Fixing the Internet for Real Time Applications: Part II
In my last post I talked about how the internet is far from ideal for real-time applications like League of Legends and how the resulting latency and packet loss make for frustrating real-time game experiences. The next logical question is, “OK, Peyton, what do we do about it?”
The answer is simple and exciting: we build our own internet. Before you call that a pipe dream, let’s briefly recap the internet’s architecture from my previous post. The internet isn’t a single unified system owned by one entity, but rather a conglomeration of multiple entities. When you play League, data transfers from Riot’s servers to backbone companies (like Level 3, Zayo, and Cogent) to ISP companies (like Comcast, AT&T, Time Warner Cable, and Verizon) and then finally to your set-up (modem, router, computer), before making a return trip.
We’re not the first to tackle something like building a part of the internet; Google notably now runs fiber in some communities in the United States. But where Google is focusing on the cable running to your house, we’re more interested in creating a network like the backbone companies. This would allow us to pick up player traffic as close to the player as possible and then put it on our network—a network with many fewer routers (and other devices) that drop packets and degrade the player experience.
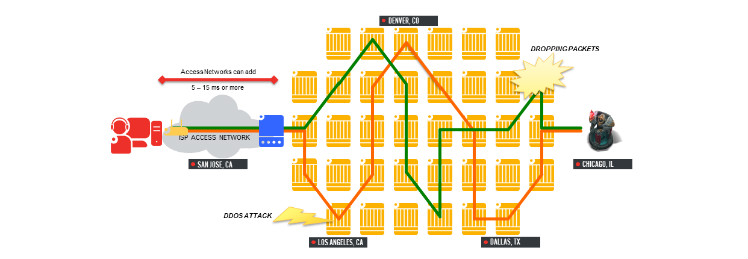
Basically we are taking this:
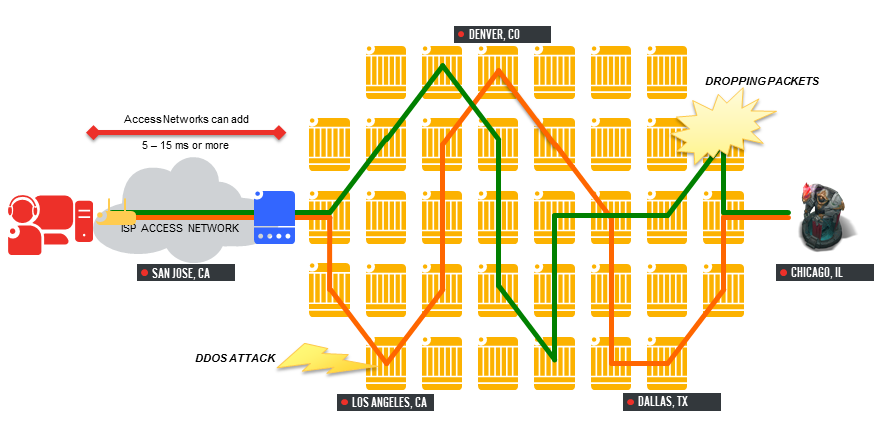
And turning it into this:

Easy, right? Well, uh, no—the endeavor took us over a year to complete. Connecting our servers to ISPs required us to first purchase routers, lease space to place the routers in ten of the largest internet hubs in the US (commonly referred as colocation spaces, more on that later), lease dark fiber or optical wave services to connect those routers, and finally peer with all the ISPs we could.
In this post, I’ll break down the process a little further, discuss how we’ve worked with ISPs to correct for some internet standards, and share some of the results from the effort.
ROUTERS, COLOCATIONS, DARK FIBER OH MY
The first step of purchasing routers was pretty simple. Afterwards, we needed to house them in a data center. Colocation spaces, or carrier hotels, are huge buildings that provide space and power for network operations equipment. Many operators can have a presence in the same location, and this “co-location” allows for them to easily connect with each other. For instance, we have equipment in Zayo’s space at a colocation in New York City, and we peer with all of the ISPs in that building.
While the presence of multiple network operators allows for us to connect with many at once, that unfortunately doesn’t mean it’s simple. Each connection requires a complicated physical deployment of equipment and an absolute mountain of paperwork. For example, consider our New York Point of Presence (PoP) I mentioned earlier, where Zayo, Telx, and Equinix (among others) also have a presence. Connecting with them involves buying services from Telx and Equinix, so our fiber arrives at the relevant patch panels in the Meet Me Rooms (MMR), as well as from Zayo to obtain a cross-connect into our own equipment. It takes forever.
