
404 Tech Blog Not Found: Welcome to the Bug Blog
Hey folks! I’m Jane “Wilwariniel” Jeffers, QA Architect on League of Legends, and we interrupt your regularly scheduled Tech Blog to bring you the first installment of the Rito Bug Blog Series!
I’ve been working on League of Legends for quite a while now (seven years, to be exact), and let me tell you: I’ve seen some… stuff.
Why a Bug Blog Series?
So, why do Bug Blogs? Well, at Riot, we believe that a fundamental component of the development process is understanding that failures can and do happen. We make mistakes because we’re humans, and humans are far from perfect. And that’s okay! What’s important is to recognize failures for what they are, work to understand why they happened, learn from them, and make needed changes based on those learnings. That’s how we grow and that’s how we get better.
With this in mind, we want to share some of our more interesting bug challenges so that others can see how we work through them, both in the short-term and in the long-term. After all, in my experience, the true root cause of a defect oftentimes isn’t necessarily in the code or scripts itself, but somewhere in our tools or processes. Don’t worry, though, we’ll cover the nitty-gritty technical details, too. Our Bug Blogs will cover especially impactful bugs, ones that were difficult to triage and solve, and the ones from which we learned and grew the most.
We hope that by sharing these stories, we can help others facing similar struggles to totally avoid making the same mistakes that we did, or provide some ideas for solutions when things have gone sideways. And, I mean, c’mon, who doesn’t like to cringelaugh along with a really good bug story? I know I sure do.
So, for our very first post, let’s take a look at the one-two mega-punch that happened at one of the worst times possible. We learned a lot from this experience, and I hope that you can, too. This is the Bug Blog for League of Legends patch 4.18, aka the Worlds 2014 patch.
Context on Worlds Patches
Generally speaking, during a League of Legends World Championship, we actually have at least two patches to maintain. There’s the patch the pros play on during the tournament, which gets locked down earlier to ensure extra stability, and then the patch for the general playerbase, with more recent changes and content. Usually, this means the tournament is a patch or two behind what’s on live. The patch we’ll be talking about, the 4.18 patch, was what was live for our players for Worlds 2014.
That year, the World Championship grand finals were held in Seoul, South Korea, and a number of folks from the League dev team went there to experience it and to really interact with our playerbase in person. This way they could get a firsthand account of what players want, need, and get the most excited about.

Worlds 2014 Grand Finals in Seoul, South Korea. So many players!
I volunteered to stay behind and be the QA Lead for the Worlds patches with a small crew so that we could jump on any problems that might arise ASAP. We had put a lot of work into these patches to prepare for Worlds and for a chunk of the dev team being gone, so the expectation was that it would be a relatively quiet week.
Heh… quiet.
Round 1: Fight!
The first full week that patch 4.18 was live, we started to see the first reports of things being, well… a little wonky for a couple of champions. Messages began to pop up on the boards and social media about Kassadin and Nidalee in particular not behaving properly. Players said they weren’t doing damage when expected, or they were performing abilities in weird directions. This meant they were losing clutch fights. Not cool.
Our Network Operations Center technicians jumped on these reports and started paging out to the people on-call right away. While Production and Insights pulled the winrate numbers for the affected champions to figure out impact, the rest of us started working on reproducing the issue.
We narrowed in on the problem having to do with using certain abilities in a specific order. Performing a move block spell into a cone spell was key, which explained why Kassadin and Nidalee were experiencing the defect much more than other champions. Their respective kits practically depend on this combo.
When the bug happened, the champion would move to their new position with the move block, and then fire off the cone spell ability backwards, in the direction from which they came. It was confusing to the player, and felt pretty damn awful. With this knowledge, and the fact that the winrates for both champions were down 1-2% (a pretty hefty nerf from an unintended change), we made the call to disable first Nidalee and then Kassadin.
