
Stocking Your Shop With Data Science
Hey there, my name is Riley “WhoaNonstop” Howsden, and I’m a Data Scientist who works on League of Legends, focusing mainly on personalization. Over the last few years I’ve been a part of the launch team for “Your Shop,” a product within League that creates personalized offers for every player around the globe.
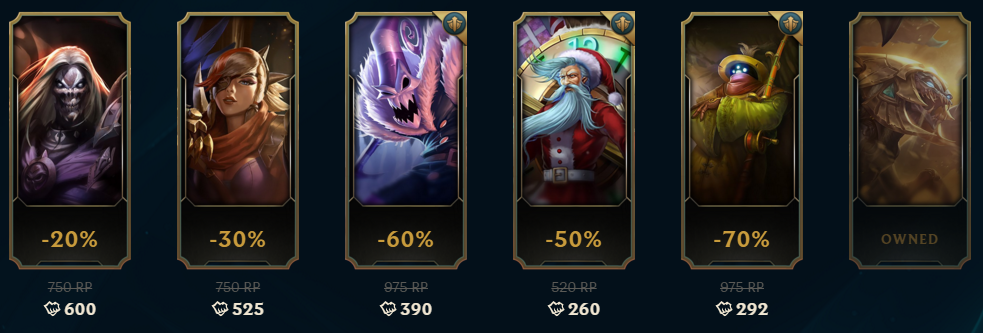
My Shop!
Data scientists like me work with engineers, analysts, artists, and publishing to create experiences that players love. From matchmaking and player behavior to artificial intelligence and game balance, data science is a key contributor for many initiatives at Riot. This article will dive deep into one data science-fueled product - Your Shop - but be on the lookout for more data science-infused articles in the future!
Our vision for personalized offers has always been deeply rooted in providing a unique experience for players to help them engage with and enjoy League content; this means connecting players with the champions and themes that appeal to them.
There have been many theories about the machinery behind Your Shop. This article only touches on some of the underlying work that has been done, but I hope it gives you a taste of what we have explored and how we're constantly iterating to keep the offers in Your Shop intriguing.
Context on recommender systems
Over the last decade, recommender systems have become a mainstay of modern data science. They've permeated a multitude of products such as movie recommendations on Netflix and shopping suggestions on Amazon. If a product is creating a personalized view just for you then there’s likely a data science algorithm in the background powering it. The methods behind Your Shop take advantage of the conventional machinery found in other popular recommender systems, specifically collaborative filtering techniques. These algorithms carry out the general task of creating the top-N recommendations for each player.
We’ll start by talking about the underlying data and the type of recommender systems, and then move on to the algorithms we’ve focused on here at Riot and how we evaluate them. Finally, we’ll touch on how we generate the offers using a distributed computing framework and finish with details on how the offers get to players in every region.
Recommender system data structures
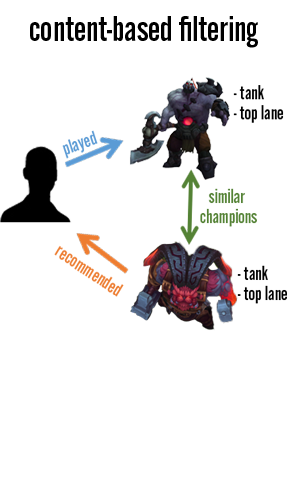
Recommendation systems fall under one of two categories, which, in general, are defined by the kind of data they’re built on. For collaborative filtering methods, user-item interactions are the underlying source. In contrast, content-based recommender systems focus on tagged attributes of the users and items. We use a variety of collaborative filtering techniques, but in an ideal world, we would have a hybrid system that leverages the strengths of both methods.