We followed an exhaustive vetting process to identify the fastest fiber routes, find the best colocation spaces with the most potential ISP connections, and ensure the availability of Internet Exchanges (IXs) to reach even more ISPs. Once we placed and connected our routers within colocation areas, we needed to connect the routers across the country to one another. To do this we had to find dark fiber or optical wave services between each of the colocation areas. We contacted many companies, obtained information on their routes, and then physically compared each one. We have seen the fiber routes between two locations from one company be fully three times longer than the route from another.
Other complications can arise, and they’re easy to overlook. While investigating a route from Chicago to Los Angeles that passed through Seattle, we noticed that it leveraged the same piece of equipment as the existing route between Chicago and Seattle. Using both routes would introduce a single point of failure into the system—if the Seattle router went down, it would result in too much pain for LoL players. We knew we had to keep searching for the ideal Chicago to Los Angeles connection.
Even with all of that in place, we still faced lengthy contract negotiations with the ISPs that service players in order to directly access that player traffic. The whole process was a long and arduous one - a single contract took just shy of eight months to finalize - but I won’t bore you with the details here.
WHY NOT MAKE IT EASIER?
Given the difficulties I’ve outlined, you might ask why we didn’t just pursue a contract with major carriers like AT&T, Comcast, or Level 3 to do this for us. The simple answer is that we tried, and it didn’t work. Unfortunately, their business models and our requirements don’t match. ISPs build networks that are much like public transit in that they want to pick up traffic in as many locations as possible. A reduction in the number of participating routers would lower latency (yay for LoL players), but it would also lower the number of customers they could support. ISPs also build their networks with other companies that they consider partners, meaning capacity purchase decisions are driven by vendor relationships rather than what’s best for one particular application.
So, for instance, if AT&T was our provider, they wouldn’t peer directly with Comcast to get us closer to Comcast players, because they’re not partners. Nor would they remove any routers from their network for us to make the network as efficient as possible. Their goals are understandable for them, just as ours are for us; unfortunately the two don’t overlap. We want to reach players in the fastest way possible, regardless of who the player’s ISP considers a partner, so we had to create a “neutral” entity that could peer with anyone.
Additionally, no large internet carrier’s physical infrastructure (e.g. Zayo, Level 3, or Cogent) meets our needs. As a hypothetical, imagine carrier X and Y both connect NYC and Chicago, and that carrier X’s connection is faster. However, carrier X doesn’t connect Chicago and Seattle, but carrier Y does. Therefore, neither company can sell us an optimal backbone service. To provide the best experience to players, we have to contract with both carriers to piece together that optimal network.
SETTING THE STANDARD
Building our own backbone is only one piece (albeit a major one) of our larger strategy to adapt current internet infrastructure to the needs of real-time games. On top of the physical and contractual issues, there are technical challenges to overcome. In addition to peering with ISPs, we had to work with them to identify the most efficient use of historical internet standards.
There are rules to how internet traffic travels that haven’t changed much—they still work for many types of traffic, but for our real-time non-buffering application they create issues. In particular, the standard routing protocol of the internet, Border Gateway Protocol (BGP), has caused us large amounts of pain. We want traffic to take the best path - not just any path - and BGP is really built for commodity routing by default. Put another way, BGP thinks of the network in very simple terms: how to move traffic from one network owned and operated by one entity, or Autonomous System (AS), to another. However, most carriers and ISPs don’t properly leverage BGP to build solid routing paths.
Consider the common use of values like BGP’s “session age,” a measure of how long a particular route has been in use. Imagine two routes between Riot and a particular ISP: a faster route A and a slower route B. If route A goes down, the traffic moves to route B—certainly a reasonable shift as it’s the best available route. The problem occurs when route A comes back up as the ISP will continue to use route B simply because its session age is older, and therefore automatically preferred. This is done because it’s the default behavior of the protocol, and for ISPs with large amounts of peers it requires less work than manually rebalancing to the correct route. We’ve had to find workarounds such as taking route B down intentionally to move that traffic back to route A.
On top of things like session age, we also had to consider how we receive and deliver traffic. In most instances an ISP is located in one geographical place, so this is easy. For ISPs with locations across the continent, however, we have to peer in multiple places. For example, consider Comcast, which has routers across the country. If we connected with them only in Chicago, traffic from players on Comcast in, say, Boston would stay on their network all the way to Chicago—bypassing the very backbone network that we’ve built. To solve this problem we peer with Comcast in multiple places, creating more access points to our backbone. When we connect to one of Comcast’s regional peering routers, all Comcast traffic from that region is put directly on our network.
