Fixing the Internet for Real-Time Applications: Part III
Over my last two posts, I’ve talked about the challenges facing real-time applications like League that arise from the internet’s architecture, and how Riot is tackling some of those challenges by creating our own network. In this post, I’d like to look forward - what’s next, and how can we collectively get there? This topic has inspired a lot of reflection on my own experience building networks, and has galvanized my perspective that things are changing for the better. At its core, this post deals with how we can enact meaningful and positive change to the internet itself.
We started with this question: what more can Riot, a game company, do to improve the internet? After much soul searching, ideation, and experimentation, surprisingly, the answer is: “a lot!” We think Riot can participate in a paradigm shift in how tech companies approach the economics, deployment, and business of the internet. To give a few examples, we believe we can help lead the way on driving down the cost of owning and deploying networks, reducing the complexity of maintaining them, and improving the peering workflow. I’ll dive into each of those three points, but these are just a few areas that highlight how the whole network ecosystem is changing.
Before I do, however, allow me one brief digression on scale. It’s easy to think that challenges like these should be handled exclusively by companies with a profile like that of Amazon, Facebook, and Google - but I don’t buy that. Those three are doing amazing work in this space, manufacturing their own switches and routers and participating in the Open Compute Project. But I see no reason that the lessons learned there can’t apply to firms that aren’t quite their size. We are driving towards an ecosystem where companies of any size can contribute to how networks, networking protocols, and even networking devices are developed, deployed, and evolved. We want to allow the users of networks to own their own destiny, and manage it accordingly.
Driving down the cost of owning and deploying networks
Networks are confusing. Worldwide networks even more so.
Think about all the things that make them up: routers, switches, network engineers, IOS, JUNOS, SROS, MPLS, IS-IS - that’s a whole lot of s’s. Who the heck understands all that? I can tell you that when we first started, Riot didn’t. Without sharing too much (#Garland4Life), let’s just say we made a lot of mistakes. And those mistakes have impacted our development velocity and network environment stability.
Riot understood software development - we wanted to make games, not build networks. We thought that our applications running slowly or our players experiencing lag was just a reality we had to accept. Then, when we realized that we might be able to fix some of this, we didn’t know where to begin. So we did what most companies do when faced with a problem they don’t totally understand - we threw money at it. In this case, that involved hiring vendors to help us with connectivity problems. And while we have many great partners, we’re often not 100% aligned - they want to sell hardware and network access; we want to provide the very best League experience possible. To them, 300ms latency was the same as 60ms - to us those numbers are worlds apart. This situation is how we ended up with NA game servers in Portland - our partners wanted us to leverage the great work being done by Facebook and Apple. That’s certainly a valid argument, but it wasn’t as focused on players as we endeavor to be. (I couldn’t be happier we remedied that situation with the server move to Chicago last year.)
In short, we really didn’t have the toolset to fix our networking issues by ourselves, and (as the adage says) if all you have is a hammer, everything looks like a nail. So we kept buying things that vendors told us would fix our problems, whether it be a new piece of hardware, or a new data center location. I think in part we got caught up in the challenges, and lost sight of what we value most: players.
Fortunately, somehow we found the space to take a step back, and the best parts of our tech culture kicked in. We quickly formed teams that understood the value we could deliver to players with the correct approach. And over the past year we have positively impacted the way players experience LoL, and provided a much better level of stability for our developers. Riot now spends less on internet access and internet facing networking than ever before, and we have better performance across the board.
To that end, I think three strategies we have employed are of particular note:
-
Bring technology-agnostic expertise in house
-
Create knowable and measurable networks
-
Utilize agile and lean development methodologies
The first point is probably the most difficult. Finding network engineering talent that isn’t preprogrammed to do things just one way is hard. During my time at Time Warner Cable, we built everything with Cisco products and life was great - until some things started breaking that Cisco couldn’t fix. (Not Cisco's fault, this is just the nature of how the industry evolved. Vendors are motivated to capture 100% of your business.) We brought in Juniper routers, but we had problems getting them to work in our Cisco environment. We couldn’t even get them to bring up an OSPF session. The culprit was different MTU values - a problem that never arises if you work exclusively with one vendor. Some network engineers decided the situation proved Juniper’s equipment wasn’t good - but others knew better. The former gave up. The latter did the work to understand the differences, learn an entirely new coding system (JUNOS versus IOS), and start thinking at a deeper level about the protocols involved.
