
Keeping Legacy Software Alive: A Case Study
Hi all, Brian "Penrif" Bossé here with a fresh batch of gory, nerdy details surrounding an outage for League. Today we'll be going through why the EU West shard was out to lunch for just over five hours on January 22, 2021. We don't always write these things up - they take time to do and the reasons for outages aren't always that interesting - but this one was particularly painful as it was quite long and on the heels of some other, unrelated outages so figured it'd be worth a dive. Hopefully by the end, you'll have a better idea of what's going on behind the scenes when League is down and what problems we are tackling to reduce the frequency and severity of our outages.
General Anatomy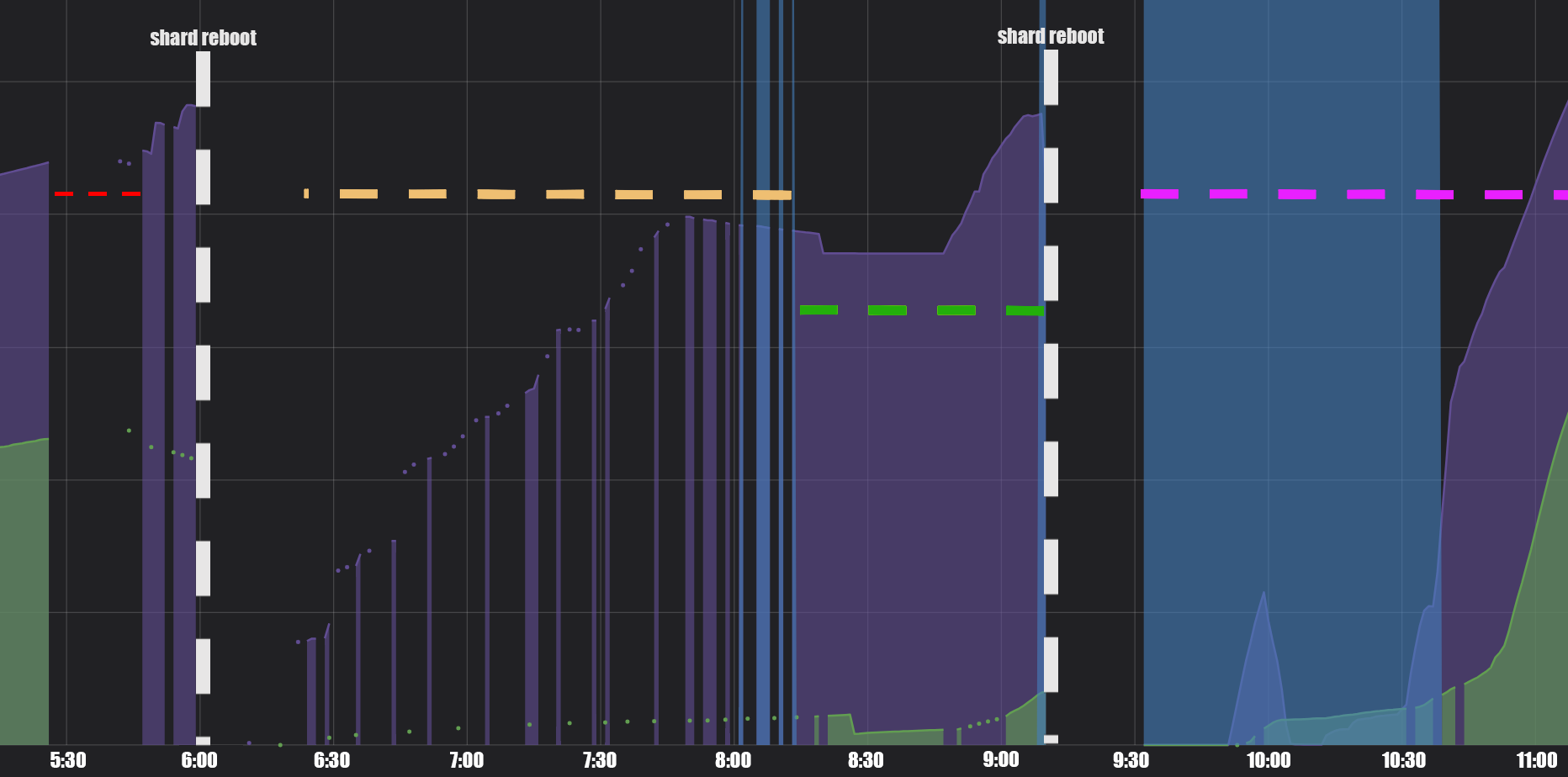
So here's a rough graph of the incident - the purple line is the number of players logged in to the client and the green is the number of players currently in a game. Clearly, something terrible happened at 5:25 and the data goes poof (red dotted line), but attempts a recovery just before 6:00. At that point, we took the shard down for a reboot, after which you can see a very sporadic amount of data coming in with clear trend lines of folks logging in, but not many actual games happening, which continues 'til 8:15ish (yellow dotted line). After that, the data becomes more solid, but doesn't look remotely healthy (green dotted line), and everything hits the floor again at 9:10, when we rebooted the shard a second time. A slow recovery period follows (pink dotted line), and we're back at it by 11:00.
