
The Riot Games API: Deep Dive
Hello all, Leigh Estes, aka RiotSchmick, here. I’m a software engineer at Riot Games working in the Service Availability initiative. Our first article on the API covered our goals, the responsibilities of the Developer Relations and Developer Platform teams in the API ecosystem, and some high-level details about the technology we used in building our API solution. The League of Legends community has created many useful tools and websites on the back of the Riot Games API, ranging from stats sites like OP.GG to sites that provide players with supplementary features like replay.gg. In this article, as promised, we will dig deeper into the technology and architecture of the Riot Games API platform, which refers to the edge infrastructure, and not the underlying proxied services. First, I’ll outline some of the foundational technology choices we made when we first decided to build an API platform. Then I can dive into specific components that we built as part of that platform. Next, I’ll give an overview of the technologies used to build the components. Last, I’ll cover how our infrastructure is deployed in AWS.
Foundational Choices
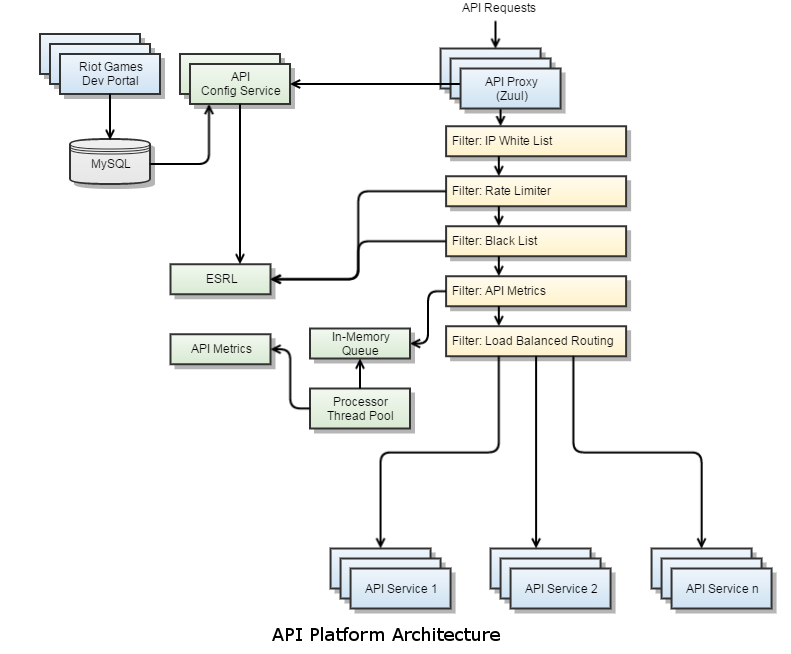
As mentioned in our previous article, we initially looked into using existing API management platforms, such as apiGrove and Repose, but decided to build our own solution that could be customized to work for all the different regions, partners, and technologies in the Riot Games ecosystem. After doing some research into what open source solutions were available to support traffic at our scale, we decided to utilize the Zuul proxy server developed by Netflix, as well as some other Netflix projects, including Archaius, Ribbon, Hystrix, and Eureka. The smart and talented folks at Netflix built their infrastructure to handle an enormous amount of constant, high-bandwidth traffic, so we knew we could trust that the code was battle-tested and production-hardened. Netflix Zuul provides a core JAR dependency that handles HTTP requests and executes filter chains. Using this dependency as a basis, we wrote some additional classes to include features we needed, such as automated health checking, connection pool management and monitoring, metrics processing, etc. On top of this core proxy server, we implemented custom filters to handle things like authorization, authentication, rate limiting, dynamic routing, load balancing, metrics collection, white listing, black listing, and more. The core proxy server, written in Java, and custom filters, written in Groovy, are built into a WAR and deployed in production running in the Jetty servlet container. Additional components of our core architecture, which our Zuul proxies talk to, are separate services that handle rate limiting, black listing, and metrics collection and processing.