The second point revolves around building transparency into the work of network engineers. To best focus on players, from the start Riot Direct’s mission included the ability to measure the performance of the technology we built. As we put load on the system, we could immediately show how it impacted the player experience. We could also measure our work in order to accurately forecast what kind of impact we could make on players’ behalf. While tracking metrics like the number of OSPF sessions, amount of data passing through an interface, or the number of processes per CPU are interesting, they might not be telling the whole story. To best understand the experience, we track latency, packet loss, and jitter as more impactful values.
The third point is that I believe it’s essential that we change the way we work as network engineers. In my experience, most networks are built slowly and with massive inertia - changing or pivoting them is extremely difficult. I believe we can change the product by changing development - Riot Direct works in two weeks sprints that allow us to quickly change and execute on our goals when appropriate.
Reducing the complexity of maintaining networks
While the last section dealt with improving how we work with the networks of today, this section addresses working with the networks of tomorrow. To spoil the ending: those networks won’t be built by vendors, they will be built by us, the networking community.
Open source has dramatically increased the velocity at which we develop software, and now that revolution is going to hit networking - and it’s overdue. Currently it can take years for features to be developed for networking equipment, which is still not nearly as robust as compute equipment. Consider a web server - I can easily set it up to stream data all day long. But if I ask a router one too many questions via SNMP, the entire box might reload. I’m not talking about super frequent polling - I have to poll less than once every 5 minutes! That is an eon in networking time.
