
Profiling: The Case of the Missing Milliseconds
Hi, I’m Tony Albrecht, an engineer on League. I’m back with some more performance goodness. In the previous article, we tracked a slowdown reported in an LCS game and an issue with Swain that was first reported by players. For this article, we’re stepping back a little further and looking at how we can measure the aggregate performance of League over an entire region, notice a dip, and then narrow down the cause. In this case, we chased a 2ms per frame drop in performance to a single missing ASCII character in our code.
The Case
Up until recently we measured the performance health of League by collecting the average frame rate of every game played. This data (and other data like it) is stored in massive databases and we extract the bits we’re interested in, and then visualise it in graphs like the one below. Obviously, the average frame rate of a game is a very rough estimate of the performance health of a game - the frame rate varies dramatically depending on the phase of the game and many other factors, but it does give us something to go by.
Here are the FPS averages for North America for the start of this year:
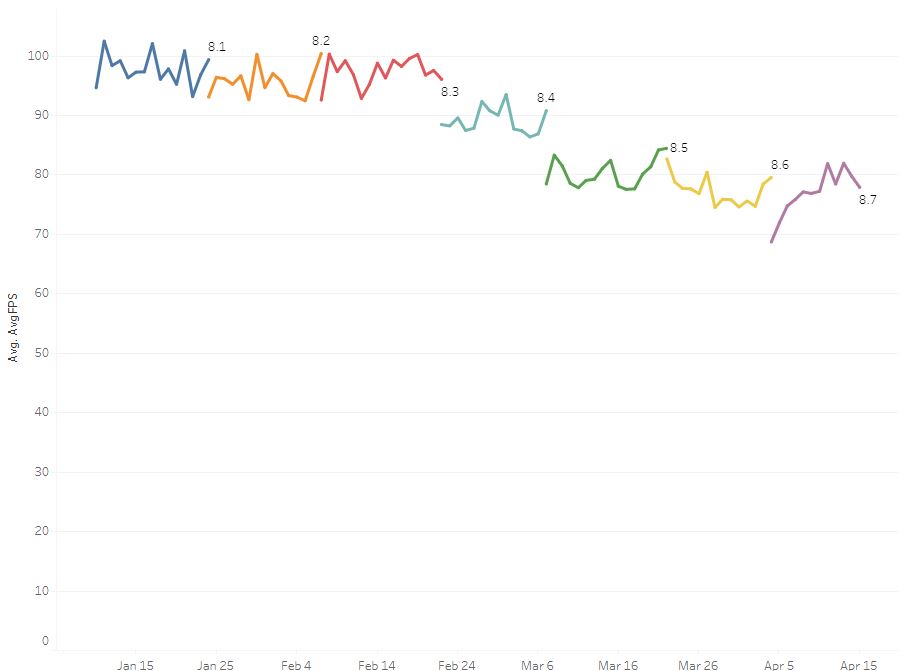
Even though the lines are noisy, we can still see trends and note that each patch is vaguely constant in performance (maybe +/- 5%?). That gives us an idea of the noise inherent in this system. Note the sudden drop in performance from 8.3 to 8.4 and then again to 8.5. Wow, that’s bad - we’ve dropped 20fps over 2 patches. This drop from about 97fps down to 80fps corresponds to a frame time increase from 10.3ms to 12.5ms - over 2ms gone! Someone should fix that! The question is fix what? What was broken? What caused the slowdown? Is it a code change? New assets making the CPU or GPU slower? Solar flares?
The first step is to look at the code and data that changed for that patch, then sift through the changes and test them, or look at the code and figure out what went wrong. The problem is, there are 15 to 20 thousand changes over a two week period that comprise a single League patch (many of those are automated check ins associated with builds, but there are still many thousands of changes to check). This is too many changes for even a small dedicated team to check in a reasonable period of time. And anyway, this is already too late - players are already suffering from this performance degradation. We need to catch this sort of change before it goes live. Why wasn’t this caught on PBE (Public Beta Environment)? Isn’t that what its for?