Now that you have a general idea of what things looked like from our status monitors, we can take a look at both the technical breakdown and the human element of the incident response.
What Went Boom
In short, a database primary serving some non-critical functions experienced a hardware failure. These things happen.
Wait, but like that's normal, why didn't it fail over?
We haven't set up automatic failover to secondary for that database.
Um, why not?!
Priorities. This whole area of our backend is the old legacy tech - the Platform - that we've been spending a lot of effort in the past few years moving away from. A lot has been moved from there, but some things remain - some of them critical. But this database in particular wasn't critical, and it was assumed a failure would not cause significant outage.
Well.
Yeah, about that. The primary reason we're moving away from this old monolithic setup is because of how tightly coupled absolutely everything was inside of it is, so that irregularities in one corner of the system don't blow up totally unrelated systems. Like some non-critical database blowing up, you know, the whole shard. Unspoken dependencies are a huge problem in software architecture, and this incident is rife with them. I don't mean to rag on monolithic software here by default - it is completely feasible to manage a monolith in such a way that separation of concerns exists and errors don't cause systemic problems. It's just that our monolith wasn't managed that way at all. It's the tight, implicit coupling that's the enemy here, so let's dig into what those were.
First up - all database connections from the Platform process go through connection pooling. This is a great pattern that allows for separation between connections to different databases, so that problems with one don't affect others. Sounds great, right? Well, the problem is, all of those connection pools utilize the same thread pool, and that got starved by operations that couldn't complete against the failed database. This is a sneaky problem; it feels like you're practicing separations of concerns well, 'cause you're handling the problem of connection management separated from the rest of the business logic and in isolated pools. However, implicitly sharing the underlying threads gave a route for a single, unimportant database failure to cause an exhaustion of a shared resource needed by the entirety of the system to function. It's like the classic Dining Philosophers synchronicity problem, except one philosopher just up and stole all the forks and went home. Nobody havin' pasta tonight.
Here's where the human element of incident response comes into play - nobody in the response team understood that old piece of software well enough that they could pinpoint that fact in the middle of a crisis triage. When your software's down and folks are screaming to have it back up, you need a stone-cold understanding of exactly how all of your systems and the systems they interface with work. Without it, you start latching on to narratives that make sense in the moment based on intuition. With the complexity of everything that goes into making this game run, no single human can possibly have that amount of understanding over the whole ecosystem, so red herrings get chased. Common narratives become guilty until proven innocent, and they take precious time to prove false.
In this particular case, the red herrings took a long time to prove false. We had recently been dealing with malicious network attacks and there was some hardware maintenance going on that had caused minor impacts in other parts of the world, so the early incident response focused almost completely on determining if those factors were in play or not. Between that strong focus and an absolute flood of alerts from many services being degraded, the alert regarding the failed database was not noticed until about an hour into the outage. Unfortunately, that was after a time-intensive soft restart of the platform software had been completed.
Flying Blind
At this point, we have a restarted platform that booted up on top of a failed database. Once identified, we were quick to get that database moved over to its secondary and healthy, but it was unclear whether the platform was in a functional state or not. Metrics were trickling in very slowly - you can see from the graph above we were getting reports from it very sporadically. Without that visibility it was exceedingly difficult to make confident decisions on how to proceed. This brings us to the second implicit coupling that plagued this incident - that all systems are running on the same JVM. As the soft-restarted software struggled to recover itself while taking on the load of players trying to log back in, garbage collection began taking significant chunks of time, essentially pausing the normal operations of the process for seconds at a time. Metrics reporting was not tolerant to those pauses, leaving giant holes in the data.
Ultimately, the only thing we could really trust was that games weren't starting at the rate we would expect given how many people were logged in. Most of the component systems that exist along that critical path were reporting to be at least partially healthy, with maybe some nodes in a bad state - but nothing that should itself cause a system-wide failure.
As time dragged on and we weren't getting clear answers, we made the call to do a hard reboot of the cluster on the belief that the cascading effects of the failed database caused some form of systemic contagion that could not be recovered from. We suspect the core problem was a failure to isolate resources in our in-memory database cache solution, another source of implicit dependency - but lacked the data to be certain.