There’s yet another issue when considering traffic going in the other direction. While BGP leverages a number of data points to route traffic to and from ASs, its natural state is to find the “closest” exit. In other words, BGP accepts traffic coming to our data center via the best entry point, but it chooses a single exit point for all traffic headed in the other direction instead of identifying the best option.
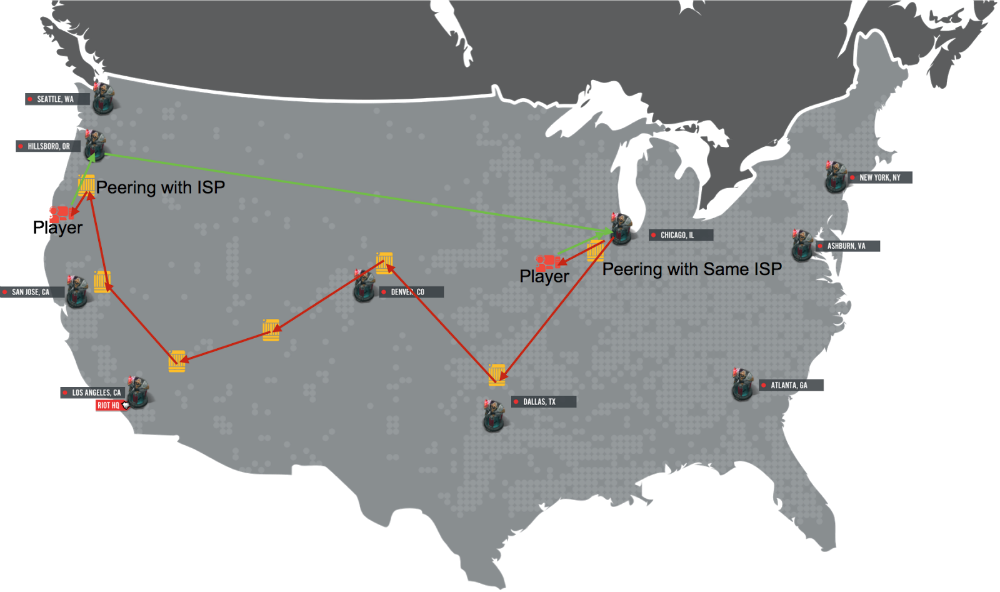
As an example, when we first started building our backbone, we peered with an ISP in Portland and Chicago. Chicago players entered our network via the Chicago peering point, and when we sent traffic back it would take the exact reverse path. However, when Portland players entered our network via the Portland peering point, the traffic we sent back went out of Chicago, not Portland. This occurred because when the ISP peering router picked up traffic from Portland, its fastest path to our AS (6507) was right there in Portland; however, when the game servers send traffic back, BGP computed the fastest logical path to the ISP's AS was out of Chicago. We had to work with the ISP to fix this by having them mark their traffic using BGP Communities or MED preferences, which allowed us to install rules around sending traffic back correctly.
This was a lot of work! And unfortunately, not all ISPs do this—while we might peer directly with an ISP, players may still not receive the optimal experience.
THE RESULTS ARE IN
Given all the barriers to entry I described, you might think that this venture was doomed to fail; however, we worked through each phase slowly and steadily to obtain a promising result. Based on what we’ve built in North America, we’ve actually created one of the fastest networks on the continent. And now with the experience we’ve gained along the way, we can improve exponentially upon what we’ve built.
But the real test comes down to what this all means for players. One of the ways we measure this is to look at how many players play the game at under 80 ms ping. In the period before our move to Chicago, we increased that percentage from 31% to 50% in just over nine months, as we began peering with ISPs and started the work toward Riot Direct. You can see the overall climb in the graph below.