Edge Service Rate Limiter
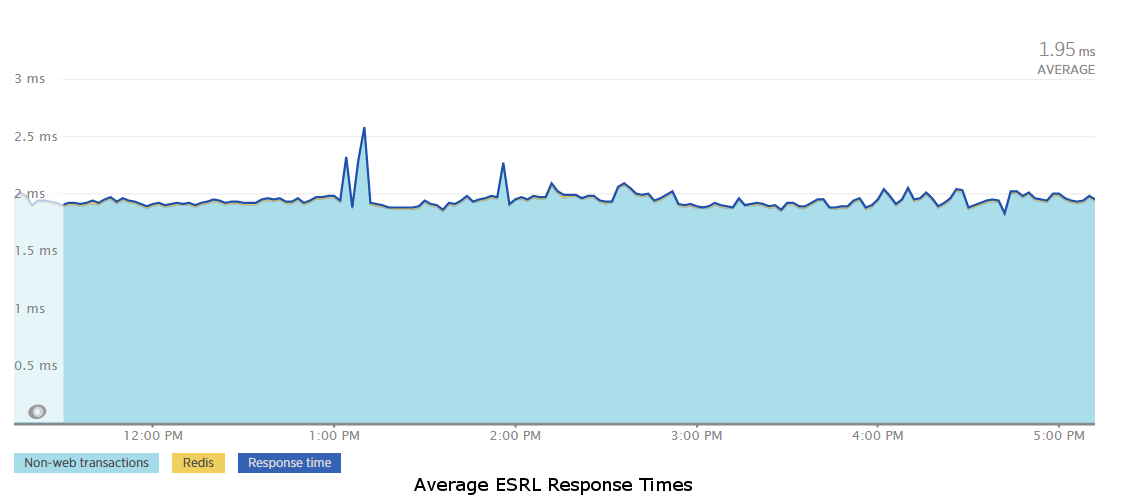
The Edge Service Rate Limiter (ESRL - pronounced Ezreal) handles the rate limiting and black listing functions. It provides two endpoints, one that uses something similar to a leaky bucket algorithm to manage rate limits for API keys, and one that checks if an API key is blacklisted based on the number of rate limit violations it has incurred over a given period of time. A goal with ESRL was to keep the response times incredibly fast so that we didn’t bottleneck our requests while trying to do rate limiting management. We achieved that goal with both of these endpoints having response times that average under 2 ms, as shown in the graph below, by using Redis for all of the ESRL’s operations. Each endpoint runs a Lua script in a single call to Redis to execute all the desired operations in one connection, and then uses the script response to determine what to return to the client.
Riot API Metrics
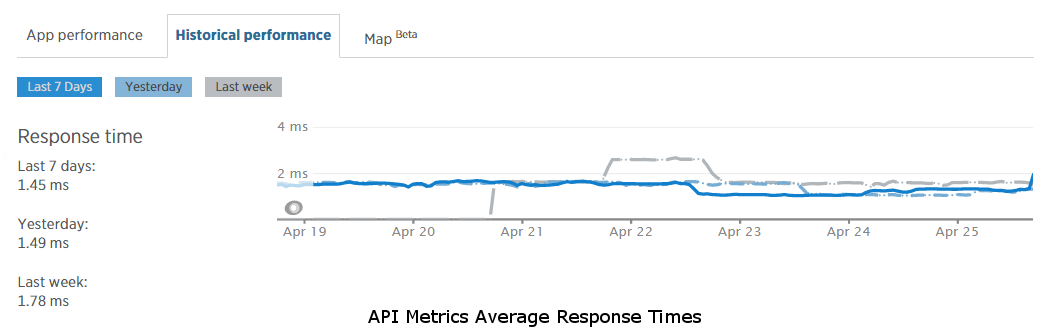
The Riot API Metrics service handles metrics collection and processing. As with ESRL, we wanted to make sure that metrics collection did not bottleneck our requests. To aid in that goal, we decoupled the real-time metrics collection from synchronous HTTP requests to Zuul. Requests to the proxy trigger a metrics filter that simply adds the metrics information to an in-memory queue. We may in the future change this queue to live in Redis or some other non-in-memory cache, but initially we wanted to limit Zuul’s dependencies to runtime REST service calls only, with no third-party build-time dependencies other than the Netflix core libraries. With a thread pool to process the queue, we have successfully managed to keep it in memory for now. Each thread in the pool runs a loop that pulls a metrics item off of a thread-safe collection, submits it to the Riot API metrics service, and if the call fails, re-adds it to the thread-safe collection so that it can be re-processed later. If there are no metrics in the queue, the thread will sleep to avoid a busy loop that consumes CPU cycles. The Riot API Metrics service provides an endpoint to post metrics information, which simply adds it to a queue in Redis then immediately returns to the client. While these requests are being submitted asynchronously from Zuul, we still want the response times to be as fast as possible so that the in-memory queue size doesn’t grow unbounded if the processing can’t keep up with the throughput. This endpoint’s response time averages under 2 ms as well, as shown in the graph below. The metrics service also has a thread pool that performs background processing to read items from the queue, collate metrics, and save the data a few different ways in a MySQL database so that we can do relational queries against it.
Developer Portal