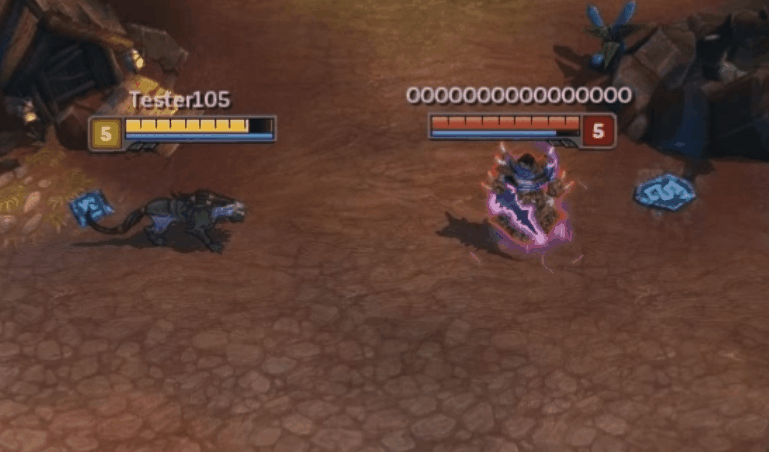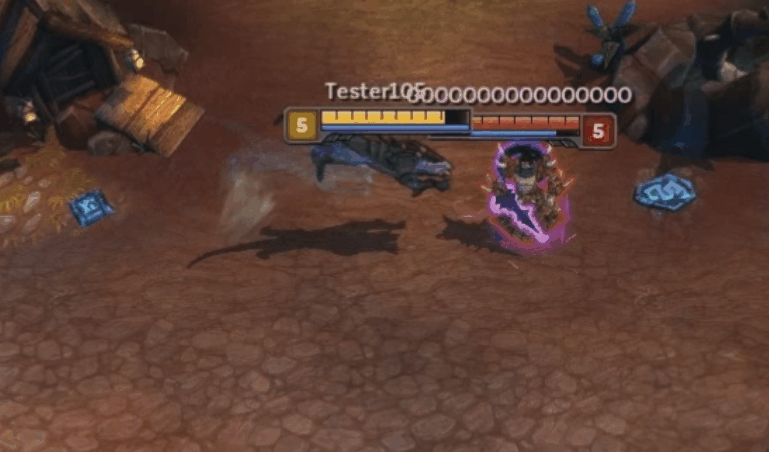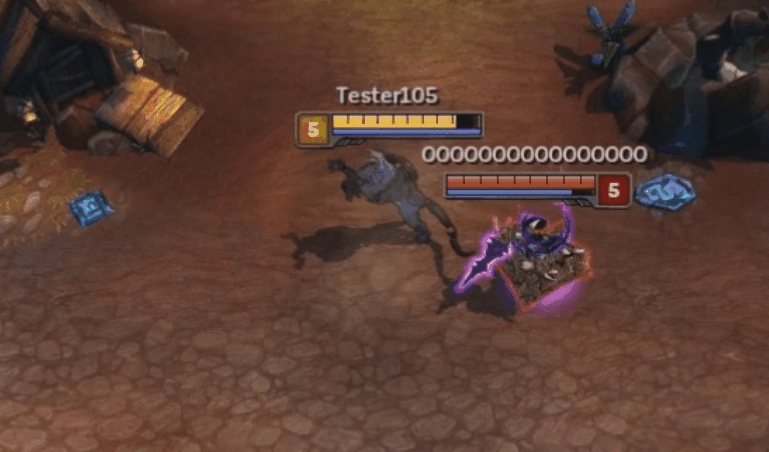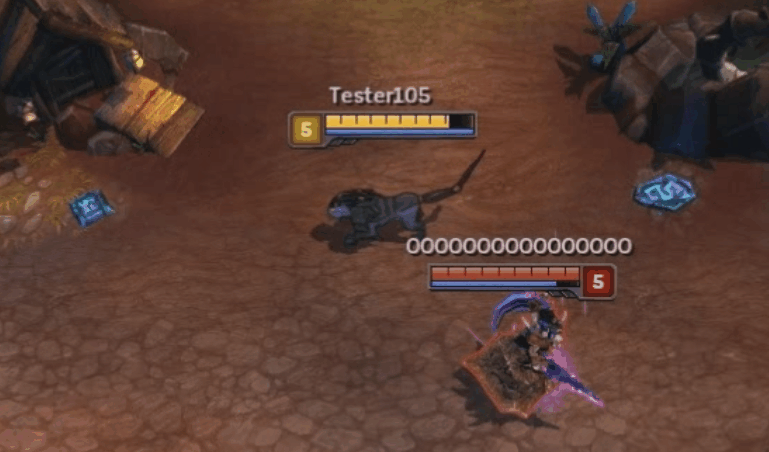
The bug in action. Nidalee performs her move block spell, Pounce (W), into her cone spell, Swipe (E). Watch how she turns when performing the Swipe.
