
Blitzcrank Bot
Hey everyone, my name is Michael Hill and I’d like to introduce you to Riot’s automated ticket agent, Blitzcrank Bot.
The Problem
Player Support receives around 12,000 requests a day, mostly in the form of support tickets. Keeping up with those requests and helping players get back into the game as quickly as possible is an ever-growing challenge. In the early days, we could simply staff up to meet demand, but the cost associated with adding more support agents grew over time as it became more difficult to manage multiple agents across multiple organizations. Responses to players were taking up to 25 hours, and requests were taking up to 3 days to resolve on average. We wouldn’t want to go through that, and we knew players wouldn’t either. We needed to scale our support efforts and reduce response times.
We dug through our data and found that a whopping 70% of support requests were resolved within the first response or “touch” from a Player Support agent. That got us thinking - what if we could automate certain types of interactions? Based on our personal experiences with automated ticket systems, we had reasons to be wary. Many systems seem to put cost-cutting first on the priority list, pushing user experience to the back burner. Some systems prevent users from reaching a human agent until self-diagnosis of the problem is ruled out. Some omit the option of speaking to a human altogether. As players ourselves, we understand how frustrating it can be when a problem stands between us and playing the game. We didn’t want to offload problems or create barriers that compromise the support experience. Instead, we wanted to automate unnecessary pieces of the process so that agents could focus on leveling up the player experience in other ways. If we were going to leverage automation, the experience had to be as good as or better than what we were already delivering. To take the leap, we set our key metrics of success: player satisfaction followed by wait time.
With our priorities in place, we got right down to business. First-touch resolution tickets usually follow a simple process: identify what the player is asking about, then follow some pre-defined steps to solve. In a perfect world, players would correctly assess their own problems with 100% accuracy when submitting a request. But then they wouldn’t need to submit a request in the first place. Issues aren’t always straightforward, and we found that players select the correct issue when creating a ticket about 80% of the time. Beyond that, ticket submission forms aren’t specific enough to diagnose every issue.
Enter: Machine Learning
Surely our millions of tickets worth of data could help us out here. We saw an opportunity to train a machine to categorize issues for us based on the information submitted by players. For this task, python and its fantastic scientific libraries were a perfect fit. Armed with scikit-learn and numpy, we set out to test whether this was possible. We started off by analyzing the text within ticket subjects and descriptions. After splitting tickets into main issue types, we built a multi-class classifier and attempted to sort test tickets. The early results were promising, but we needed the flexibility to add new classifications without storing and rebuilding the entire multi-class classifier on each dev’s machine. Binary classifiers seemed to be a perfect fit, allowing us to make a classification in isolation and then test its effects on other classifiers after optimization. After much testing, we were able to classify 20% of account recovery test tickets with about 70% accuracy.
The Method
Let’s say we have a group of account recovery tickets from players who have lost access to their accounts. We can tokenize the words in the ticket subjects, and sum the number of times we see them.
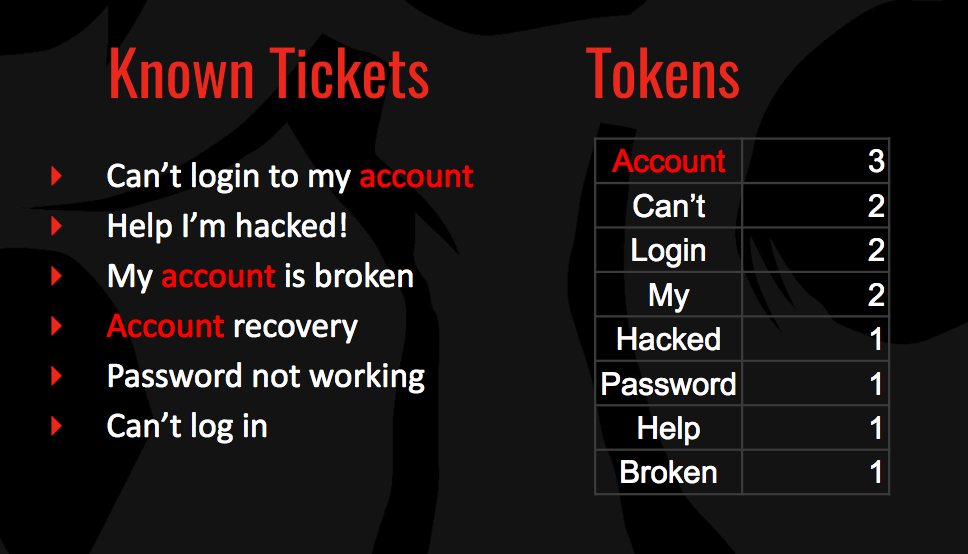
Next, we can take the subjects of tickets we haven’t classified yet and tokenize the words. We can then sum up the values for each token to get a final score.