Let’s look at the same graph for PBE:
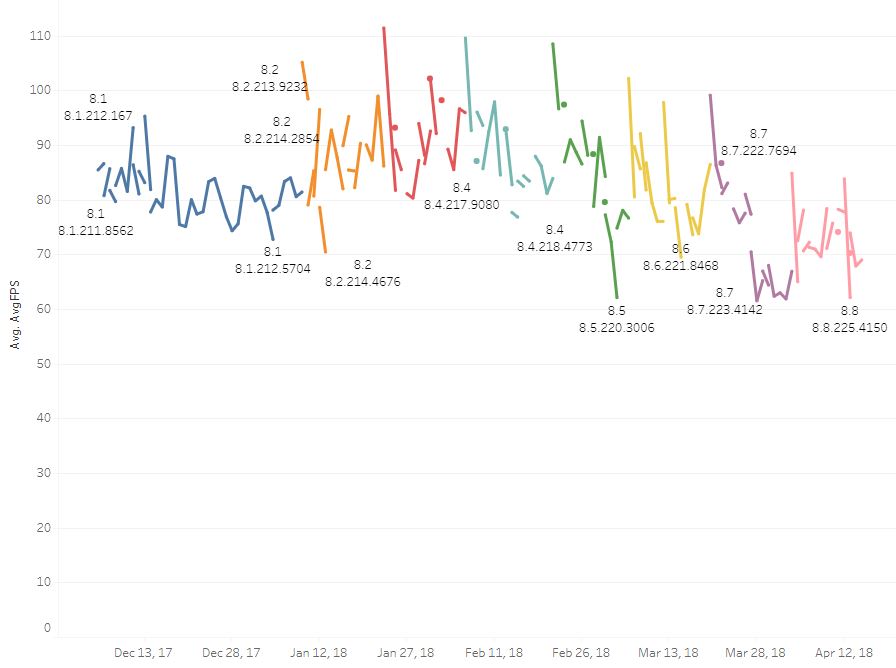
This is quite a bit messier: we redeploy to PBE whenever we need to, which means fewer sets of changes for each version, but more versions. While this should make it easier for us to pinpoint the offending changes, these graphs are way noisier. In fact, it’s not even clear that there is a drop in frame rate from 8.3 (red) to 8.4 (blue(ish)) on this graph. What’s going on here? You can’t even tell if there’s a problem until it’s too late.
A Digression
Let’s take a look at another set of patches to better explain what’s going on:
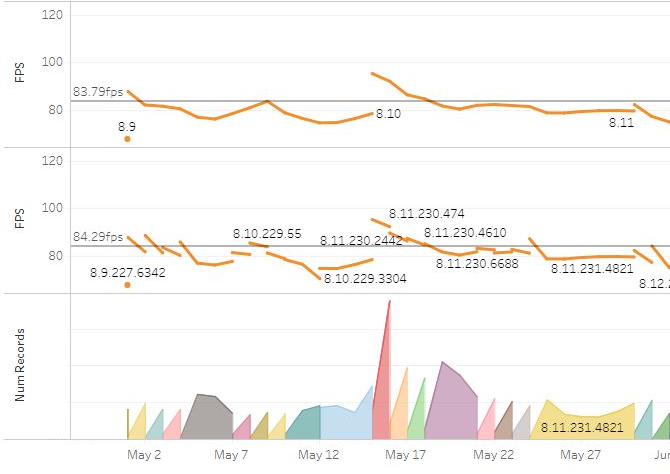
This set of graphs depicts the average frames per second of major patch versions by day (on the top), then by minor versions (which includes information on the latest changelist used to make that version), and then the number of records per day on the bottom. The key thing to note here is the large discrepancy between the end of 8.10 and the beginning of 8.11. Did the game suddenly become more performant? It looks to have gone from 78fps to 95fps. In my experience, accidental optimisation is like Santa - a nice idea but it doesn’t exist. So what happened here?