Two concepts are helping bring routing into a place where we, the networking community, can actually tackle the issues above: DPDK and open source routing code. Today, using these two resources, we have built a router that can process 400M packets per second. That may not be huge in the service provider world, but it’s a start! And we believe that it is something that any company can do, at any size.
This completely changes the game on our internal network. We can now use common compute to build routing tables, and instead of polling devices for information using SNMP, devices can now live stream me data about the health of the network with updates every millisecond. We could even develop our own internal routing protocol, or make updates to an existing protocol if we didn’t want to wait on standards bodies. Similarly, we could even start building systems that diagnose network problems as they are happening, not after the network has already failed. This changes the game in the way we can understand and operationalize our networks. Below is output from our latency analysis tool - you can see several events that affect the player experience. In the future, we hope to mitigate such events automatically.
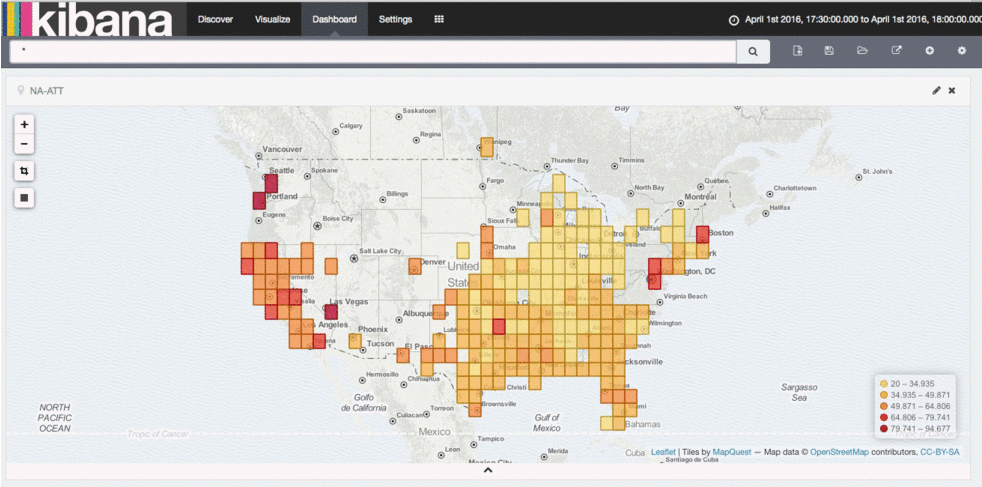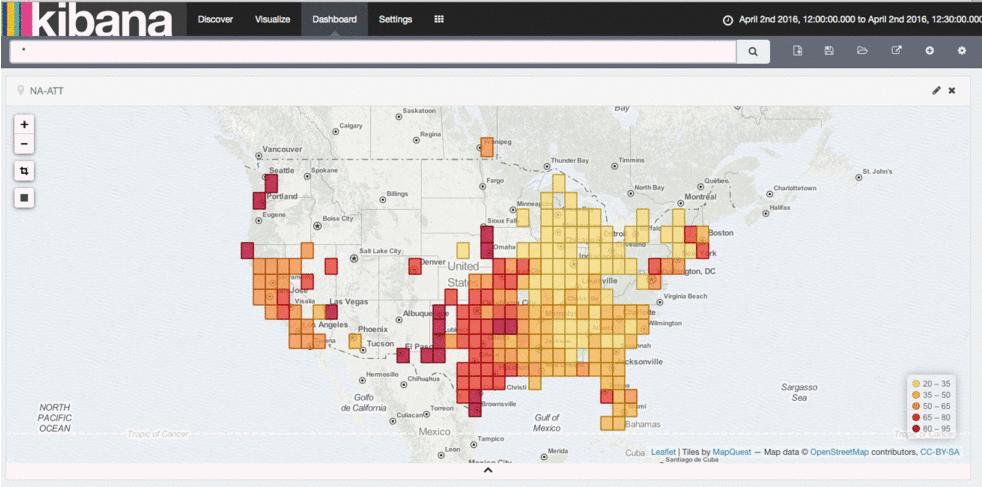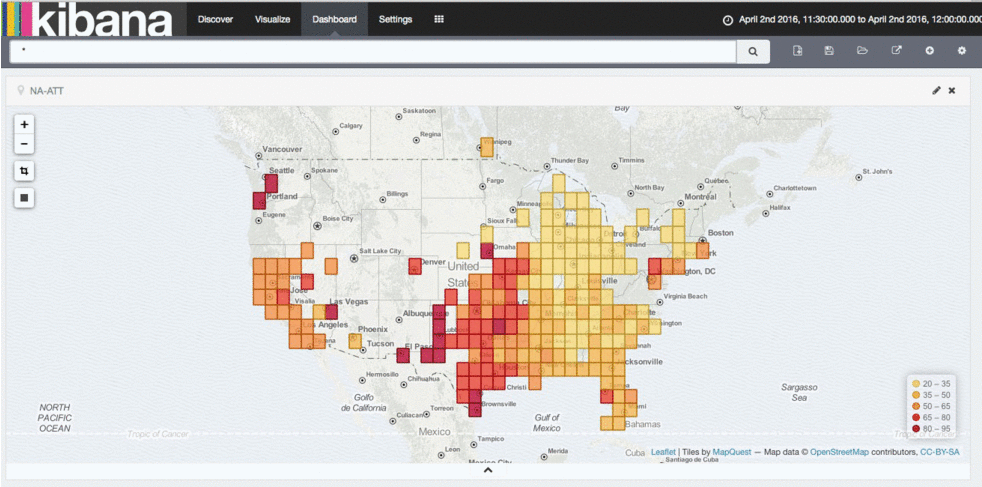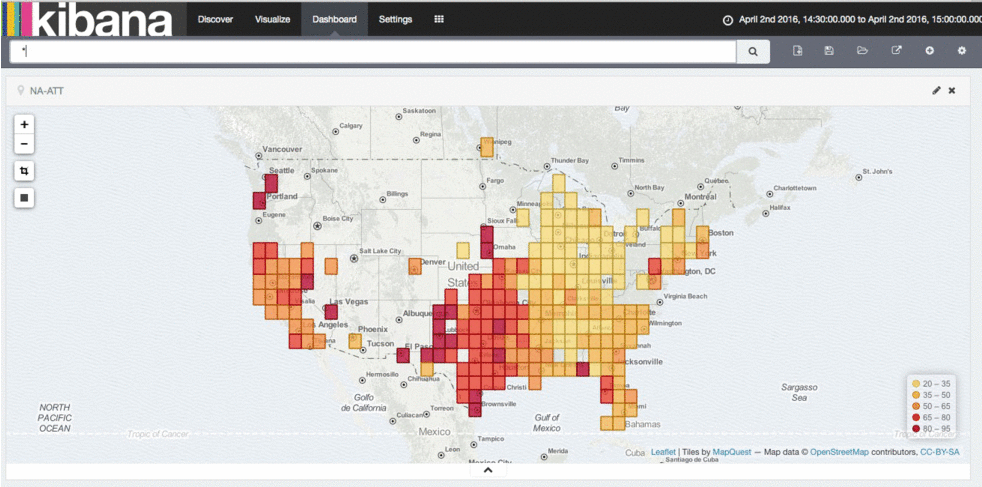
Latency analysis tool
Improving the peering workflow
Much of what we have talked about so far easily applies to internal networks, but this is a wasted conversation if we can’t effectively connect those networks to other networks. This is called peering, something I discussed in my last post - connecting with other networks and balancing routes is serious work.