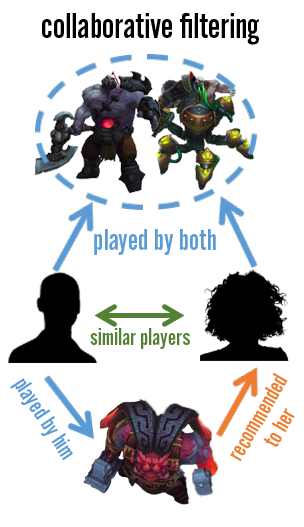
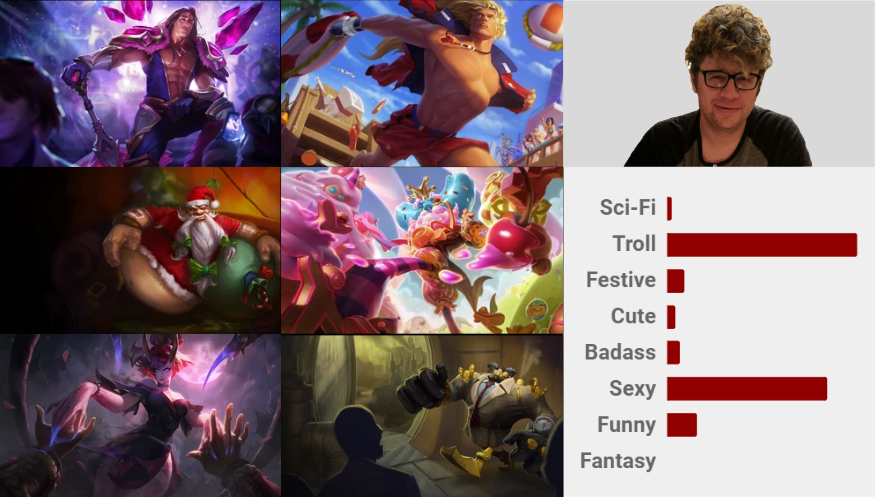
For a content-based system to work, a specific skin would have multiple tags that describe various features of the content; this could be anything from “funny” to “cute” to “edgelord.” In the same light, champions would have labels as well, from basic role categorizations (“ADC,” “Support,” “Mid”) to damage type to humanoid/monster breakdowns. As players start to build up a catalog of content that they own and play, they would start to inherit the traits of those items to create a unique player profile. This profile, along with item features, could be used to rank content that a player would prefer.
While we could dive deeper into content-based systems, Your Shop has historically been powered by a range of collaborative filtering techniques since they do not rely heavily on a robust tagging infrastructure, which is something we’re still working on. Our tagging system isn’t quite consistent enough for a content-based system just yet, so our focus is on rankings developed under the collaborative filtering setting.
Collaborative Filtering
Under the umbrella of collaborative filtering, there are two classes: neighborhood-based and model-based. These methods each have pros and cons, but the general trade-off lies between computational efficiency and recommendation accuracy. Filtering methods based on item neighborhoods incur a lower computational cost while generating the recommendations, but the quality of these recommendations is usually lower. On the other side of the spectrum, model-based methods lack speed when generating recommendations but have been shown to achieve the best performance on large recommendation tasks.
Regardless of the class, the fundamental data structure fed into these algorithms is the same - a utility matrix of users and individual scores for content they've interacted with or purchased. It’s important to note that this matrix is usually sparse; most of the user-item interactions have not been observed as most players only interact with a small subset of champions. Therefore the matrix is missing many values. Here's an example:
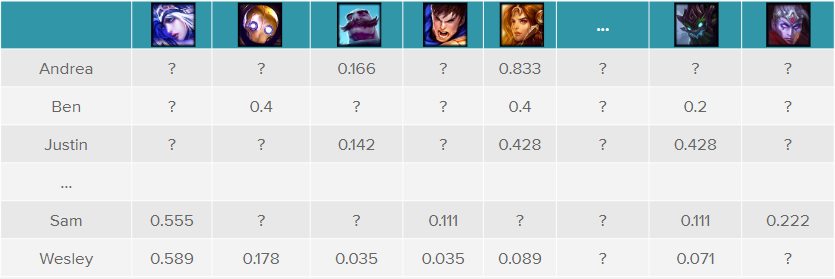
The obvious question is: How are these player-item scores calculated?