Now we’re cookin’! As you can see, account recovery issues bubble to the top. Here’s a little sample code to show the concept:
from collections import defaultdict
subjects_known = [
"Can't log into my account",
"Help I'm hacked!",
"My account is broken",
"Account Recovery",
"Password not working",
"Can't log in",
]
subjects_unknown = [
"Help I can't log in",
"Dude where's my runes?",
"Hacked account",
"1000 RP Never Forget",
]
token_counts = defaultdict(int)
for subject in subjects_known:
for token in subject.split(' '):
token_counts[token.lower()] += 1
for subject in subjects_unknown:
count = 0
for token in subject.split(' '):
count += token_counts[token.lower()]
print("{}: {}".format(subject, count))From here we can feed this data into scikit-learn’s binary classifiers and generate some models. We train it by feeding in each field score for each ticket, and whether that ticket fits into the classification or not. Afterwards, we can make predictions with our model. Choosing the right classifier can be tricky, and usually involves trial and error. To get a visual understanding of how binary classifiers divide 2-dimensional data, check out sklearn’s examples. In our case, we fed multiple data sets (representing different types and quantities of tickets) to all major available classifiers and picked the top performers to compete (more on this later).
From this point, we’d proven that text classification was a viable tool for automatically answering tickets and we needed to build a workflow around it. We set out to build a fault-tolerant system that we could train quickly to resolve new issues and integrate into Player Support’s workflow alongside agents.
We came up with a system that split the work into two major phases. First, we’d classify tickets into issues based on ticket fields alone. Second, we’d collect back-end player data and respond to issues accordingly.
Classification
Our ticket classifiers are binary classifiers. Their main responsibility is to determine whether a player is writing in about a specific issue (e.g. French account recovery) or not. Building a classifier follows this general flow:
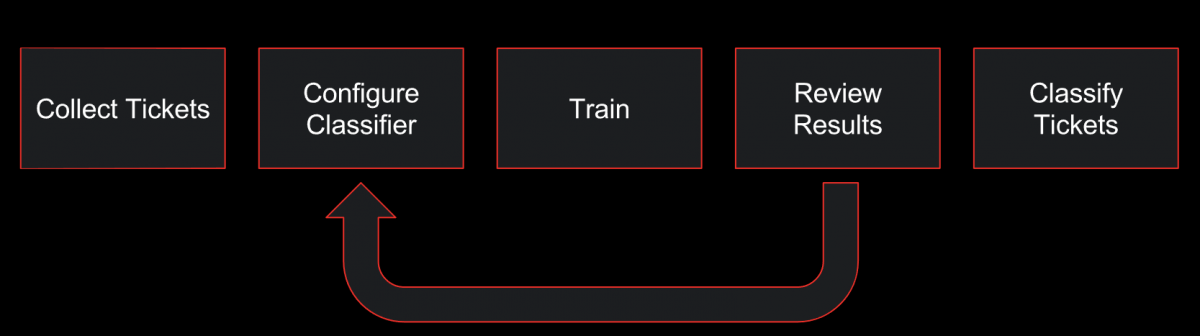
In most major languages we support, we can start with a group of about 100k completed support tickets to use as training data. We then write a basic configuration that contains an identification function and a list of fields to analyze (such as subject, category, and description).
