Content Efficiency: Game Data Server
Hey, everyone! I’m Bill “LtRandolph” Clark, a League of Legends gameplay engineer. Many Rioters in engineering focus on the delivery of awesome content directly to players—a couple of my recent favorite examples include the newest champion, Jhin, and the support item reworks. My team, on the other hand, works to make that process faster and easier.
We have a simple goal: to allow Rioters on gameplay projects to create twice as much content for any given LoL patch. That’s easy to say, but it’s a challenging task.
Today, I’ll discuss the foundation that we’re laying down to power this acceleration: the Riot Game Data Server (GDS). While this will be a technical article, I’m going to keep the commentary at a fairly high level. If you’re an engineer working with data spread across a number of systems, I hope this will be of particular interest.
Game Data
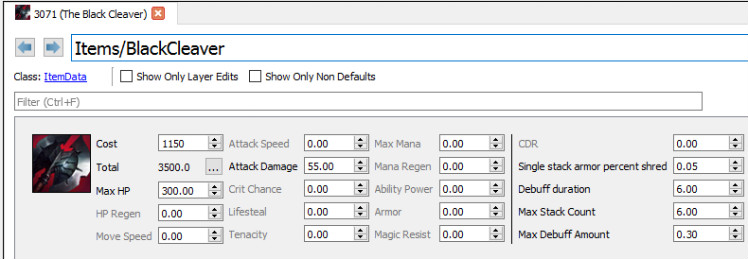
Let’s start with some background. Working on LoL, there are two types of game data: key-value pairs called property data (e.g. Black Cleaver HP bonus is 300), and blobs of opaque binary data (e.g. textures, animations, and sounds). In this post, I’ll only be discussing property data and will leave binary data for a potential future post.
For all of LoL’s history, property data has consisted of a bunch of loose files sloshing around in a big bucket of a folder called DATA. Within that folder, we stored the data primarily in .ini files (yes, the Windows .ini file format). It looks like this:
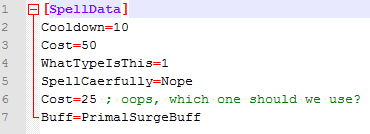
Obviously I constructed this example to highlight some of the common problems we encounter when editing .ini files. This is far from a user-friendly interface. It’s extremely easy to mess up when editing raw text—some fields lack important context, and other fields are duplicated. To further illustrate the sort of confusion that designers have to deal with every day, there are 977 spells that feature the (certainly ignored) line “MissileEffect=AnnieBasicAttack_mis.troy,” and every champion references a delightful field from very early in LoL’s development: “Death=Cardmaster_Death.wav.”
Some of the key problems with our current data system include:
-
Notepad++ used to edit property data
-
No clear definition of which fields exist
-
No type safety
-
Merge conflict issues when multiple people hit the same file
-
Cumbersome concurrent versioning (Live vs. PBE vs. internal)
-
Loose links between files; just short name and implied search paths
Game Data Server
We specifically designed Game Data Server as a system to address these problems. The foundation is RiotGameDataServer.exe—a small program that runs on every developer’s machine. It shows up as a Riot fist in the taskbar, and its job is to communicate property data to the rest of the programs on the computer.

GDS abstracts away all of the file and data management for other tools, so those tools can focus on delivering the desired viewing and editing experience. I consider it similar to an operating system’s abstraction of window creation so a developer can focus on what should appear in that window. The tools that talk to GDS include many internally developed tools, as well as third party standards like Maya and Photoshop. They all communicate with GDS via a JSON-based RPC API.