For many products powered by recommender systems, these scores are explicit - the user has given a rating on the item and no further work is needed to approximate the user’s preferences. While owning content and playing games are signals of player affinity, these indicators are implicit and therefore, care needs to be taken during inference. There are many random components within League that would affect accuracy if they were ignored - for example, randomly acquiring content through the Hextech Loot system can blur the signal. Alongside that, there are game modes in League where champions are chosen at random, such as ARAM. Other game modes may force a choice amongst a subset of champions and skins, such as Odyssey and Star Guardian. In these situations, the player is likely not explicitly expressing a deep interest for a particular champion or skin.
Another challenge that makes the recommender system problem unique in League is the hierarchical ownership structure for content. Every skin in League is embedded under a specific champion, and this coupling opens up the problem to both champion-level and skin-level effects. This is resolved by either training the algorithms in a similar hierarchical fashion or attempting to combine the information across both pieces of content into the same recommender.
Speaking of algorithms, let’s get into those!
Algorithm overview
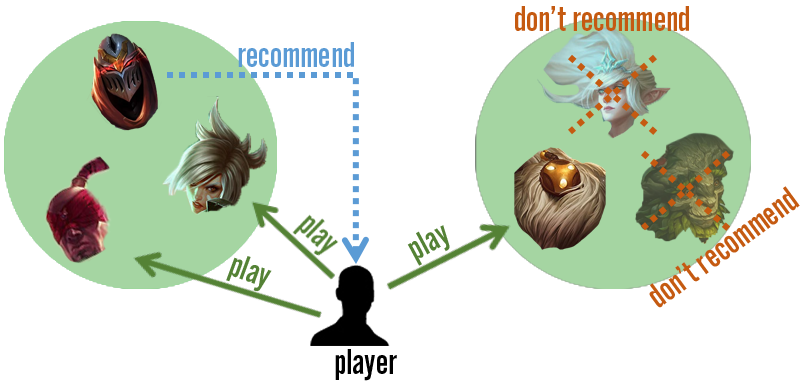
While the matrix above is an important piece of the puzzle, it alone does not generate the final recommendations a player sees. As hinted at earlier, collaborative filtering techniques benefit from pooling information across all players. The intuition here is rooted in the fact that similar players have similar preferences and that a piece of content is in the same “neighborhood” as related items.
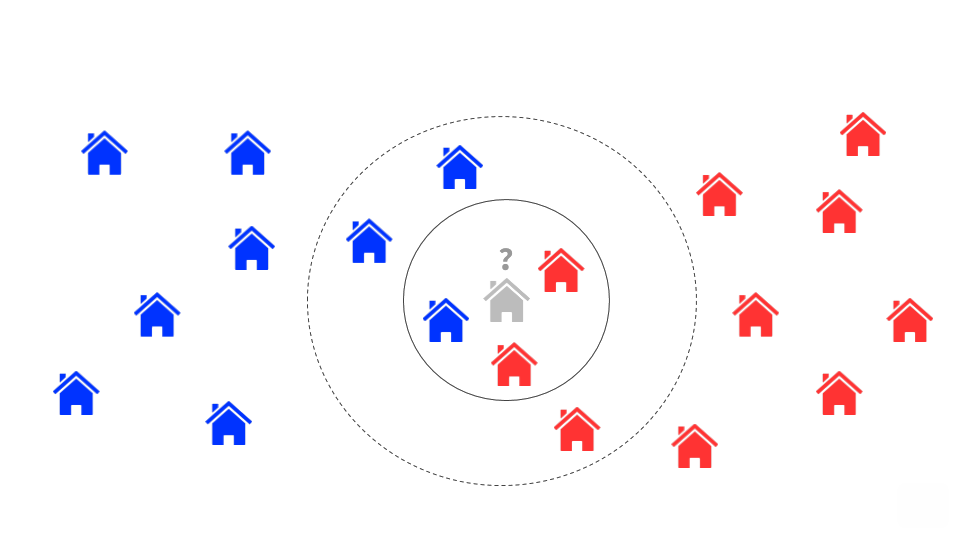
Neighborhood-based methods
The concept of a neighborhood implies that we need to determine either similar players or similar items in order to make future predictions. Player-based models leverage similarity between players; if two players, Andrea and Ben, exhibit similar scores, then one can use Andrea’s inferred ratings on the champion Zed to predict Ben’s unobserved rating on the same champion. Similarly, item-based models take advantage of similar items that are rated in a similar way by the same user; Ben’s ratings on similar champions like Riven and Lee Sin can be used to predict a high score on another similar champion : Zed.
