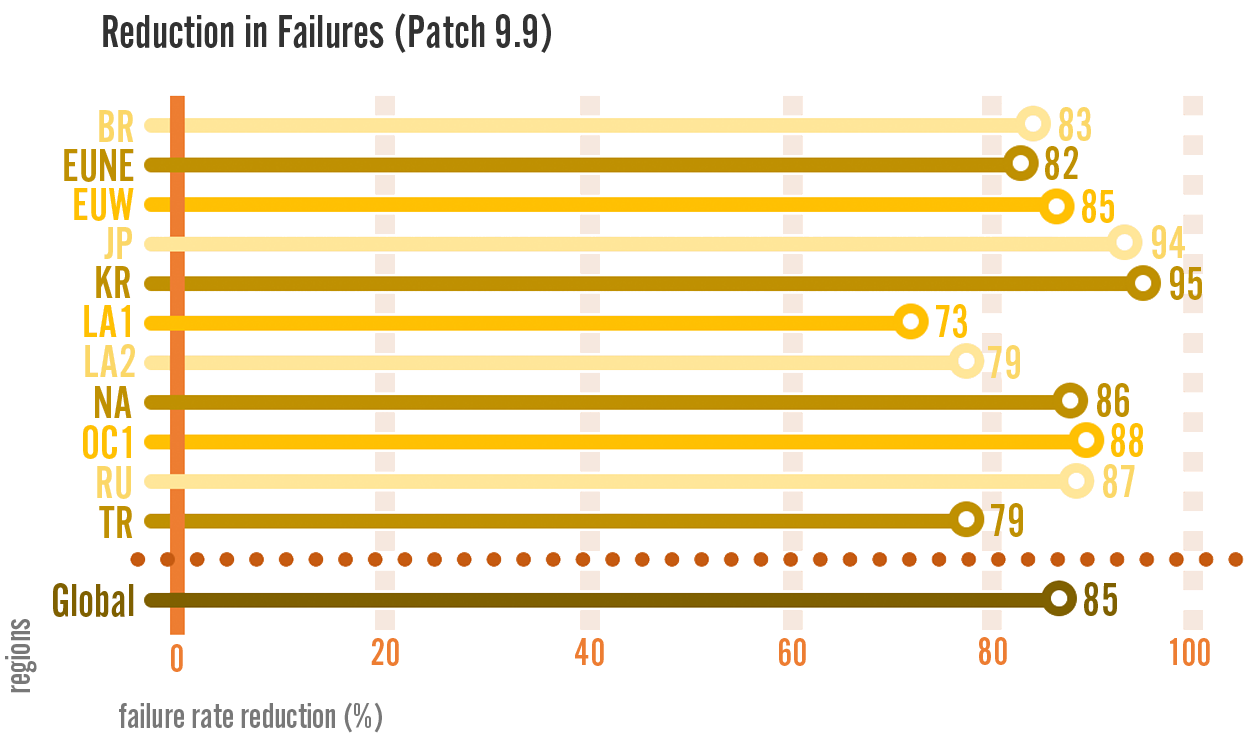
These results validated our assumptions that we could improve the patching experience with a new patcher.
Conclusion
Our RADS patcher did its job admirably for a long time, but by completely rethinking our approach to patching using content-defined chunking we have enabled a level of performance and reliability we’ve never seen before. We’re really excited about how much this has improved the player experience, and how this will make it much quicker for both new and existing players to get in game. We will continue improving the tech with everything we’ve been learning about distributing game content to a worldwide audience.
Thanks so much for reading! If you have questions or comments, feel free to post below.