But we were still missing something. The higher the skill level of the player, the more likely the defect was to occur. Did it have to do with timing? Positioning? Did an earlier order of events need to happen? As we continued to investigate, the list of potentially impacted champions kept growing. Although not every champion in the game has their own built-in movement abilities, every player has access to the summoner spell Flash, which blinks a character to a target location. Champions like Darius and Annie frequently use Flash and a cone spell to engage in fights, for example, and they were experiencing the issue too. We weren’t just looking at two impacted champions, but every champion with a cone spell ability.
Fortunately, we had a breakthrough in our testing and realized what the missing element was: it all had to do with spell queuing.

No, not that Q.
Under the Hood
In League, players can queue up abilities to more effectively carry out combos or pull off some sick escape plays. This is particularly effective when a player wants to prepare an ability to execute after a non-instantaneous ability completes. The queued ability is postponed until the first ability completes, and then the queued ability is cast. A move block spell is non-instantaneous because it takes the time to move the champion from Point A to point B. So one popular combo strategy is to queue up the next ability (like, say, a cone spell) so that it triggers as soon as the move block is complete.
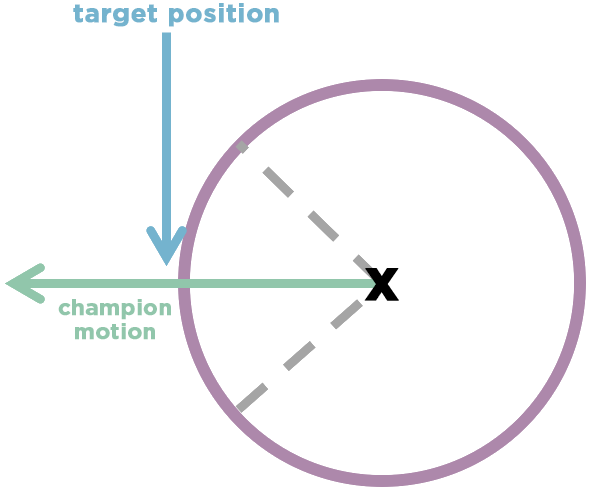
For cone spells in League, the ability originates from the player position. In the case of a move block into a cone spell, the game should activate the postponed spell after completing the move block, using the player position from that completed move block.
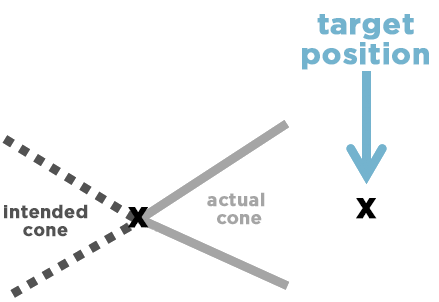
Instead, with this defect, an erroneous line of code was capping the target position of the cone spell at the time the ability was queued up, instead of storing the uncapped position and applying that cap when the postponed spell was brought back into play.
In other words, it would take the positioning from mid-move and try to cast the ability in that direction due to cast range restrictions. Hence Nidalee, Kassadin, and other champions effectively cast their abilities backwards.
The fix for this was relatively simple: remove the erroneous line of code. But the change impacted a script that was used for more than just cone spells. To make sure we didn’t accidentally break something else, we needed to perform thorough regression testing.
We ran a grep with Agent Ransack and found the script in a whopping 293 .ini files.
In other words, 293 different champion abilities, summoner spells, and items needed to be checked. It was going to be a long day of testing.
The Insidiousness of Tech Debt
It was during testing where tech debt really slowed us down. We encountered two big tech debt problems with this fix.
What’s in a Name?
The first big problem had to do with best practices. Today, League of Legends files follow specific naming conventions. This makes it easy for both humans and the game to identify what a thing is and what its purpose should be. AatroxE.lua, for instance, is the .lua file for Aatrox’s ability which is by default on the E hotkey. This makes it easy for anyone to find his E ability in the lua files, even if they aren’t familiar with the ability’s name.