The hint is in the number of records: the red spike shows twice the number of people playing that day. The reason there were that many people playing is that 8.11 was the introduction of a new champion, Pyke, and lots of people logged onto PBE on that day to check him out. Most of those people had better CPUs than the average PBE user, so the frames per second jumped. So it looks like the frame rate graph is heavily influenced by the distribution of hardware on a given day; in fact, if you plot a graph of average frame rates per hour, you can see a diurnal rhythm to the plots, both in number of games per hour as well as FPS:
Top line is fps, bottom is number of players.
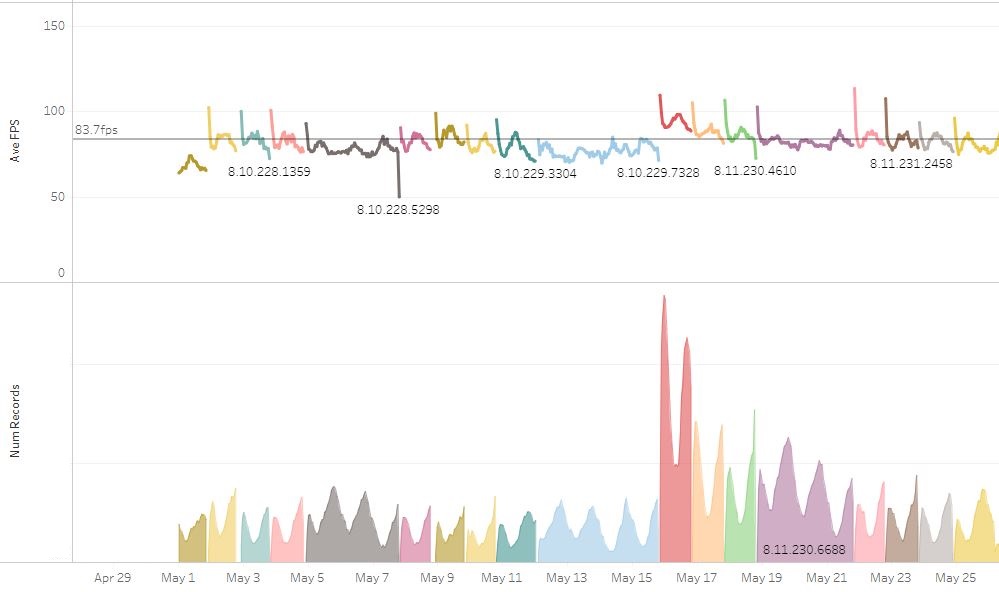
So, to make these graphs useful, we need to remove the variation introduced by the changes in hardware. We can do that by filtering by CPU and plotting the FPS for a given CPU. We use only the CPU because the CPU is usually the bottleneck for performance in League. It’s more accurate to plot CPU and GPU combinations, but that reduces the number of games per day in a given plot and fewer games means more noise. So, for PBE, we should be able to plot the FPS of a given CPU for a more indicative picture of performance. If we look at the most commonly used CPU on PBE, we get the following graph:
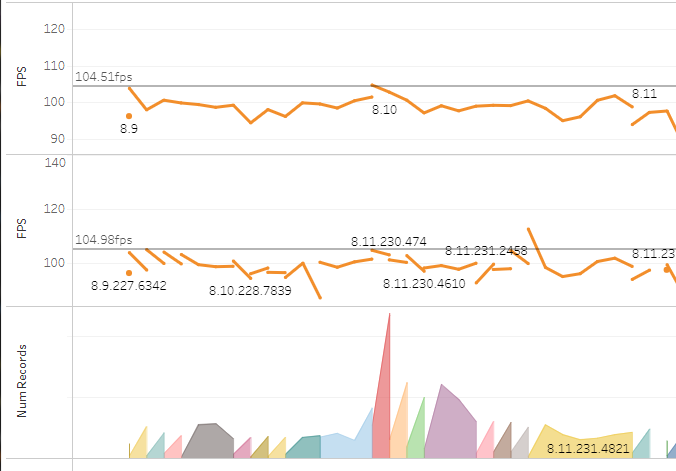
The variation between 8.10 and 8.11 is much smaller now - from 101.6fps to 104.8fps. There’s still a fair amount of noise, but that’s mainly due to the much lower number of games played by a single CPU type.