Here’s an example of one of our live classifiers:
# Unchained Alistar
# Some players writing in completed the Youtube promotion, but did
# not receive their Unchained Alistar skin. In this case, we grant
# them the skin if they do not have it
META = {
"id": "unchained_alistar",
"language": "en",
"description": "Distributes dank skins to players in need"
}
# Tickets with either of these tags are resolved "Unchained Alistar" tickets
TAGS = set(['m_missing_alistar', 'game_skins_unchainedalistar'])
# Classify function returns true if a completed ticket
# has any tags in the tag list
def CLASSIFY(ticket: dict):
tags = set(ticket.get('tags', []))
return not tags.isdisjoint(TAGS)
# Classify the tickets based on analyzing the subject and description
FIELDS = [
TokenizedField('subject', NgramTokenizer(ngrams=(1,3), stop_words=STOP_WORDS['english'])),
TokenizedField('description', NgramTokenizer(ngrams=(1,3), stop_words=STOP_WORDS['english'])),
]
You may notice that we specify n-grams and stop words - tokenizing up to trigrams and removing stop words helped increase accuracy.
Afterwards, we spin up the classifier as a microservice (hooray microservices!) and post the set of training data to it. The classifier will analyze each field and generate a numerical value for each, using the method demonstrated in the examples earlier.
Thunderdome: 7 classifiers enter, 1 classifier leaves
From here, the classifier server generates models using multiple ensemble and svm classifiers. A target precision is set, and each model’s recall is measured against the others. In other words, we decide how accurate we want the classifier to be, and then pick the model that will identify the most tickets within the classification.
At this point we inspect the results of our test classifier and ensure that our data is accurate. We generate and visually inspect precision/recall curves for each model, graphs for each feature we analyze, and a list of classification results. We’ve found combing over the results, specifically false positives and negatives, to be the most time-lucrative way of improving accuracy. In our case, our training data relies on support agents accurately tagging tickets they respond to. Because we didn’t enforce proper tagging until recently, much of our older data is inconsistent. Looking into the top false positives helps us pick out other tags agents used to categorize tickets and adjust our classification accordingly. After making tweaks, we re-train the classifier and give the models another shot. We repeat this until our classifier has reached our target accuracy, or we reach diminishing returns on cleaning up the data.
Once the data looks correct and a model has proven itself worthy, the classifier server is ready to make predictions!
Ticket Handling
Once we have our classifiers ready, how do we respond to tickets you might ask?
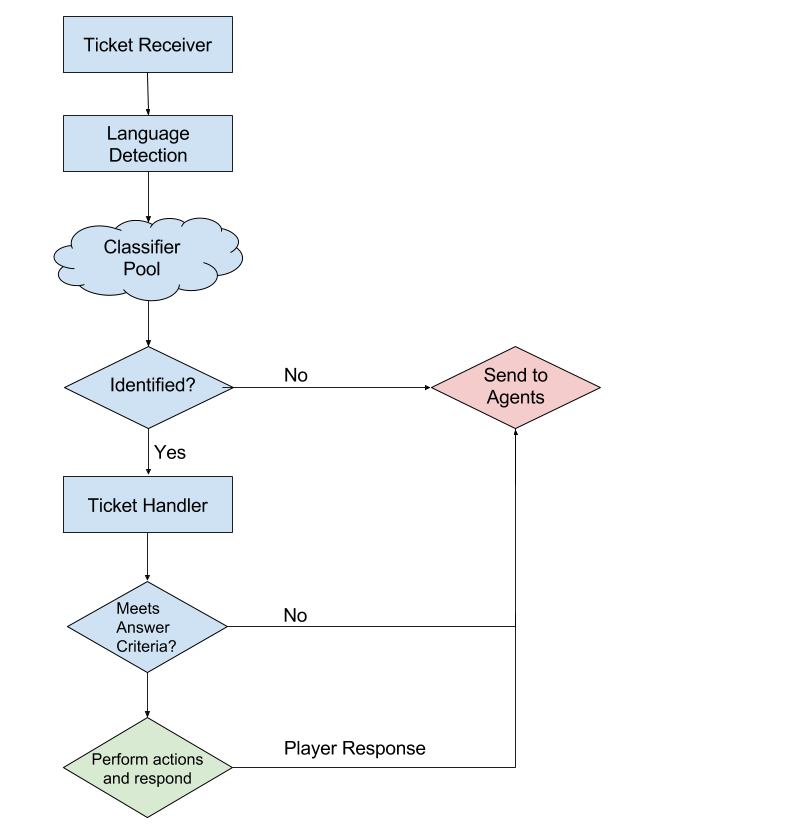
The first thing we do when we receive an incoming ticket is detect its language and query the corresponding pool of classifiers. If the ticket fits into one of the classifiers with high confidence, the ticket is then forwarded to the handler service for that issue.