Back in 2014, though, we had only just started really using standardized naming conventions. Out of the 293 .ini files we found in the grep, the names were all over the place. Some followed a pretty clear standard (GarenW.ini and GarenWpassive.ini), some at least tried to be descriptive (MissFortuneViciousStrikes.ini), and some… well, try identifying what ZhonyasRing.ini could be when it’s not an item in the game and you’re racing a ticking clock. Spoiler: only one person on the triage team remembered that it was an old item during League’s beta days. It was split into Zhonya’s Hourglass and Rabadon’s Deathcap, and surprise! Rabadon’s Deathcap kept the ZhonyasRing.ini file.
We made a spreadsheet of all 293 of these .ini files and went through it, identifying each ability, spell, or item based on our collective tribal game knowledge.
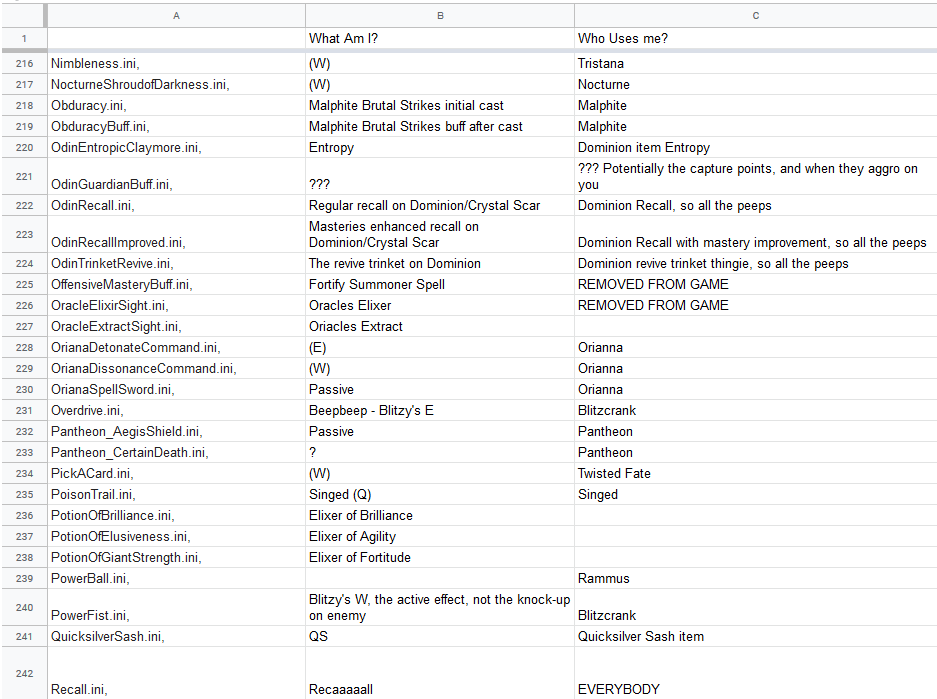
More identity than the files had ever felt before.
These all had to be manually tested, mind you. For something so feels-based in gameplay, automated testing was pretty much out of the question (and probably would have taken us longer to set up, anyway). Fortunately, we had some really good League players on the triage team to handle more nuanced test cases. And we also were able to utilize one of our QA outsource partner teams to help out with the heavy manual work. We ran quick checks in-house, and then sent it over to them for more robust confirmation and regression testing.
And yes, all of that regression testing was absolutely necessary. Six other champion abilities broke and designers had to edit their scripts individually to make the fix work.
Majestic Waves of VFX
The second tech debt problem we faced was related to an issue we identified during regression testing. Initially, we thought this was a knock-on (side-effect) bug due to how similar it appeared to the original cone spells bug. We pulled our hair out trying to investigate this new bug and figure out how it could have been introduced by the fix, when it turned out to be an old, old issue that had existed in League since… well, as long as anyone could remember.
Since the fix for this bug was the very first changelist he submitted to League of Legends, I’ve asked the crazy-talented Software Architect Brian “Riot Penrif” Bossé to explain the technical details of this juicy beast. Penrif?