To further reduce noise, we can group CPUs with similar performance for a larger sample. We can even pick CPUs from different spec categories and accurately plot high, mid, and low spec machines’ performance.
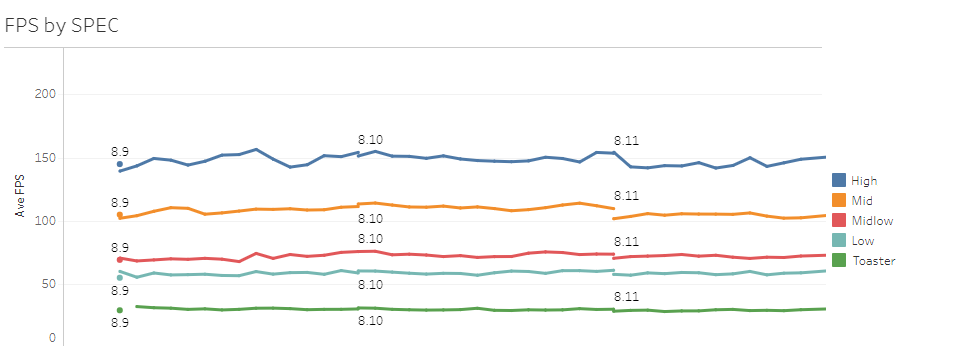
This is good. We can now better see changes in performance while still in PBE, and these changes in performance accurately predict what will happen in live builds. Even the per deploy statistics are now useful and can help us to more accurately pinpoint sudden performance changes to a smaller range of changes.
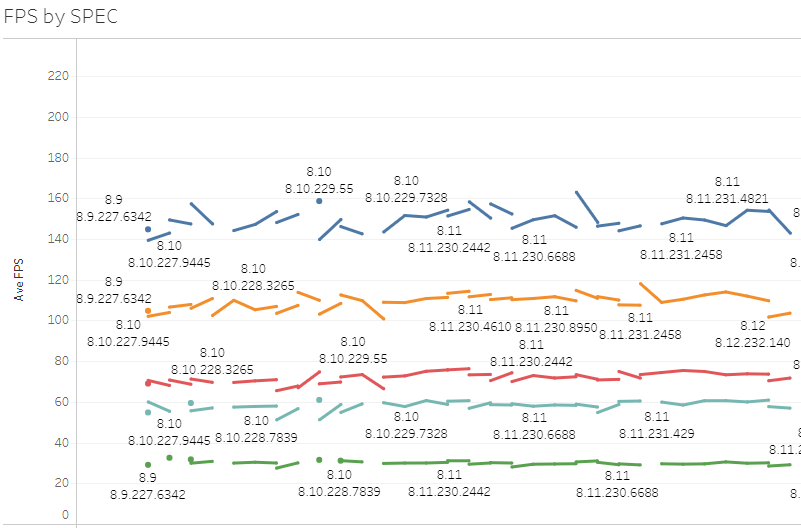
So, now we can see a performance change per deploy, but we will still need to comb through hundreds of changes to find the cause. In order to help pinpoint which section of the code is responsible for performance degradation, we also added some sub-frame timing metrics. For example, we now measure not only the CPU time taken to process a game frame, but we also measure the time taken to build the HUD, the time taken to render the scene, the time taken for particle simulation, for fog of war, how long we stall for the GPU to be ready along with other significant portions of the game processing. This information is still not stable - we’re changing it as we go, making sure that it delivers useful, actionable information - but we should at least be able to see a sudden change in the performance characteristics of one section of code.