From this point, ticket handlers are programmed to follow the same logical steps that an agent would to solve the issue. In most cases, this means following the agent runbook for the issue in question. For example, some players write in asking for Unchained Alistar because they encountered an issue with the youtube promotion (an issue which has since been fixed). First, we check if the player is writing in from a region that supports the promotion. If not, we send a “Not Available” response. Next, we check for Unchained Alistar ownership. If the player already owns the skin, we escalate the request to an agent as the player may be asking for something else. If not, we grant the skin and send a response. Easy peasy.
As you can see, some paths lead to sending the player to an agent. We never want to stick players with a robot when they need a human. We know how frustrating it can be to feel like you’re not getting through, and we don’t ever want to provide that type of experience.
Ticket flow and responses are handled directly within our ticketing system, Zendesk. This makes new flows easy to implement and visualize, and also empowers our agents to make changes to Blitzcrank Bot without any engineering experience.
What does a response look like?
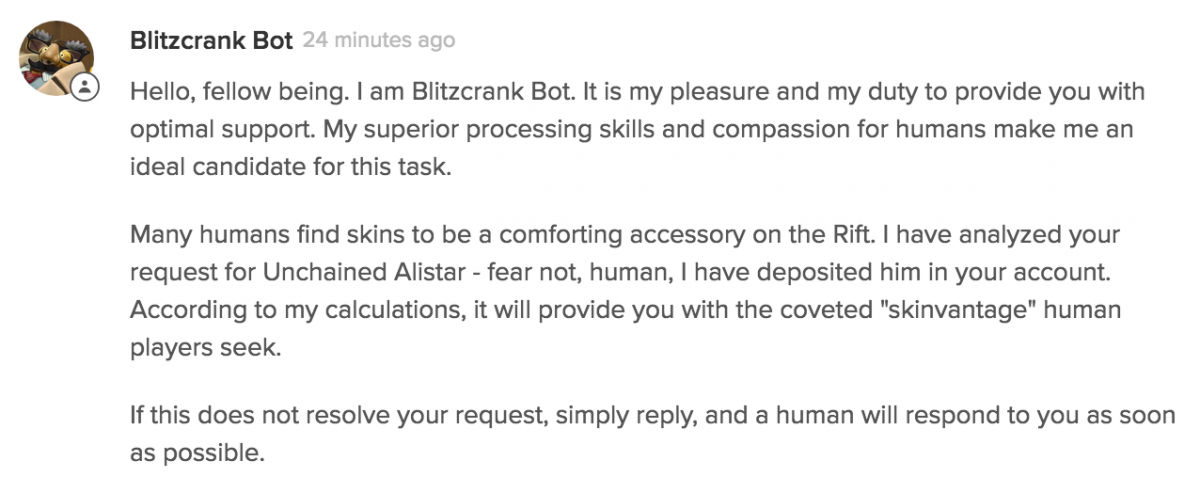
We approached the look and feel of the automated response with caution. Players had previously called us out for automated-style responses, so we worried about what would happen if we actually became robots. We decided the best way to address the issue was to be upfront about our use of automation. We also wanted to add a touch of personality to the system, and who better to represent us than Blitzcrank, a robot who desires so much to be a human? A response from Blitzcrank Bot is friendly, whimsical, and themed to fit League of Legends.
How did it do?
When we first launched, we were able to identify 52% of account recovery tickets with about 93% accuracy. However, we noticed a significant dip in player satisfaction when compared to our previous agent-only interactions. We looked at the feedback and found that players felt they were being blocked from receiving help, even if their issue was resolved. The perception problem we’d considered earlier was real.
We attacked the issue on both the support web site and in our automated responses. First, we added a new checkbox to our ticket submission form that allowed players to opt-out of ticket automation before they even created a ticket. Next, we changed the last part of Blitzcrank’s responses from “If this does not resolve your request, simply respond,” into a giant “REQUEST A HUMAN” button for maximum visibility.