Champions exist in neighborhoods, some closer than others, which inform what recommendations are made.
In order to determine the similarity between players or items, a distance metric must be calculated between the two. There are a variety of ways this can be carried out; one of the more popular metrics is cosine similarity, which can be derived using the Euclidean dot product formula:
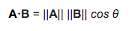
This takes two vectors from the utility matrix, either rows (player-player) or columns (item-item), and calculates their similarity:
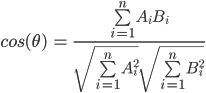
The results for this formula will output weights that range from -1 to 1, where negative values indicate dissimilarity and positive values indicate similarity. These weights can then be used to determine approximate scores for those that are missing in the matrix. If Andrea and Ben have an observed score for a piece of content while a third player has a missing score, a weighted average of Andrea and Ben’s scores can be used to determine the score of the third player. Extending this to a large population of players, we can create “neighborhoods” of similar players and infer what the missing values are for many champions.
Dimensionality Reduction - Matrix Factorization
While the neighborhood method described above is intuitive and easy to implement, it does have a few key weaknesses. One disadvantage is limited coverage due to sparsity; most players only interact with a small portion of champions and skins. This weakness arises due to the fact that neighborhood methods are forced to choose between pooling information across the columns (item-based) or the rows (user-based).
In order to combat this issue, we use dimensionality reduction techniques to compress the information. These are also known as matrix factorization methods as they decompose the larger utility matrix into two smaller matrices. In general, this creates a richer neighbor network. The intuition behind this is that as a player population, our preferences for content aren't as uniquely complex as the raw ratings matrix may suggest. The raw ratings can be remapped to a lower number of dimensions, k, that can still explain a significant proportion of player preferences.
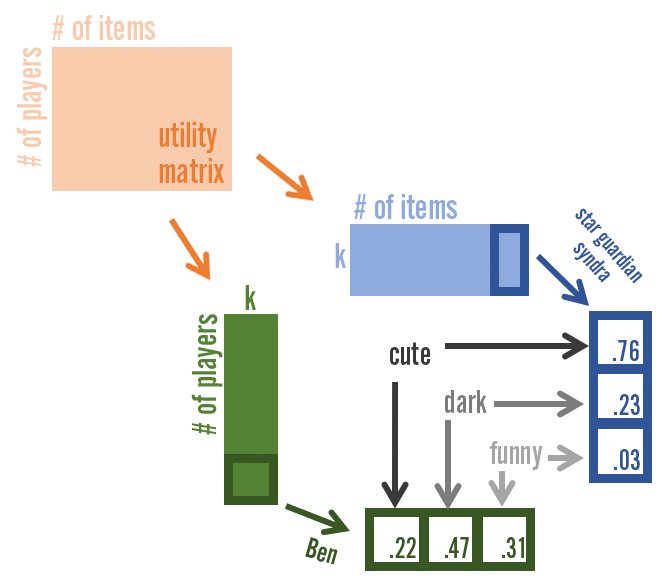
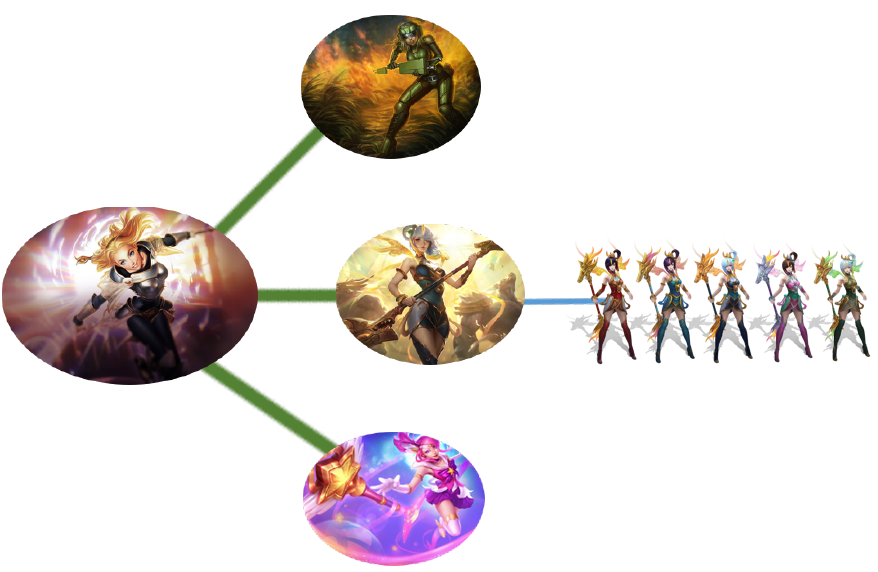
For instance, while there are over 140 champions in League of Legends, it is likely that characteristics of those champions can be compressed to a smaller dimension that retains most of the information. To oversimplify, these dimensions might represent tank, mage, bruiser, or assassin and each champion would have different weights across these dimensions. In this latent space, Zoe would likely have a higher weight in the mage dimension, a moderate weight in the assassin dimension, and no weight in the bruiser or tank dimension.
In the image above, we can decompose the number of players by the number of items matrix into two smaller matrices that have the same lower dimensional latent space, k. While in theory these dimensions are complex and not tangible, for representation’s sake we have set k equal to three and labelled these dimensions as “cute,” “dark,” and “funny.” Both the item and player are characterized by this low-dimensional space and we can construct the player’s score for each item through matrix multiplication.