Right! This was a fun one. The kind of fun that sticks with you for around 4 years. After we fixed the case of Nidalee constantly swatting at flies, clever people found that if you flashed and cast the cone spell exactly where you flashed to, strange things happened:
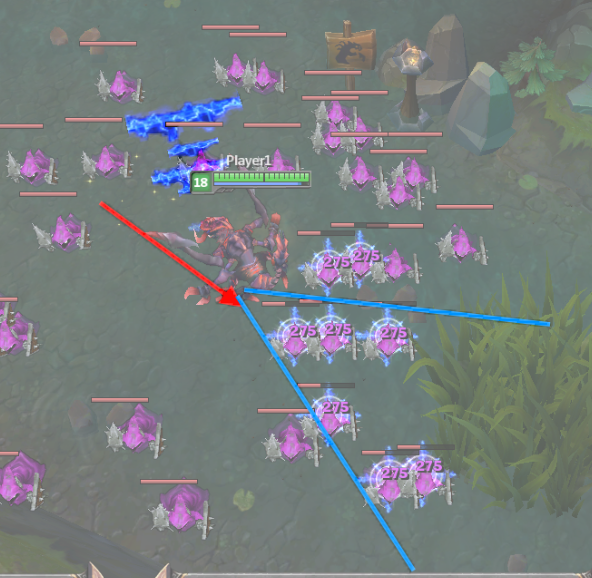
So here’s Cho’Gath after flashing in the direction of the red arrow. His subsequent cone-shaped scream hits where you’d expect, but the client shows majestic waves of VFX headed seemingly wherever they’d like to go. This is one of those cases where the same code exists on the client and the server. If your spell has no discernable direction because you cast it exactly on yourself, the game defaults to using whatever direction the character is facing. Except, clearly, the client thinks there is a real direction, and it’s rubbish. To know why, we need to go on a little journey together.
League uses 32-bit floating point numbers for positional information in the game. Fine and reasonable when computing locally, but constantly chucking around full resolution 32-bit values over the network really adds up, so we use some basic compression to squeeze them down a bit. Basically we just map the extent of the map into a 16-bit integer, and ka-bam, it’s half the size with no noticeable loss in fidelity.
Problem is, we don’t always compress positions like this when we communicate between server and client, we really just do it for unit positions. So, cast positions, to take a random non-specific example, still get the full 32-bit floating point treatment. When the cast position for Flash gets interpreted into a unit position and sent over the network, there's a difference in those positions due to the compression.
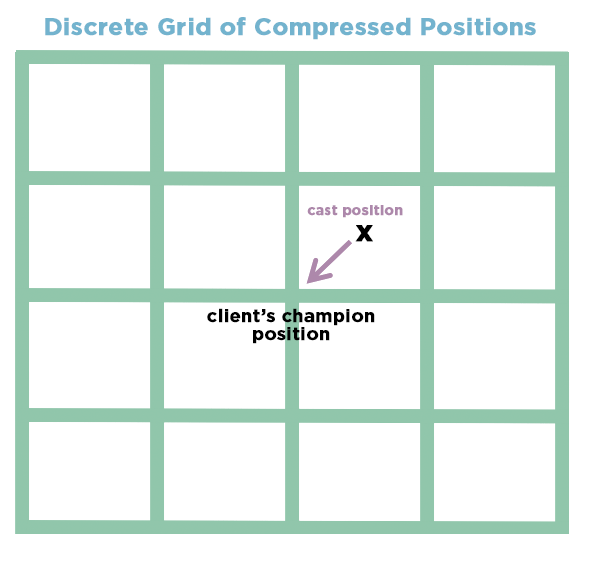
Now, when you cast a cone spell with exactly the same cast position, that compression error can now be interpreted by the client as a valid direction for the cone!
