Running an Automated Test Pipeline for the League Client Update
Hi, I’m Guy Kisel, and I work on the League client update’s Test, Build, and Deploy team, here to talk about the project's automated testing.
If you’ve ever used the current League client (the “AIR” client) you’ve probably encountered some odd bugs. While those issues are rare, you still might have thought “wtf Rito, how did this possibly go live,” and you would be totally justified in doing so - that experience simply does not meet the quality bar we want to deliver to players. The previous article on the client update’s architecture covered our decision to use AIR when developing the original client - it supported rich multi-media effects that simply weren’t possible in HTML at the time. However, the sad truth is that the AIR client has limited automated testing coverage. Developing and releasing updates is a slow and risky process because changes must be manually tested - a time consuming and inconsistent process. Ideally, we’d let machines test the boring, repetitive stuff, and let humans do more creative types of testing (more on this in Jim’s recent article).
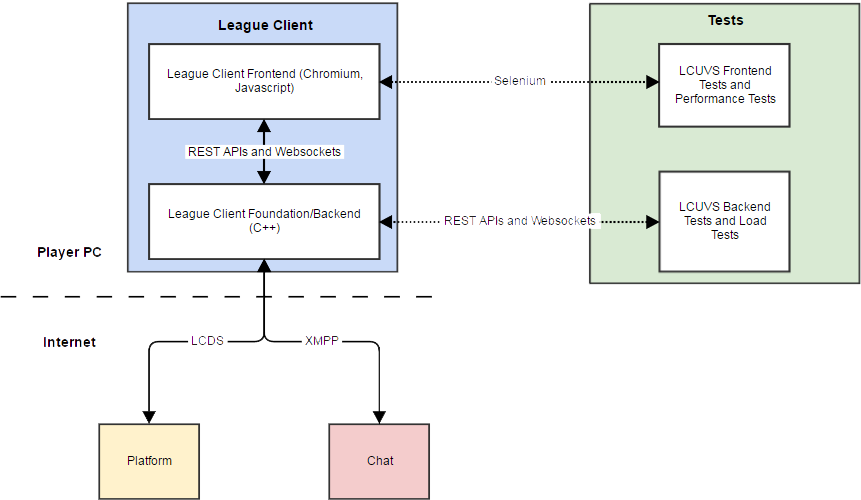
One of the core goals of the League client update is to enable robust test automation so we can give players the high-quality experience they deserve. The client update’s architecture involves a Chromium-based frontend and a C++ backend that provides REST APIs and websockets for communication. This architecture provides us with two convenient automation interfaces: for the frontend, we can use ChromeDriver, the Chrome-specific implementation of the industry-standard Selenium WebDriver protocol. For the backend, we use open source HTTP request and websocket libraries. These are among the most common automation interfaces on the planet, so there’s no need for us to implement custom test automation drivers. Our functional tests are implemented and run using Cucumber.js.
These are all common tools with abundant documentation, so in this article I’m going to focus on our process and pipeline rather than on our tools. I hope it will be helpful to anyone approaching a similar automation challenge.
Culture
Successful test automation is largely a matter of culture and psychology. Technology plays a secondary role.
No matter how much technology we have, we still need to encourage the right human behaviors in order to make automated testing a success. Every time a test fails, a human has to look at it and decide whether it’s a real failure in the project being tested, a poorly written test that’s misbehaving, or some sort of other environmental or infrastructure issue like a network glitch.