How can we leverage these concepts to affect how we work with other networks? Well, Fastly wrote an article about how to scale Forwarding Information Base (FIB) tables outside of actual network hardware, on common compute. This allows them to peer with many networks, using hardware that was not originally intended to do so. They explain that they recognized that they didn’t need most of the features provided by the current routers on the marketplace, and that they could do everything they wanted using lower cost switches. But the switches could typically only hold tens of thousands of routes in FIB, which is orders of magnitude less than they needed. So they wrote their own software, Silverton, that manipulates the way the switches forward packets! Using less than 200 lines of code, they saved hundreds of thousands of dollars per POP site that they deployed.
In the article, Fastly states, “Freed from the shackles of having to obey the etiquette of sensible network design, our workaround took form relatively quickly.” This is exactly the flexibility that we want everyone to have. We want a network ecosystem that is free to build what we want, when we want it.
If you think about how this applies to Riot, physically connecting with other ISPs is only the first step. Afterwards, we have to work with those ISPs to “balance” their customers’ traffic so it is sent and received symmetrically. This can be a lengthy process, and some ISPs don’t have the capability to respond to our requests. This can be a big deal for us - our engineers spend 50% of their time chasing down routing inefficiencies.
Much like the situation Fastly found themselves in, we were shackled to using things like BGP to provide our players the best routes to our game servers. This remains difficult, as the landscape is constantly changing. In fact, we just had a large event last week where one ISP changed their network without updating their BGP settings - the result was players receiving terrible routing. We had to manually track down that change and work with the ISP to fix it. Currently that’s our only option, but we want to change that.
Our approach to improving this situation has been to build a system of “gateways” that allow us to steer traffic destined for our network in the appropriate direction at the earliest possible point (where we peer with ISPs), and then “pin” that traffic so that it returns exactly the same way. This completely removes the need for BGP balancing, and allows players traffic to choose the best route every time they play. This also allows us to use protocols like Anycast to help us verify that traffic arrives at the right gateway via the most efficient path possible. And we can do all of this ourselves using common compute, instead of using expensive and specialized networking hardware.
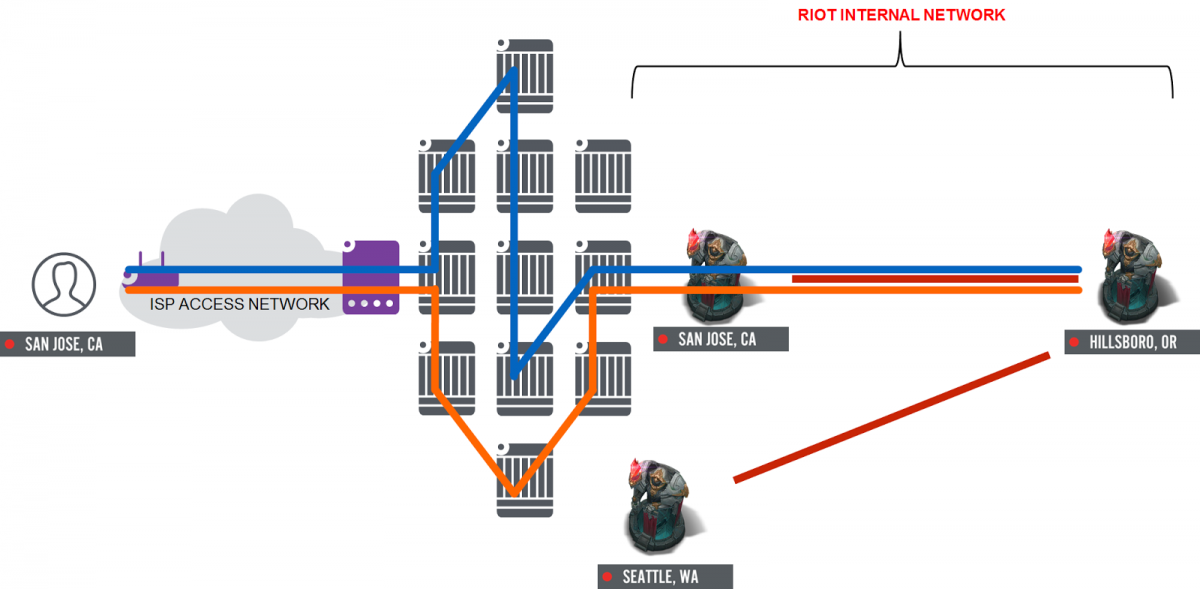
Without steering
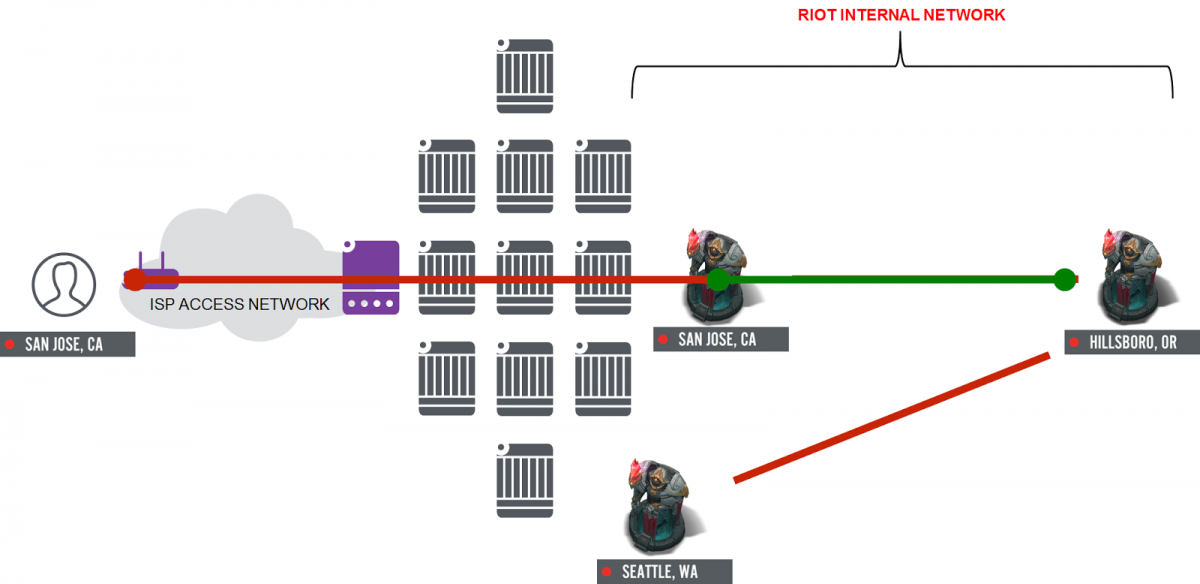
With steering
Conclusion