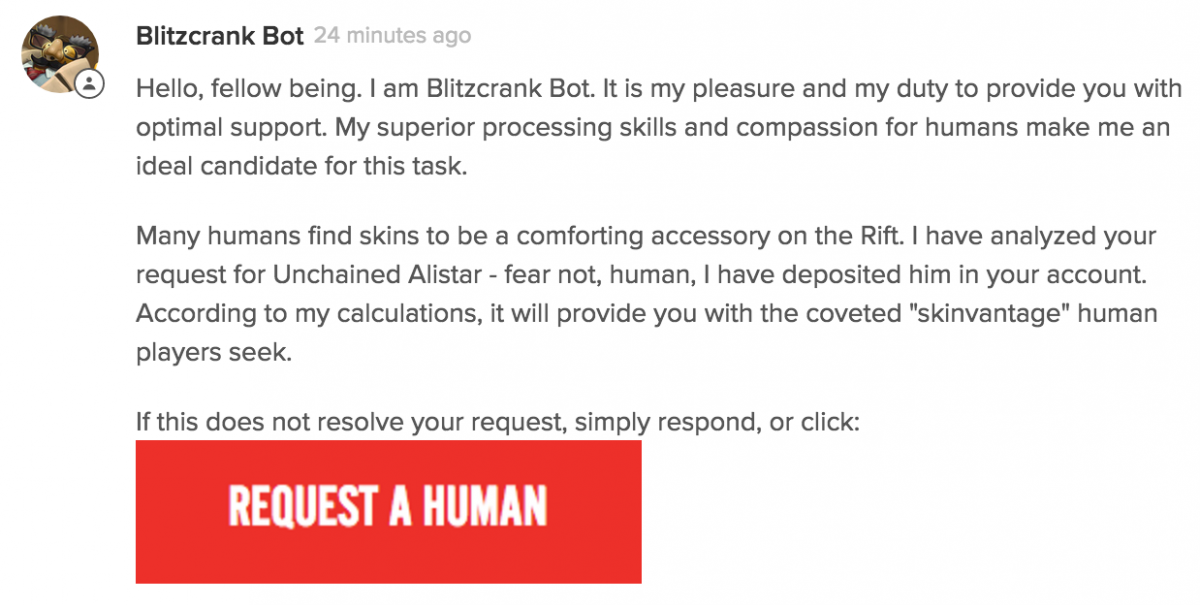
Contrary to what we thought would happen, most players didn’t opt-out of the automated experience. The “Request a Human” button helped route players to the experience they wanted, and satisfaction jumped up to be on-par with real agents. Players also rated us higher for timeliness. Success!
Learnings
Through the course of developing Blitzcrank Bot, we learned some valuable lessons. We’re still tuning the system, and I’m sure we’ll learn more, but here are some of our early takeaways:
Collect the data you need as soon as possible
Accurate classifiers need large amounts of data to train, and collecting data takes time. Half of our time training classifiers was spent correcting our own data, and some classifiers were not useful until agents properly tagged tickets. These types of mistakes can take months to correct and collect.
Re-training may not always be necessary
Re-training a live system can be tricky. Once you start answering player tickets, you begin affecting new training data. Our plan to address this was to build the classification server with the ability to continuously train, and figure out how to collect that data when our accuracy started to dip. We’re a year in and we still haven’t reached that point. In our case, player issues haven’t changed greatly over time.
Some messages still need a human touch
Blitzcrank Bot scores poorly in situations where we deny players what they’re asking for, such as “Why am I banned?” or “Can I have free RP?” In our tests, we found satisfaction was about 20% lower when Blitzcrank delivered the message instead of a live agent. Since satisfaction is our main metric for success, we’ve decided not to prioritize automation of these types of issues until we can find a way to deliver the same quality of service that players expect and deserve.
Where are we now?
Blitzcrank Bot currently routes or answers 20% of all Player Support tickets, doing the daily work of about 50 agents. With all those tickets handled, we can keep the size of our operation smaller and give agents the freedom to focus on the holistic player experience rather than just solving the same problems day in and day out.
We’d like to get Blitzcrank Bot closer to the 70% first-contact resolution rate that agents currently deliver. Beyond responding to more types of tickets, we can reach our goals by increasing the accuracy of our text classification. The more improvements we make, the more effective each classifier becomes!
Maybe the future holds deep learning for Blitzcrank Bot, or maybe it holds an entirely new way to help players all together. If you’d like to be a part of it, check out https://www.riotgames.com/careers.