A traditional test automation strategy is to have a quality assurance team maintain responsibility for developing and running tests. This approach has merits - you end up with subject matter experts who fully own the test system. It’s often well-suited to projects with long release cycles, since immediate feedback isn’t nearly as important if your team only tests a new build once a week. Additionally, there are benefits to specialist test engineers who can spend their time designing intricate test cases that thoroughly exercise each build. I asked our splash artists to visualize this process:
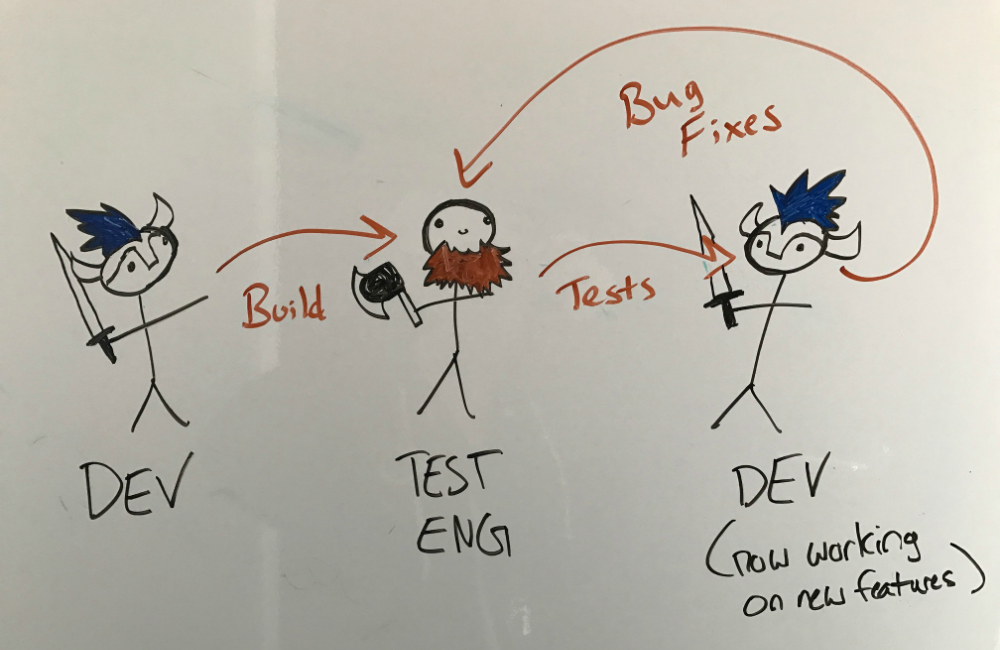
There are also significant drawbacks, however. When the development team doesn’t run tests themselves, or pay close attention to the results, they tend to adopt a “throw it over the wall” mentality. The feedback loop for devs learning of their failing code tends to be slow, which isn’t acceptable. The League client update moves extremely fast - the primary development environment receives a new build every 15 minutes, all day long. At that speed, immediate feedback is crucial. Even if the tests themselves execute quickly, we can’t wait on a developer waiting on test engineering to interpret the results. Team efficiency is one of our core goals, so traditional test automation just wouldn’t work for us. Our approach looks like this:
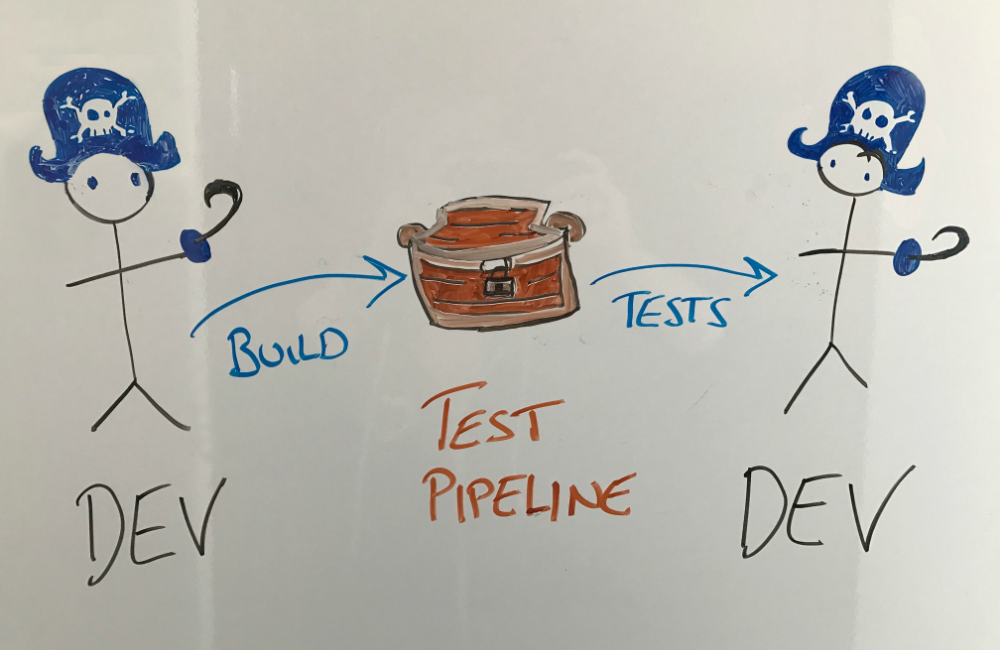
Our philosophy is to make testing and automation a fundamental concern for the entire team. Every developer has to be involved. Our standard project onboarding process includes detailed documentation on how to write and run tests, and we make it clear to developers that they’re expected to fully own their code’s unit tests, functional tests, performance tests, and load tests. The Test, Build, and Deploy team is focused on building and maintaining the test tools and infrastructure, but this team doesn’t write the tests themselves - that’s a responsibility of the individual feature teams.
We’re now at a point where teams working on the League client update are quick to respond and investigate when tests fail. However, reaching this point has been difficult. Learning how to cope with flaky tests has been the most consistent struggle.