As mentioned in our previous article, we built a public Developer Portal to facilitate interaction and ongoing conversation with third-party developers. In order to simplify development by leveraging an existing MVC framework, we built the developer portal as a Grails application written in Java and Groovy that runs in Tomcat and utilizes Bootstrap for the front-end. When users first log in to the developer portal, a developer account is created for them. A development application with an associated API key is automatically created for them and associated with their account. If a higher rate limit is needed for a production application, users can register their project for access to a production API key. Applications are associated with a tier, which is a rate limit definition. For example, a demo tier may be defined as 10 calls per 10 seconds and 500 calls per 10 minutes. Having both rate limits tied to a single tier means that the tier can manage both bursty and sustained calls. Applications are also tied to policies, which define a set of API endpoints that an application may access. In addition to this application configuration, the API platform relies on configuration that describes the available services to proxy and their physical endpoints (i.e., IP addresses or DNS). An administrative UI allows us to configure a service, the APIs it hosts, and the physical endpoints that serve those APIs. The APIs can be added to or removed from policies, and applications’ policies and tiers can be modified as well. Currently, in production, the configuration of tiers, policies, services, endpoints, and APIs is done manually. In the future, we will be transitioning to a framework that uses service discovery to automate much of this configuration for the edge.
Propagating Configuration
All of the above-described configuration data for the API platform, including the automatically generated accounts, applications, and keys, as well as the manually configured tiers, policies, services, endpoints, and APIs, are stored in a schema in a MySQL database. A lightweight service called the API Configuration Service is responsible for providing configuration information, such as a list of valid API keys, a list of URIs that the edge server should consider valid, the physical endpoints to which those URIs should be routed, the list of URIs on each policy, the definitions of each rate limit tier, etc.
Both Zuul and ESRL needed to read in these properties regularly, and dynamically change their values. The Netflix Archaius project was written to provide this exact functionality, where a list of property sources can be polled to update dynamic properties in memory, so it was a perfect fit and we integrated it with both ESRL and Zuul. Initially we configured the Archaius property sources to hit REST endpoints provided by the API Configuration Service that returned the relevant properties. However, a number of issues combined to make this mechanism unreliable for frequent dynamic property updates. First, the number of configuration items in the database grew over time as our platform grew in scope and user base. That translated to increasingly longer database queries, as well as increasingly larger responses from the REST endpoint. There were sometimes network issues inside our VPC, which made frequent attempts to download large files even more problematic.