Sparse Linear Models
The newest algorithm we have implemented is based on an item-item regression that embraces sparsity in the regression coefficients with the use of regularization methods. These models are known as Sparse Linear Models or SLIM. The simplest way to think about this starts with the general linear regression structure:
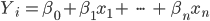
Here, the rating of an unowned skin is determined by a linear combination of owned skins and their weights. In essence, this means a linear regression is trained for each piece of content in the game. These models, alongside each player’s ownership profile, determine the rating for each unowned skin for that player. The only missing piece left to explain is the regularization component, which is an additional constraint added to the regression that encourages a majority of the beta coefficients to be shrunk to 0. The intuition here is that, for each item, only a small number of remaining items are important towards the rating of the item being scored. For instance, the model for Beemo would likely have non-zero coefficients only on other Teemo skins, Beekeeper Singed, and a few close neighbors. In general, this regularization ensures that models aren't overfit to noise in the data and the sparsity across coefficients makes scoring items more computationally efficient.

Evaluating recommendations
When launching any of the above models, we need high confidence in the recommendations it generates. In order to measure the effectiveness of a recommender, we evaluate a variety of metrics. Without context, conversion rate and accuracy are likely to be classified as top priorities. However, while accuracy is arguably the most important component, secondary goals such as coverage, novelty, and serendipity are essential as well. We’ll discuss each of these briefly.
Coverage encapsulates how many users will receive recommendations. Even if a recommender system is highly accurate, it may not be able to ever recommend to a certain proportion of players. For example, if a player’s rating matrix is mostly empty because they are new to the game or haven’t played in quite some time, then their offers are usually replaced by a default set.
On the other hand, novelty evaluates the likelihood of a recommender system to provide offers that the player may not be aware of. This allows the player to discover additional information with their own likes and dislikes, which is more important than discovering items that they were already aware of but do not currently have a score for. Novel systems are better at recommending content that will be selected in the future rather than at the present time.
Similar to novelty, serendipity refers to recommendations that are unexpected. Imagine a player who likes to solo lane Riven. Even if the player hasn’t had the chance to try Renekton, a recommendation to play him would be classified as novel as it is still expected. However, a recommendation to play Vayne might be seen as serendipitous, since it is somewhat unexpected by the player. This is because on the surface, Riven and Vayne don’t seem to share the same characteristics - but hidden underneath, their player bases are very similar.