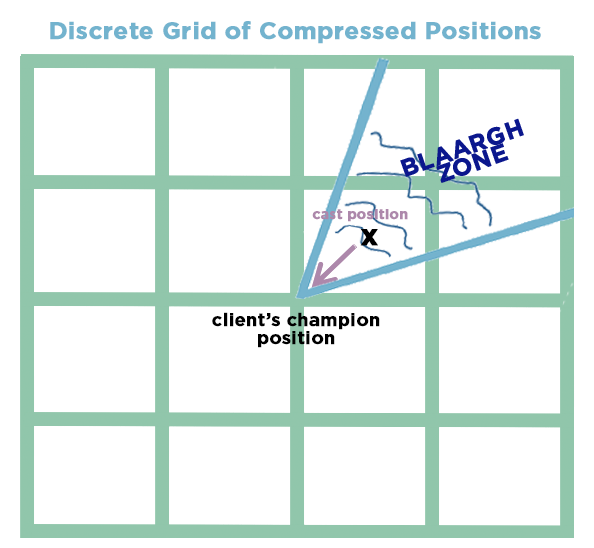
Easily remedied, thankfully, by changing the shared logic to fall back to the facing direction if the cast position and champ position would both compress to the same compressed position. That way, whatever we do to the network compression set-up, this bug will never come back. And indeed, that’s the first change I ever made to League of Legends. Back to you!
Thanks, Penrif! Wilwariniel here again. This bug’s similarity to the first issue - a cone spell not casting properly - threw us off-track for a while. Once we figured out that it was, in fact, an old, unique issue, we had to weigh whether or not it was worth packaging the fix in with the first bug. How likely was it to happen? Had it disrupted the current state of the game? How risky would it be to include it with the other needed fix?
Ultimately, we decided to defer the fix for that bug to the next patch, when we would have more time to test around it and get things right, instead of potentially introducing more risk while Worlds was going on. But we still spent that triage time and mindshare on the problem. Even smaller tech debt issues like these can really slow things down.
But Wait - There’s More!
I bet you thought that weird compression issue we dealt with was the second punch in the one-two mega-punch I mentioned earlier, huh?
NOPE! Patch 4.18 wasn’t quite finished with us, yet.
Actually, that patch was pretty bumpy. Here’s a picture of our amazing Senior Release Manager Donna “Feithen” Mason in front of the live triage issues board:

Notice the looong column of cards on the right? Those are all problems with the patch. Uh, sorry, Feithen. Anyway.
Enter the Exploit
That Saturday, less than 24 hours before the start of the grand finals, and while we were still in the middle of working on the cone spells bug, I got a call from the NOC to hop online. Rumors of an exploit - completely unrelated to the issues we were already dealing with - started to surface online. A post with a video showed a player using the champion Xerath to purposefully cause a server-side crash by casting one of his abilities off of the map.

I ain't afraid of no I am HIGHLY concerned about exploitable crashes.
Server-side crashes are ranked among the highest priority issues for League of Legends because they crash out all ten players from the game. We work pretty damn hard to keep them rare occurrences at best, so when they happen and are exploitable by bad actors? It’s an all-hands-on-deck situation.
Making Hard Choices
So there we were, still chest-deep wading around in the cone spells bug, with two champions already disabled and more being considered (which is a critical emergency in its own right). We had to make the hard choice to pivot a big chunk of our triage team’s resources to immediately tackle investigating the exploitable server-side crash. Although this effectively slowed us down with solving the cone spells bug, just the idea of an exploitable server-side crash was way too great a risk.
This turned out to be the right call. Although we immediately disabled Xerath, we found ourselves in a race against the bad actors who were rapidly discovering and sharing other champions that could also take advantage of the exploit. Lux soon surfaced as another problem. And then Vel’Koz. And Ziggs. So we further split our resources. Some Rioters were tasked with watching every nook and cranny of the internet possible (in multiple languages!) for any whiff of other problematic champions surfacing. The rest of us dug into the backend of the bug as fast as we possibly could. It was a scary time; a lot of champions have ranged abilities that could potentially reach out-of-bounds and be used for the exploit.
Between the cone spells bug and the server-side crash, we were rapidly approaching a reality where we would need to disable 25+ champions out of 121.
All at once. During Worlds. Our biggest event of the year.
It would have been an unprecedented catastrophe.

Really, everything is okay.
Under the Hood Part 2, Invisible Boogaloo
So, what was causing the server-side crash? If you said invisible minions, step up and claim your prize!
League of Legends uses invisible minions in a lot of different abilities to help with positioning. Like, a lot. Enough so that it’s kind of a running joke with our players given the headaches it has caused in the past (I’m looking at you, old Tryndamere spin-to-win exploit).