The larger gaming community is continuing to understand the impact that the internet and our own private networks has on our games, applications, and communication systems. Networks that aren’t built properly don’t scale; they’re a drag on application speed and can actually completely ruin a gaming experience. The experiences we are trying to build for players over the internet require networks that provide the best possible performance - but until recently we really didn’t know what that meant, or how to measure it.
But this is changing. More and more we see companies taking their future in their own hands when it comes to the internet, network device development, and network software development. Google, Facebook, Fastly, Amazon, and many others big and small are creating their own network software stacks and abandoning specialized network hardware in favor of common compute. They are hiring experts that deeply understand the protocols that drive these networks. They are creating open and transparent development systems that allow stakeholders to understand now the networks positively or negatively affect them.
Now some may ask, why did Riot, a gaming company, start down this path? Why did you commit all these resources? Why do we do this? The answer is pretty simple: we love players, we love games, and we love networks. I was talking to Macca the other day and he said something that really struck home with me. “Peyton,” he said (actually he used a nickname for me that I can’t repeat), “I am fixing the <redacted> internet for players! There are players with lag and packet loss and I have to <redacted> help them!”
Macca summed up exactly how we feel here. We are improving the internet for players. Being able to apply network engineering to make games better is one of the greatest honors I’ve ever experienced. And we want to use that passion and help anyone we can. We are going to continue to publish, co-develop, and advocate for an ecosystem that allows network operators to be able to develop and share their own solutions, quickly and collaboratively. And we believe that this will make the internet, and the networks that connect to it, more scalable, more affordable, and much more open.
This is a reality that I have wanted for a while, one that was always out of reach, but now I think we are on the cusp of a revival of network engineering. A revival that will allow game developers to build networks that support virtual reality, low-latency gaming, and any other application we can think of, one that evolves and iterates much more quickly, driven by the engineers that build them.
Continue the discussion
I hope you have enjoyed this series around the Riot Direct program. I have thoroughly enjoyed writing them, but the conversation won’t stop here. As we come up with new experiments, or have updates on old ones, we will come back here to talk about it. And we are looking for people that want to help. If you think we are on the right path, if you think we are crazy, if you are somewhere in between, and you love everything about networks, maybe you could help us. We want the best network ninjas working on these problems, and if you think you are one, reach out! We would love to meet you.
Thank you again,
Peyton
WizardoftheLake
For more information, check out the rest of this series:
Part I: The Problem
Part II: Riot's Solution
Part III: What's Next? (this article)