Ultimately, it became too unreliable and time consuming to download the properties via a REST endpoint over the internal network. Thus, we decided we needed a CDN-type solution where we could download large files reliably over the internet from a geographically close edge. S3 provided exactly what we needed, so we updated the API Configuration Service to read the information from the database and write out key information into properties files in S3 buckets. Then Zuul and ESRL were updated so that their Archaius property sources pointed at the S3 buckets instead of the API Configuration Service’s REST endpoint. This model has proven reliable and performant.
Technology Overview
The ESRL, Riot API Metrics, and API Configuration Service are written in Java. Initially they were written using a framework called dropwizard, which enables running Jersey REST services as an executable JAR without needing to deploy it in a servlet container by using embedded Jetty. Just recently, we reimplemented these services utilizing a framework built internally that we call Hermes. In a previous article, Cam Dunn discussed how Riot utilizes an RFC process for tech design. Hermes is the implementation of a specification called Ambassador that started as an RFC (in fact, the screenshot at the top of his article shows the Ambassador RFCs!). Reimplementing our projects using technology like Hermes that was built in-house and has been widely adopted provides several benefits, including the following.
-
When bugs or performance issues arise, we have internal support to help us out.
-
As users that have a stake in Hermes working well, we contribute back to the code base, and help everyone at Riot by making it better.
-
When other developers need to look into our systems or code, we are using common technology, which gives them a leg up in understanding what’s going on.
-
As users that have contributed back to the code base regularly and have direct access to its original authors, we understand it better ourselves when tracking down issues.
We have already found several bugs and performance concerns in Hermes, fixed them, submitted pull requests, and coordinated new releases of the entire framework on our own since its adoption. Thus, we feel the dividends that came from adopting the framework have greatly paid off for our team and Riot as a whole.
I mentioned earlier that we leveraged Hystrix in our edge. This technology provides the ability to detect when calls to an underlying service are being slow, as defined by a configured threshold, and short-circuit any calls to that service by immediately returning a 503 without attempting to proxy the call. We did some work to get Hystrix integrated into our custom Zuul code, but we never got it working to our satisfaction, so we haven’t yet deployed it into production. It is still on our road map to get Hystrix integrated properly or to implement our own similar solution. Our API platform configuration does allow the configuration of both connect and read timeouts for proxied services to prevent consistently slow services from degrading edge performance. However, a short circuiting mechanism like the one described above would further reduce the effect of consistently slow services by preventing the affected requests from keeping Jetty worker threads busy or backing up the Jetty accept queue.
We initially used Ribbon to do software load balancing across a group of servers for each service that Zuul proxies. When we refactored our dropwizard projects to run as Hermes servers, we also refactored Zuul to use Hermes client instead of Ribbon to do software load balancing. Similarly, we initially used Archaius to handle all dynamic configuration, including the API platform configuration discussed earlier, as well as environment-specific application configuration for the proxy. Recently, we decided to change over to another in-house solution called Configurous for the environment-specific application configuration. I already enumerated above the benefits of leveraging our own technologies, so I won’t rehash them here. Like Hermes, Configurous was conceptualized in the RFC process and was eventually implemented and adopted by many teams throughout the company. The intention of Configurous is to easily manage application configuration across different environments, including dynamic updates. However, since the scope of Configurous is to manage application configuration, it only supports small property values and relatively infrequent changes to those values. Thus, we continue to use Archaius for the large and continuously changing properties that define the API platform configuration.
Last, we integrated the proxy with Eureka, which had been defined as part of the Riot “Stack” ecosystem and was being spun up in all environments. This integration allowed us to begin the earlier-mentioned transition to auto-discover and configure services in the edge. In addition to auto-discovery of underlying services that want to be proxied, it also allows each proxy to auto-locate the ESRL and Riot API Metrics services with which it should be communicating. This functionality is currently only tested and enabled in internal environments, but it works well and saves a lot of manual steps as boxes are spun up and down. Eureka was eventually replaced with another Riot technology called Discoverous. Discoverous was another product of the RFC process and its implementation was based on Eureka, but added some custom functionality that the complex Riot ecosystem required. It is completely backwards compatible with Eureka, so no changes were required on our side when the switch was made. Hermes, Configurous, and Discoverous are foundational pieces of Riot’s service architecture and will be covered in future blog posts.