In this particular case, there was a location on the edge of the map (specifically, near the laser turret on the blue side fountain) where a player could position their champion and cast abilities off the map. If the ability in question could reach far enough and used invisible minions for positioning, and one of those invisible minions wound up completely off of the map, the game would crash because it would fail on NavGrid:GetHeightForValidPosition. In other words, it didn’t know where to place the minion.
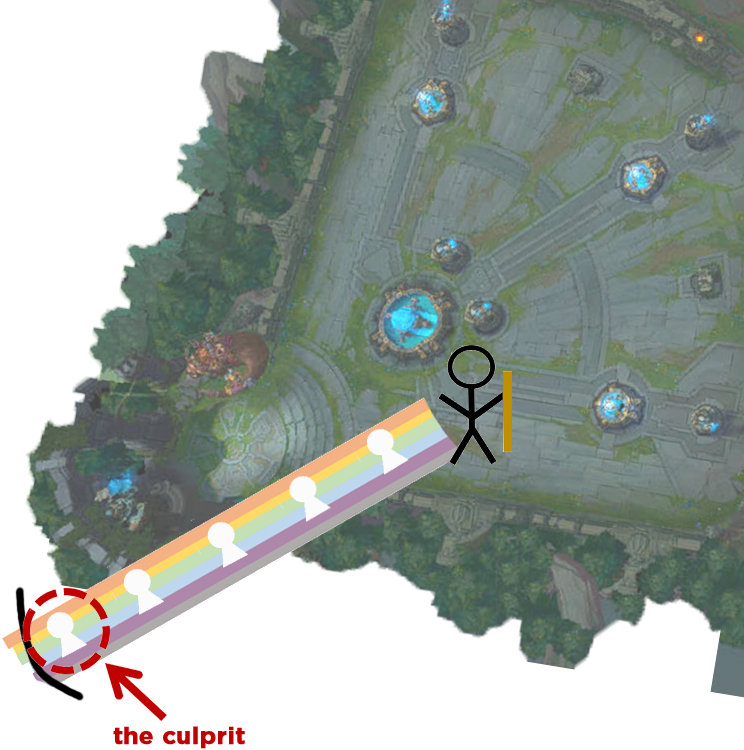
That’s some bad Lux.
Technically, any character could have caused this crash, but other unit types in the game adhere to terrain boundaries. We did try chucking some actual minions in that direction with Syndra, but they would hit the invisible wall.
It turned out that a line of sanity check code that protected from this kind of issue happening had been accidentally deleted. This fix was also relatively simple: put the sanity check back in.
All Together Now: Working with Multiple Live Issues
Our technical challenges didn’t end once we identified the causes for the issues, fixed them, and then tested around those fixes. Since these were Severity 1 emergency-level bugs, we needed to get the fixes out to players as soon as we possible could, as painlessly as we possibly could. Back in 2014, we didn’t have micropatch capabilities, so this meant pushing an actual hotfix.
Or, really, hotfixes. We needed to do both server and client redeploys to fully address the bugs. Server-side redeploys are relatively simple - push to the servers. Client-side redeploys, meanwhile, mean pushing a package to players to download. Depending on the size of the download, they can be a small ear flick or hellishly painful (and we try to avoid anything hellishly painful). With League being a 24/7 live service, always up (except for full patch downtimes), you have to be especially careful with these. What if a player exits during the middle of a match, reloads the client, and grabs the patch then? While frantically trying to get back into their match? When their team is counting on them, and we penalize players for leaving games prematurely?
And what about client-server mismatches? You have to figure out which redeploy is reliant on the other - if you push the server first, will the client bug out? Or vice versa? So these need to be done in the appropriate order, or the game could break further. We had to do a lot of testing around having only the client changes, having only the server changes, and having both.
In this instance, because the knock-on bugs from the cone spells issue were fixed via script changes, we had to push the client first, and then the server. This way, we could keep Nidalee and Kassadin disabled (along with the growing list of server-crash-happy champions) without having to disable the other champions impacted by the fix.
We had to roll the redeploys out slowly to ensure safety for the players, which was maddening, given the urgent nature of the bugs. But it’s way better to measure twice and cut once. And so, watching like hawks, we finally pushed the fix to our players, one region at a time.