Overall though, accuracy, which drives conversion rate directly, is the most important. Since most algorithms have similar coverage, the balance between accuracy, novelty, and serendipity are the focus of our systems. Accuracy has better short-term effects, as players are shown content they want now and the consensus is that novel and serendipitous recommendations have long-term effects on the entire system. The instinct here is that offering a skin on a champion that a player doesn’t currently play opens the door to a more diverse champion pool and a broader experience with League.

Distributed Computing and Productionalization
Everything mentioned above works well in theory, but scaling the system to millions of players introduces its own challenges. One quick solution is to sample player data down to a reasonable amount so we can train the algorithm on a single machine. Unfortunately, we’ve observed that this decreases the accuracy of the recommender beyond an acceptable level. We need a scalable solution to ensure the best experience for players.
Enter cluster computing. In order to generate offers, we run distributed versions of the above algorithms on Apache Spark through clusters that are managed by Databricks. Databricks allows us to set up our entire production pipeline through a network of Python notebooks while Spark allows us to allocate data across many nodes for calculations.
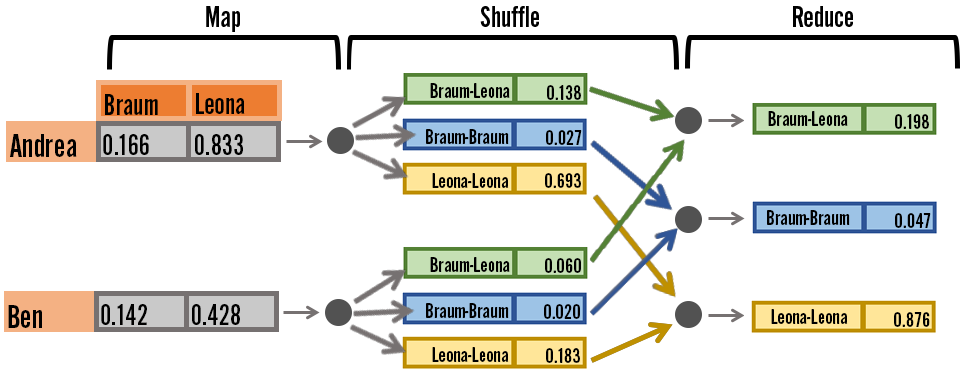
We use MapReduce, a common cluster computing model, to calculate data in a distributed fashion. Below is an example of how we calculate the cosine similarity metric - user data is mapped to nodes, the item-item metric is calculated for each user, and the results are shuffled and sent to a common node so they can be aggregated together in the reduce stage.
It takes approximately 1000 compute hours to carry out the entire offer generation process, from snapshotting data to running all of the distributed algorithms. That’s 50 machines running for 20 hours each.
Launching Your Shop
So how do we actually populate Your Shop and make it available to players?
The whole process starts well before Your Shop opens for business and the icon shows up in players’ clients. We run the algorithms a few days in advance so we can ensure that all of our evaluation metrics are satisfactory and that we have produced a solid set of recommendations for players. We store the resulting datasets in a bucket which is then uploaded to our Your Shop services, where we have deployments across the globe. Once Your Shop is activated, the service loads in the suggested recommendations as players turn over their cards.
During this process, we keep an eye on the telemetry reflecting which recommendations were successful, so we can use it to inform future suggestions. This allows us to pinpoint possible errors and measure the overall success of the system so we can make future iterations with an even better experience.
Conclusion
Thanks for reading! Moving forward, we’re setting up a tagging pipeline so we can start to explore content-based algorithms as well. Eventually, we plan to merge that system with the current collaborative-filtering algorithms to create an even better system for generating accurate and novel recommendations. We want players to get a shop they can get hyped about!
If you have any questions about recommender systems, Your Shop, or data science at Riot, feel free to comment below.
Like everything at Riot, this article was a team effort. I wanted to take a second and thank everyone who worked on Your Shop, and specifically Wesley Kerr, Ted Li, and Stefan Sain for their contributions.