AWS Deployment
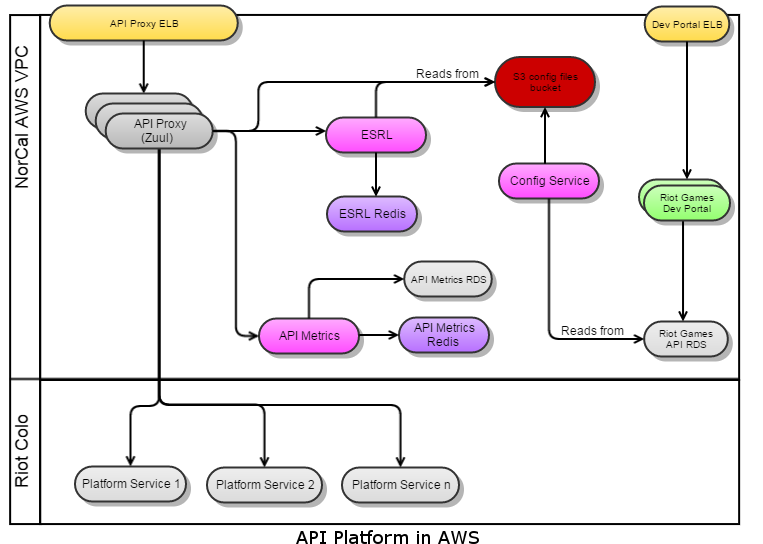
The Zuul proxy servers are deployed on AWS instances across 3 VPCs in Tokyo, Ireland, and NorCal. There are 4 proxy server instances, 2 in each availability zone in each VPC behind an ELB. Each VPC also has a set of instances for the Riot API Metrics and ESRL that the Zuuls in that VPC utilize. The Riot API Metrics and ESRL also each use their own Redis, an AWS ElasticCache instance, in each VPC. The Riot API Metrics in NorCal is considered the metrics “primary” and is backed by a MySQL database, an AWS RDS instance. The Riot API Metrics in Ireland and Tokyo are considered “replicas” and when their threads execute the persistence step to save the metrics data, they do so by making a REST call to the primary with the DTO serialized into JSON. The primary then saves the data to the database. This model allows us to save all metrics data from all regions into a single database that we can query against. When the primary executes the persistence step, it saves the DTOs directly to the database. The API Configuration Service runs only in the NorCal VPC and writes the necessary files to S3 buckets in all regions. Each Zuul and ESRL reads from the S3 bucket in its own region to reduce latency.
Conclusion
The edge service and related infrastructure have continuously evolved over the years since the API was released. We have made improvements in performance and reliability, matured the technology powering the different pieces, and production-hardened the entire architecture. Going forward, the edge infrastructure will be deployed in every Riot Data Center to help manage ACLs and rate limits, provide an easy single point of access for all APIs being shared across services, and leverage all the other features and benefits the edge provides. As we roll out the framework to allow the edge to auto-discover and configure services, it will become an even more powerful mechanism for allowing services to talk to each other in controlled, predictable, and reliable ways. This framework will allow teams to move even faster and focus on providing player value rather than having to worry about solving the same problems over and over when they write new services.
The edge was born as part of a focused solution to the specific problem of scraping on our platform and has grown and matured to the point that it is positioned to be a critical piece of the micro-services architecture that Riot is building. We are excited to see how far it has come from its humble beginnings and look forward to the challenges of providing a company-wide edge solution. Thanks for reading! If you have any comments or questions I invite you to post them below. I’ll be back in the near future with an article that explores an investigation into optimization of our API proxy layer.
For more information, check out the rest of this series:
Part I: Goals and Design
Part II: Deep Dive (this article)
Part III: Fulfilling Zuul’s Destiny
Part IV: Transforms