Turn It Off And Back On Again

Hey, it works. Be it your home router or the backend for a video game, when a complex system starts acting irrationally, nuking the state and starting from a known good is very effective. The downside to doing so as a large shard like EUW comes into peak is that you get a lot of synchronized actions as players rush to log in once it's back up. What's normally a steady stream of mixed traffic all of a sudden lines up as you return to service from a cold start. The only effective way to mitigate that is via a login queue, and we've got one of those!
Unfortunately, it misbehaved, and didn't really respect the limits we had on it which caused a lot more spikey of a flow than we were after:
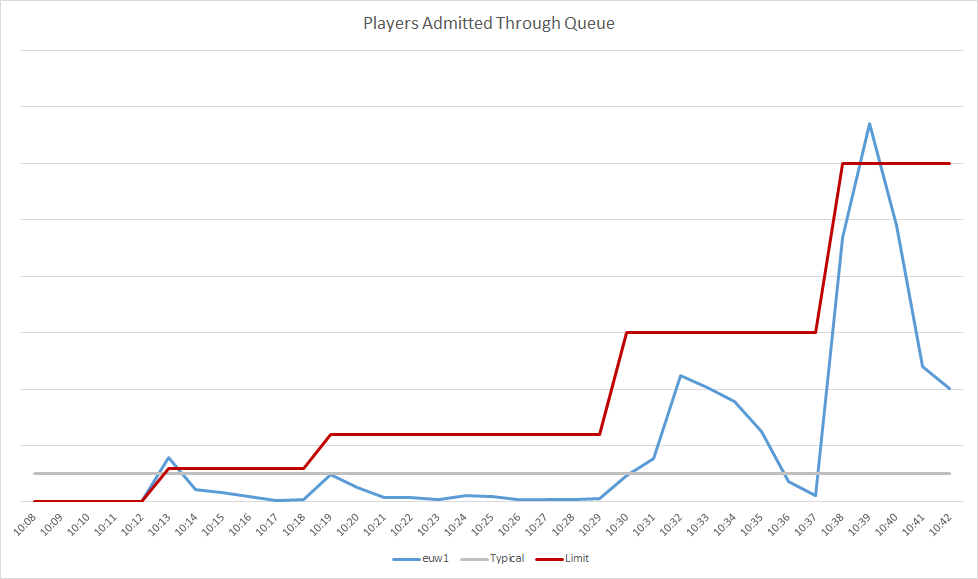
Every time we raised the limit, a rush of players would be let in, but then it would restrict it back down to a very small number. This gave us a false sense of security as we were watching the health of the cluster and seeing good things, assuming that the rate of players coming in was roughly the rate we had set. Ultimately, that resulted in false confidence which led to us effectively removing the limit in two large gulps, and nearly took us back down again. Thankfully, other than our metrics horking themselves some more, nothing went boom and the incident was fully resolved.
The Grand, Glorious Future
Clearly there's some core problems we need to address here. At the root, our databases need to be more fault tolerant. Walking up the chain, our systems need to become more resilient and less reliant on implicitly shared dependencies. Finally, our incident response must become crisper and more capable of ruling out potential factors. That's a tough problem to crack because you're simultaneously dealing with an information management problem with high scope and the need for near-instant retrieval, and with figuring out how to predict what information will be useful in circumstances that were definitionally not foreseen.
I'm quite pleased to be able to share with everyone that we've already got efforts well underway to address the root cause of this incident, by way of a BONUS INCIDENT REPORT!

Bonus Incident Report
That's right, two for the price of one!
At 4am PST, February 2, the hardware servicing EUNE's core Platform database experienced a hardware failure. This database is central to many mission-critical functions performed by the legacy Platform software. Immediately, login events dropped, and it was clear the Platform was beginning to fail. Forty seconds into the incident, the automatic failover procedure had the database instance restarted, and the complete failover process was finished 68 seconds after the initial failure. Platform software almost completely recovered on its own, requiring intervention only to clear a minor non-impacting issue.
In addition to logins being unavailable for about a minute, approximately 5,000 players experienced a disconnection from the shard, but were able to immediately reconnect.
Players got to play, devs got to sleep - that's what living in the future looks like.
Wrapping up
Thanks for coming along for this ride with me, I hope it gave you some insight into the work that our behind the scenes teams are doing to increase the stability and reliability of League. Our “to do” list is long and challenging, but we’re highly motivated by turning fragile systems capable of multi-hour outages into robust setups that blip at the worst. If the wins keep comin', then we keep goin'.
If that sort of work sounds interesting to you and the idea of replacing the engine on a plane while it's at 30,000 ft frightens you in an exciting way, head over to our jobs page and check out available positions.