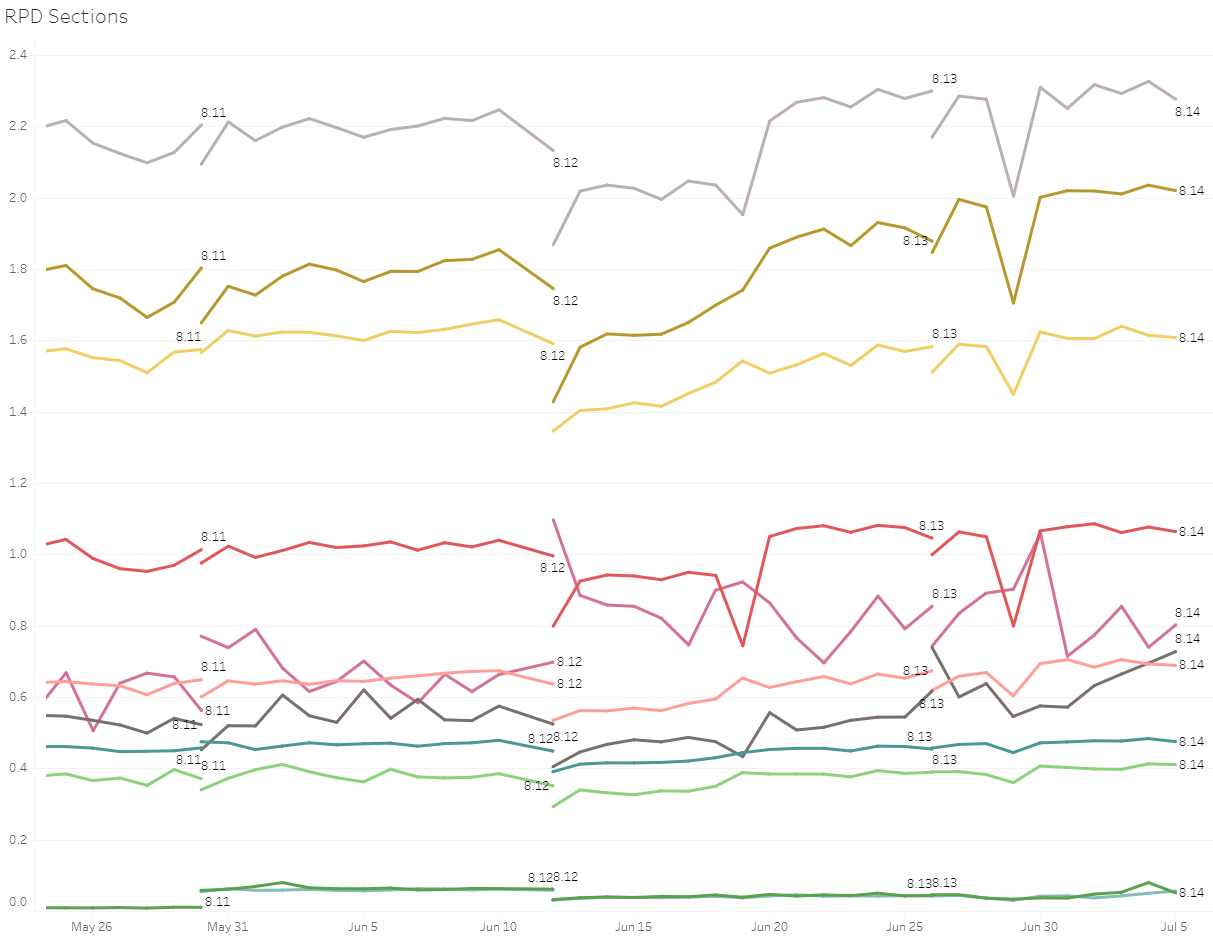
The Y axis here is in milliseconds per frame. We can see some variation here, but even a change of half a millisecond for a section is noticeable. More importantly, it’s actionable. If we see a change in the cost of building the HUD, we can look at just the changes that occurred in HUD code within the change list range applicable to that date. We go from hundreds of changesets to tens.
Another important metric is the number of slow frames or frame spikes in a game. These sudden slowdowns can often be seen as stutters or freezes. The number of these slowdowns per frame and per section can give us an indication of badly behaving code, even if the average performance is fine. We store and collate these metrics per game as well. In fact, we collect all of this information for every frame of every game and save it as a Riot Profile Dump (.rpd) in “Logs/Performance Logs/League_PerfDump.rpd”. If a player has performance issues, we’ll ask for that file and we can use it to try and figure out what’s wrong. But I’ll deal with that in more detail in a later article.