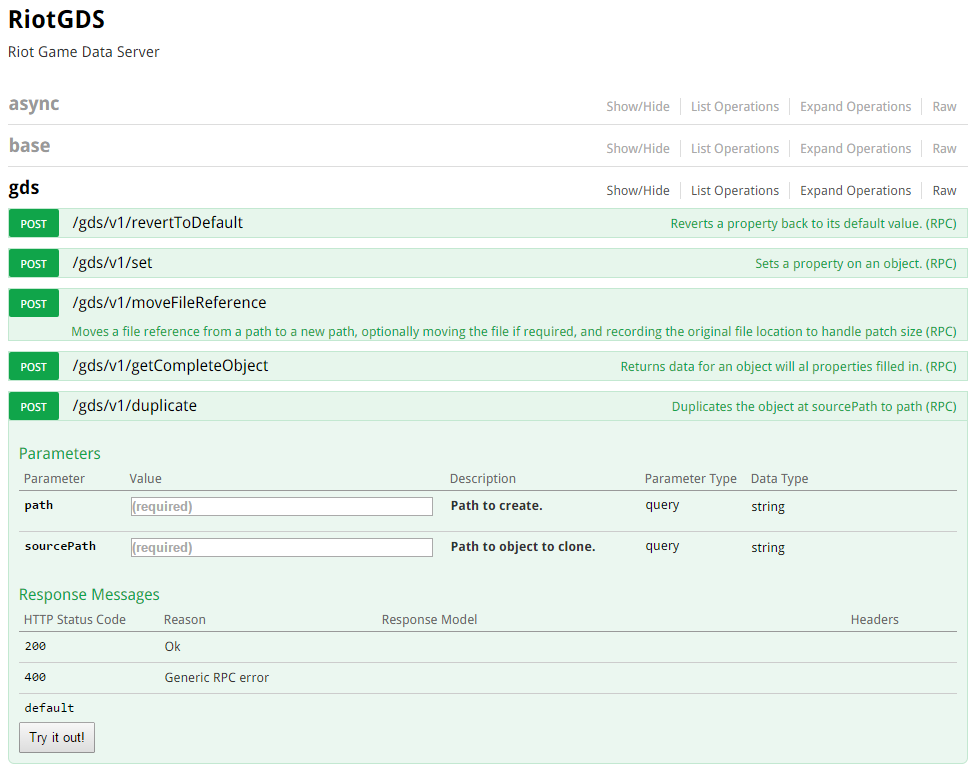
One of the neat things about RPC APIs is that we can easily spit out a documentation page using a standard called Swagger, which will list all the functions that are available. Here’s a small subset of the functions that the GDS exposes:
GDS property data lives in a folder appropriately named PROPERTIES. This folder will eventually contain all of the property data for League of Legends. When a tool needs to identify the specifics of what makes Black Cleaver into Pantheon’s favorite weapon, it issues an HTTP request to localhost:1300, where the GDS is listening. When a request is made to “get?path=Items/BlackCleaver”, GDS looks up the file at PROPERTIES/Items/BlackCleaver.json. Here’s what that response looks like:
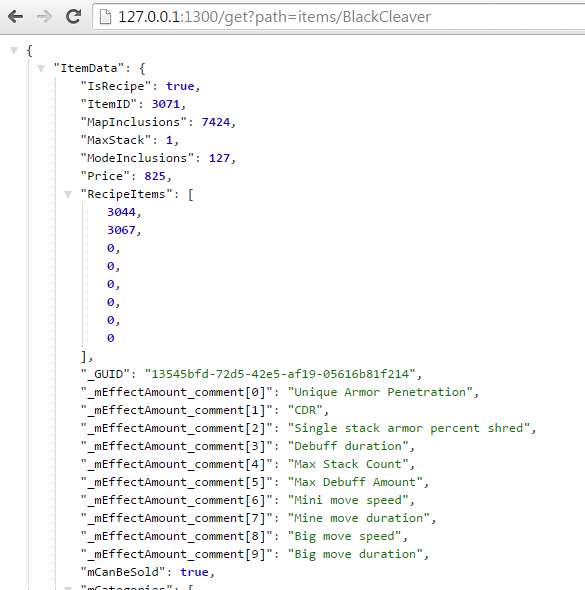
When a tool wants to change how much health Black Cleaver gives, the tool will issue another command to localhost (or 127.0.0.1) on port 1300, this time issuing “set&path=PROPERTIES/Items/BlackCleaver.FlatHPMod&value=1000.” The GDS will check the file out from source control (Perforce), edit the value, and report back success or failure via the page that returns. Thus, any tool we make can easily edit property data without having to think about the data format, file operations, or any other complicated considerations.
This lets us easily create tools like RiotEditor, shown below, to solve problem #1: Notepad++ used to edit property data.