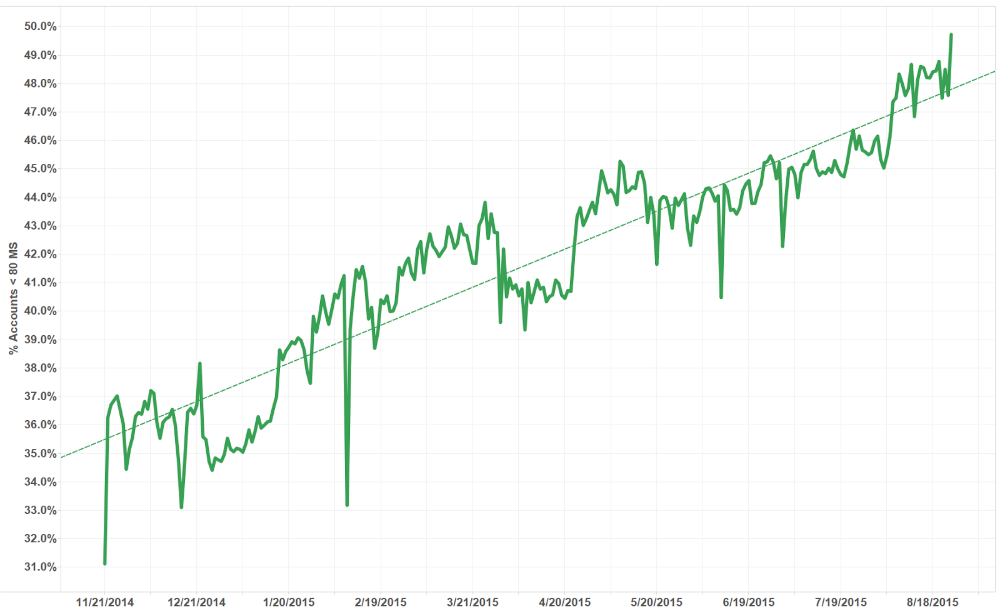
Riot Direct Impact 11/21/2014 - 8/18/2015
This doesn’t mean that every player saw better service, but overall more players than ever were playing League at a healthier ping. Once we made the move of game servers to Chicago, the numbers get even better. We increased the percentage of players from 50% to 80% overnight! In terms of success for players, we hit our internal goals and then some.
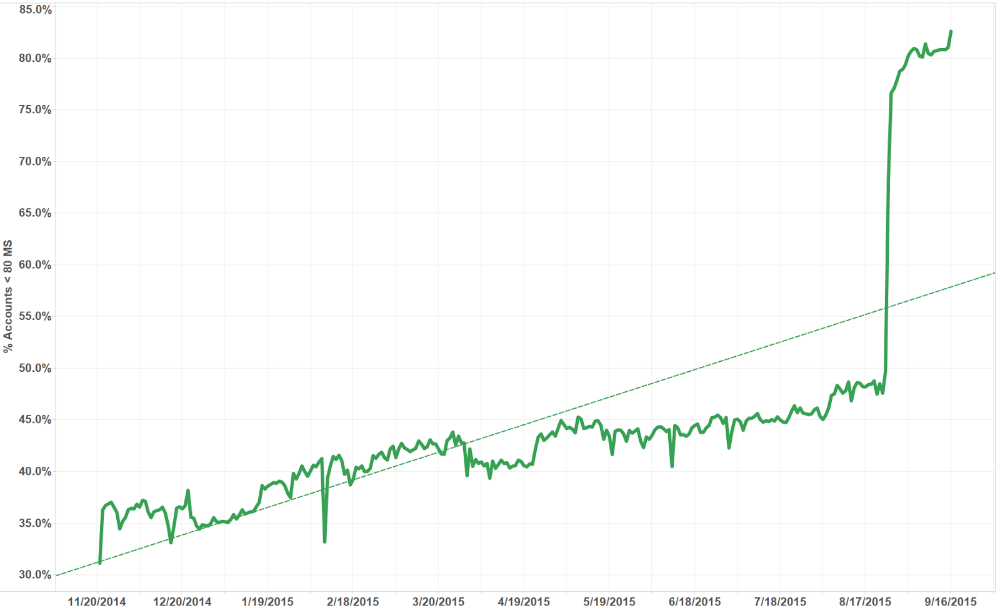
Impact of the Chicago Server Move
We continue to work with ISPs and carriers to make this an even better experience for players, and we are, in fact, doing this worldwide! We actually have networks on every continent except Antarctica and Africa.
We’re excited to keep improving the player experience on a global scale, and there’s certainly still a lot to do. We believe that games deserve their own network, and that old technologies like BGP just don’t scale for games. In the next part of this series, we’ll talk about new technologies we’re investigating and building to enable a better environment for online games.
For more information, check out the rest of this series:
Part I: The Problem
Part II: Riot's Solution (this article)
Part III: What's Next?