So, armed with this new information, can we discern the performance issue that caused the frame rate drop from 8.3 to 8.4, and then to 8.5?
No. No we can’t.
For one thing, we can’t retrofit the section performance monitoring back in that old code. That data doesn’t exist in those builds. We could have gone back through the older PBE data and filter by some of the popular CPUs at that time and that should give us a better indication of which deploy had the performance drop, narrowing our search down to hundreds of change sets. And we would have done that, but before we did that we stumbled upon the answer accidentally.
Serendipity
While examining a performance trace dump from a playtester, we noticed that there was a gap in the instrumented functions’ timeline. Normally all the major functions are instrumented so that when we look at a single frame we have close to 100% coverage. What we saw was the scan below:
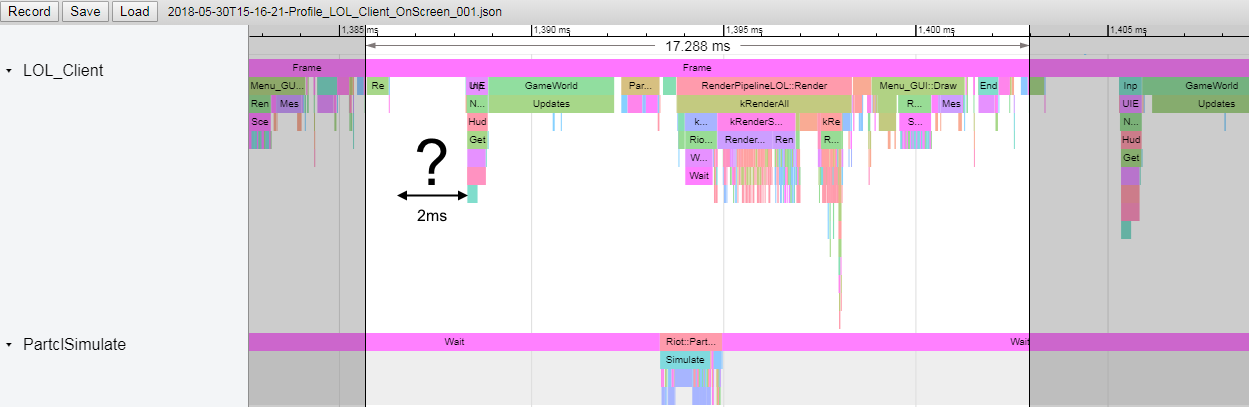
That’s a suspicious gap. One should never ignore a suspicious gap. Upon further investigation, we found a few lines of code used to communicate with the League client - these should have been quick. They just polled the client and instantly returned if there were no messages there. This issue was handed back to the team responsible for the code and they quickly found the problem. The polling code was waiting for at least 1 millisecond, and that polling code was called twice! We’d found our 2ms stall! The code in question had been refactored about a year ago, but wasn’t being used in game, so we hadn’t noticed the 1ms stall. The poll of the League client was introduced for 8.4 but was only being called once, so the 1ms slowdown slipped in under the radar because our PBE performance monitoring was too crude to pick it up (it was within noise). A second call was added for 8.5 and so another 1ms stall snuck in. We can now see that this 2ms loss corresponds almost exactly with the drop in frame rate that we saw from 8.3 to 8.5.
We’d already done some significant testing of the performance impact of the client, including an analysis of the CPU cost while the game was running (we’d even found a problem there and fixed it), but we hadn’t considered that the existence of a running client could cause the game to do nothing for 2 milliseconds.