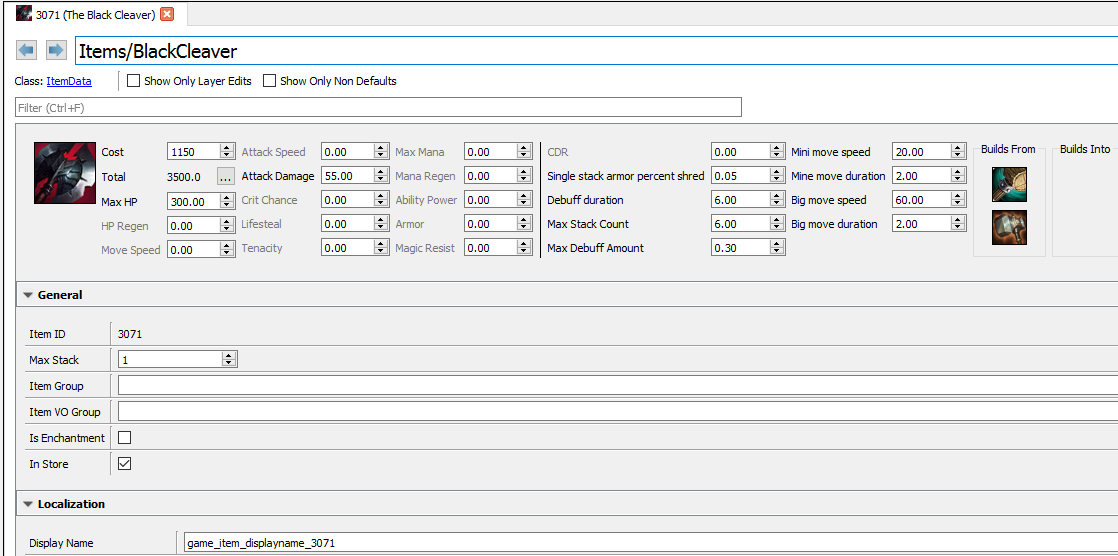
Now we're getting somewhere
Property Markup
For any given type, it’s important to identify which fields actually exist, so we know what to let the user edit. To do this, we maintain a set of interlocking macro and template magic that allows us to markup types directly in the engine code. Here’s what that might look like:
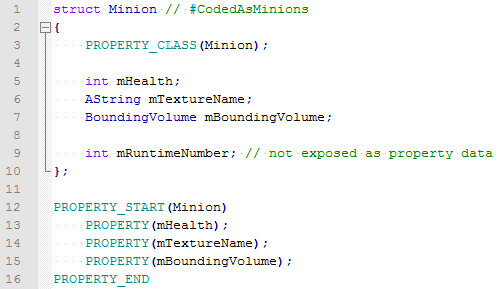
Note the macros: PROPERTY_CLASS, PROPERTY_START, PROPERTY, and PROPERTY_END. These are responsible for two major tasks:
-
Telling the definition exporter what classes exist, and which of their fields should be editable.
-
Telling the property loading system the memory offsets to shove the property values into at run-time.
The PROPERTY macro automatically infers type via simple template function specialization. We can reference complex types, like BoundingVolume, provided they have their own sub-properties tagged up. And we can also skip fields, like mRuntimeNumber, meaning they won’t be exposed to GDS.
Here’s the resulting JSON definition that the GDS will use:

Aww yiss
This property markup solves problems #2 and #3: No clear definition of which fields exist, and no type safety, respectively.
Layers
In addition to GDS abstracting away file and data management for other tools, the other really cool thing that it provides to Riot developers is a technology we call “layers.” A layer represents a feature that can be turned on or off, and we can create a layer for a new champion, a new skin, a game mode, or a major rebalance. Then, whenever a content creator works on a feature, they can tell GDS to make, as an example, the APItemRework layer the “active” layer.