Our original workflow was something like:
-
Notice a test is occasionally failing
-
It’s only occasionally failing, so it’s probably less urgent than other broken stuff; ignore it for several hours or days
-
Eventually start investigating, check in a fix if indeed the test is at fault
The result: the team starts assuming that any failure is probably just a flaky test, and all results are ignored. If the team has no confidence in the test system, the system is worthless. If your car’s check engine light randomly turned on, you’d probably start to ignore it. To prevent this type of habituation, our current workflow is to immediately investigate a failing test to determine whether the test has gone rogue or we’ve found a legit bug.
Broken tests are moved to our staging test suite to keep the signal-to-noise ratio of the full test suite as high as possible. The staging suite runs outside of the normal build pipeline in order to test the tests. New or refactored tests are placed in staging for a few days to ensure that they’re robust before we accept them into the full suite where they can notify developers of failures and block deploys.
We continuously reinforce the importance of keeping our tests and builds healthy through in-person discussions, standup announcements, and team-wide emails. Any discussion of bugs or tests is a great opportunity to (politely) evangelize automation. Every team periodically gets into a “must ship” mentality and begins downplaying the importance of testing, and it’s natural to sometimes get frustrated with testing requirements. Of course, we have to be careful to find the right balance between no reminders and too many reminders - in either extreme, nobody gets the message. This may need special attention when remote teams are involved.
These cultural attitudes are not one-size-fits-all. They have to be carefully tailored to fit the project and the people involved. The most important part is to take nothing for granted and make no assumptions. There’s always room for improvement - we constantly keep an eye on how smoothly the system is working and make tweaks as needed.
Technology
Test frameworks and test tools are largely interchangeable, but the design of the pipeline itself is critical.
Over time, our continuous delivery pipeline has evolved into a multi-stage process that gradually applies increasingly broad test coverage. Initial tests are narrowly tailored, so mistakes made by a single team are likely to remain localized - allowing other teams to proceed with their own development. Stages that affect or block the entire project are near the end of the pipeline to reduce the risk of one team’s narrowly-scoped problem affecting everyone else’s productivity. We use a plugin-based architecture for client functionality, and before a plugin even gets built we run plugin-specific unit tests. Later, we run a brief end-to-end smoke test against a plugin in isolation. Finally, before allowing deploys, we run a comprehensive test suite against the fully assembled client. For example, with champ select, we might first just run some very basic tests such as “champion icons exist," and then later run more complex tests involving champion trades, ward skin selections, and more.
There are a number of problems that can arise from an inadequate test pipeline. I can’t possibly list them all, but these are a few we’ve addressed:
-
Tests run too slowly
-
Tests don’t have any direct impact on the release process
-
Test failures in one feature block development of other features
-
Tests don’t run in a realistic environment
-
Manually created/maintained test jobs aren’t version controlled and become a huge maintenance burden
-
Keeping tests up to date when features change can be difficult
Thanks to the League client update’s plugin architecture, we can build each plugin individually. The plugin build process includes running static analysis and unit tests. A plugin only becomes a candidate for integration into the rest of the client if it builds successfully. Once a new plugin build is released, it enters a Last Known Good (LKG) stage. In this stage, we take a manifest of the LKG versions of every other plugin, add the newly released plugin version, and create a temporary build of the client. This temporary build is then run through a limited suite of the functional tests to make sure the new plugin plays nice with the existing plugins. If the plugin passes the LKG test, the LKG manifest is updated with the new plugin version, and we continue to the full functional test suite using the new LKG plugin manifest. This suite actually has two sets of tests—smoke tests and full tests. The smoke tests guarantee a minimal level of functionality, while the full tests cover as much functionality as we can reasonably test automatically. Builds that pass each set of tests are then tagged in our build tracking database. Obligatory diagram:
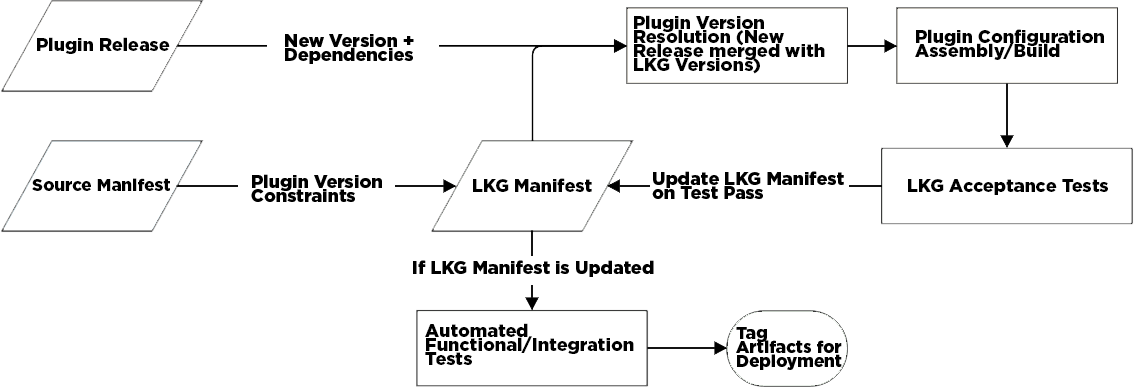
For speed and convenience, we run our frontend plugin build jobs (including the unit tests) in Docker using our containerized Jenkins farm. However, the client itself only runs in Windows and OS X, meaning we can’t run realistic functional tests in Docker (until our internal infrastructure has production-ready Windows Docker support). Instead, we run our Windows and OS X functional tests in regular virtual machines. This means that all of our tools have to be cross-platform and all of our jobs need to have both Windows and OS X versions. To easily manage many similar jobs, we’ve programmatically defined our pipeline using Jenkins Job DSL. Our job configurations are stored as JSON (snippet below). These configs are then fed into Groovy scripts that generate our entire pipeline in one go, including build jobs, test jobs, and deploy jobs.