The code change to remedy this problem was to add a single equals sign to the message polling function. We’d been calling this function with a timeout of 0ms, so the intent was for it to return immediately if it failed to read a message. The condition for exit if there wasn’t a message was something like this:
currentTimeInMs > startTime + timeoutwith the currentTime was being rounded to the nearest millisecond. The above code would keep polling until currentTimeInMs was larger than the startTime plus the timeout, which was, for a timeout of zero, one millisecond later. The following code was the fix:
currentTimeInMs >= startTime + timeoutThe fix for this made it in for 8.13. Now we had a test for our new performance monitoring suite. If we could detect this positive change then we’d be more confident in our ability to catch a similar negative change in the future. Looking at the graphs for 8.13 on PBE we saw this:
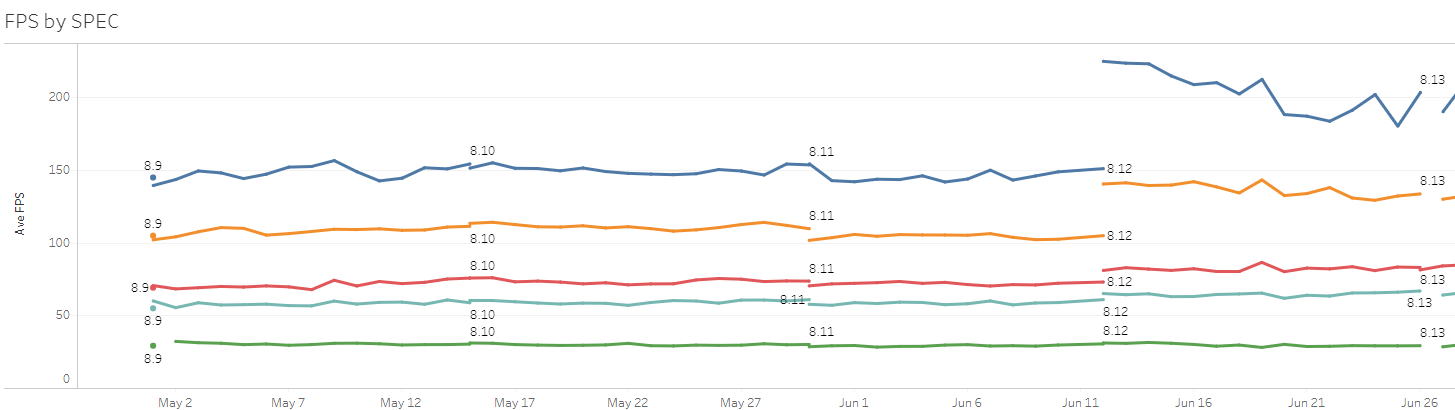
Check out the blue High Spec line - a jump of 50fps! We can definitely see that change! A game running at 150fps takes around 6.6ms per frame, so a change of 2ms makes it 4.6ms per frame which is over 210fps. Note the wobbly blue line for 8.13; that’s not just due to code changes, it’s also due to a lower number of CPUs of that spec running the game on PBE for that patch. The lines below that are much more stable due to higher numbers. Note that the green “Toaster” line doesn’t show any perceptible change. That’s because a 2ms change of a game running at 30fps means that the frame time changes from 33.3ms per frame to 31.3ms per frame, or 32fps. Two frames per second difference is much harder to notice than 50 frames per second. One way around this is to plot the frame times rather than the frames per second.
Summary
Without intervention, performance in an evolving software product will inevitably degrade over time. We need to be vigilant and build systems to accurately monitor indicative performance so that we can maintain and improve performance. For non-console-based games, this means filtering by CPU and GPU to provide as stable a baseline as possible for comparisons (I miss console programming). Small sample sizes and noisy source data can complicate this. When performance degradation occurs - and it will - there needs to be a way to trace back to the source of this degradation or reproduce the trigger if one exists. In the end, this usually results in QA doing binary searches through older game versions while programmers pore over code changes looking for and testing likely culprits.
I’m confident that we haven’t seen the last performance degradation in League. I’m also confident that we’re now in a better place to identify and remedy those performance degradations, and our capabilities will only improve from here. If you play League, we appreciate your patience when performance issues occur. Your reports and discussion about how to reproduce or avoid problems help. I hope this article gave a clear window into how we think about performance over time, and as always, I’d love to hear your questions in the comments.
Check out the rest of the series:
Part 1: Measurement and Analysis
Part 2: Optimisation
Part 3: Real World Performance in League
Part 4: The Case of the Missing Milliseconds (this article)