Afterwards, GDS tags any changes made to any file as part of the APItemRework layer. On disk, this looks like one file called RabadonsDeathcap.json, and next to it another file called RabadonsDeathcap.APItemRework.json. In that second layer file, GDS simply marks the delta of each field that has been changed. The before and after values are saved to reconcile merge conflicts later. Here’s a side-by-side view of what these two files might look like:
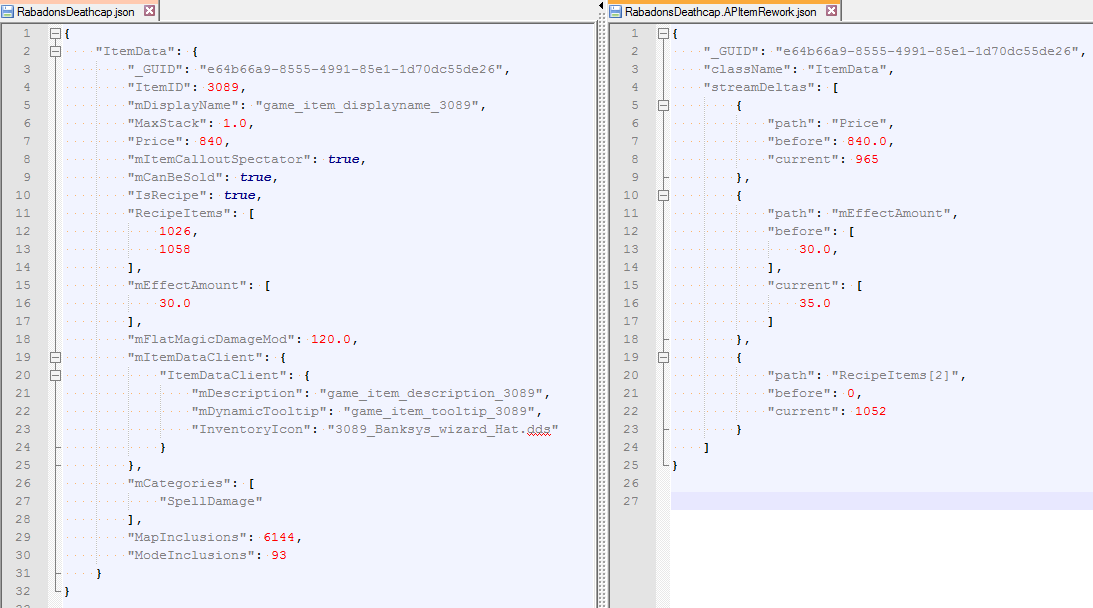
Since we’re capturing only individual field changes we no longer need to worry about multiple Rioters editing the same file simultaneously unless they’re changing exactly the same field. And if they do change the same field, we have the before and after saved out, so we can identify the conflict. This benefit would’ve prevented a bug we shipped to live: while creating DJ Sona, the team accidentally reverted her stats to an old level.
Now, we’ve solved problem #4: merge conflict issues when multiple people hit the same file.
Layers let us capture all of the changes that are associated with a particular feature. To actually ship those features, we bring in a concept called “game versions.” A game version defines a complete version of the game by turning on a set of layers. Each game version is saved out as just a simple JSON list of layer names. At any given time, we maintain a few major game versions:
-
Alpha: the set of features that we’re testing internally and preparing to publish to PBE.
-
Beta: the set of features that are currently on the PBE, like Jhin. Notably, Beta inherits the list of features from Release, so it will also have recent changes, like the preseason available.
-
Release: the set of features that are currently on live servers, like the shiny new patch 6.3.
The cool thing here is that moving a feature from one version of the game to another is a single drag-and-drop operation in our layer management window, making it so that we no longer need to drag hundreds of files from place to place when we’re changing what’s available where.
This makes it easy for us to solve problem #5: concurrent versioning (Live vs. PBE vs. internal) via full-file overrides.
Summary
Hopefully this article gave you a sense of how we’re helping make LoL development more efficient and effective. For careful readers, you probably noticed I didn’t dig into problem #6: loose links between files; just short name and implied search paths. I left the solution out because the problem’s more of a monster than anticipated — there are issues of redundancy, avoiding unnecessary code refactors, incremental data porting, patch size, and more — and it deserves its own dedicated blog entry.
Be sure to let us know in the comments what you’re curious about as we change how we wrangle the game data that defines League of Legends.
See you on the Rift!