“lcuvs_builds”:[
{
“product”: “lol”,
“application_stack”: ”Backend”,
“test_suite”: “EnvTest-Auto2”,
“publish_results”: false,
“platform”: “win32”,
“plugin_configuration”: “next_release_dev”,
“label”: “LCU&&Windows&&TEST”,
“create_for_release_branch”: false,
“environment”: “Auto2”
},
{
“product”: “lol”,
“application_stack”: ”Frontend”,
“test_suite”: “Full”,
“publish_results”: true,
“platform”: “win32”,
“plugin_configuration”: “next_release_dev”,
“label”: “LCU&&Windows&&TEST”,
“create_for_release_branch”: true
},
{
“product”: “lol”,
“application_stack”: ”Frontend”,
“test_suite”: “Full”,
“publish_results”: true,
“platform”: “mac”,
“plugin_configuration”: “next_release_dev”,
“label”: “LCU&&OSX&&TEST”,
“create_for_release_branch”: true
},Initially, we had a hard time with functional test ownership. Teams were doing most of their development within their plugin repositories, while functional tests were stored in a completely separate repo. Teams would often make changes to their features within their plugins, but then forget to update their tests. We broke up the monolithic repo that contained all of the functional tests and moved the tests into their respective plugin repos, which gives teams immediate access to their tests during development. The test harness now has a “test acquire” feature, where it crawls the dependency tree of the plugin manifest and downloads the appropriate tests for the given set of plugins.
Simply identifying common pain points and attempting to solve them goes a long way towards good pipeline design. It’s nearly impossible to build a fully featured pipeline from the start - our early system had only a handful of simple manually configured jobs that didn’t do much. Two key principles allowed us to iterate and improve our pipeline to reach its current state. First, we started using Job DSL very early on, before it was even absolutely necessary. Second, we’ve kept the jobs modular - most of the jobs take the same parameters, so we can switch them around as necessary. When rewiring the jobs is relatively easy, we have the power to continuously improve instead of being locked into one design.
Plans for Improvement
The team and pipeline continue to evolve. Here’s our current to-do list.
Test speed improvements
We’re currently using multi-cuke to parallelize our tests within a given job run. This still limits us to the capacity of a single build node, and vertical scaling only goes so far - the next step is to parallelize test suites across multiple nodes. This would allow our test runtime to be dependent only on the single slowest test scenario we have. There’s also a lot of room for improvement in the speed of our dependency installation and artifact acquisition/extraction steps.
Post-deploy tests
Every time the League of Legends release team deploys new builds to Live environments, they run a quick post-deploy smoke test that for years has been a fully manual process. By automating a complete game loop for our client tests we can now theoretically automate the post-deploy tests. This would improve consistency and save the release team significant tedious work. There are some small technical details to figure out, such as how to safely and securely generate test accounts in a Live environment without affecting players.
Farm out local testing
Some of our automated tests run many clients in parallel and are pretty resource-intensive. We currently ask developers to run the tests locally before they commit their changes, but that means their workstations become nearly unusable for the duration of the test suite. Instead, we’d like to farm out local test requests to an elastic farm. When a developer has some local changes to test, we could send their diffs to test machines in a datacenter or AWS. After running the tests on behalf of the developer, we’d just notify them of the results.
Conclusion
The system I’ve described in this article took over a year to create, and it’s still evolving. It certainly hasn’t been easy - we’ve had to change directions multiple times. The first several times we turned on our Last Known Good system, the result was utter chaos. But a failure doesn’t mean giving up. You can always backtrack a bit, tweak some things, and try again. Most importantly, no single solution will work everywhere - approaches that work really well on one project might be ineffective on another. However, with persistence, effective test pipelines and test cultures are an important and achievable component of any sustainable project. I really hope our journey can be helpful to anyone tackling a similar challenge, and would be excited to discuss further. Please leave any comments or questions below.