What We Learned, How We’ve Grown

A perfect storm
Although we’d like to think that such a perfect storm of events is just a one-off, the truth of the matter is that crazy cascading failures happen way more frequently than we’d ever like to think. That’s why it’s so important to prepare for worst case scenarios in case they might happen. And when they do happen, we need to learn as much as we can from them, and make changes to ensure they’re not repeated.
So, what did we learn from this wild ride, and how did we change for the better?
Keep Calm and Take One Step at a Time

Despite the craziness of dealing with these bugs coming in on top of each other, with part of the dev team in Korea, plus the added pressure of the World Championship, we managed to really keep our heads about us. We just did not have the time or energy to panic.
Staying Cool
Instead, we methodically went about working on the issues, one step at a time. By staying cool, we were able to communicate effectively and keep our priorities clear. Some of the procedures that we adopted during this patch became the standard for handling similar emergency triages going forward.
With the server-side crash, for instance, once we sorted out that it was an issue with invisible minions, we knew the full list of champions right away. Talk about an ohcrap! moment. Instead of disabling them all in one shot, however, we took a watch and wait approach, and would only disable a champion when the bad actors found them. This was crucial in maintaining the overall health of the full League of Legends experience, and it’s an option we consider when we encounter similar issues today.
Looking Back and Moving Forward

After we rolled the fixes out - and had time to recover - we not only had a retro for the bugs themselves, but we also retroed the whole experience. This was critical for making sure we’d be better at dealing with future crises. We identified every pain point we encountered. That really helped us to improve on what good looks like for addressing live issues from initial discovery to the solution reaching players.
The pain from having to do the two redeploys in such a pressure-cooker situation was also one of the first sparking points for talking about the feasibility of micropatching on League of Legends. We wouldn’t have the capability for quite a while after - it took a lot of work! But starting the conversation way back then allowed us to get to where we are today, and avoid causing a lot of player pain when trying to fix problems.
Dealing with Tech Debt

Combatting tech debt can sometimes feel like an endless battle. Having multiple tech debt problems slow us down during this crisis really helped emphasize the need for fighting that battle instead of just giving up on it.
Improving Naming Conventions
We had to work with the hodgepodge list of 293 differently named .ini files for the cone spells bug, and had to rely on tribal knowledge to be able to properly test the fix. This was a great reminder for why we were starting to use standardized naming conventions. After the 4.18 patch, teams committed more firmly to the naming conventions for new files, and a lot of old files were updated. No more ZhonyasRing.ini! Work like this helps prevent future defects from ever happening, and it makes it much easier for devs to do their jobs.
Prioritizing Bugs
The issue we found during testing for the cone spells bug fix was fixed in the very next patch, so that little piece of tech debt was also kicked to the curb. Not all tech debt clean-up needs to be a giant overhaul or major refactor. By making small quality of life improvements like this to the game as we stumble over them when we can, instead of letting them linger, we are able to increase the overall quality bar of League of Legends over time. Back then, players were just… living with this bug in the system. Today? A bug like that would stop professional matches.
Handling Tech Debt with a Realistic Mindset

How I usually handle my problems
While I am all for axe-murdering in the face cleaning up tech debt whenever we see it, sometimes that just may not be possible. Too much may be built on top of it or dependent on it. While that’s not great, it can happen, and what’s important is to acknowledge that you have tech debt and to figure out plans for working on it. As problematic as they are, invisible minions are an important part of how League works. Removing them completely from the game just isn’t a feasible solution. Instead, teams have worked hard to transform them from the semi-hack they used to be into a more robust, viable system. (For more insight into how we prioritize fixing tech debt, check out this previous article by Bill Clark.)
We were also able to give a heads up about the server-side crash to the Summoner’s Rift Update team, who were hard at work on the new version of the map. By sharing the lessons we learned with that bug, that gave the team the opportunity to check if they needed to make any changes to prevent any similar future mishaps. And that’s the best way to handle bugs and tech debt: to not have to deal with them in the first place!
Fix Verified, Closing Ticket
So, that’s it for the first Bug Blog. Whew! I’m going to go ahead and close it out. Thanks for reliving this journey with us.
We plan to put out more Bug Blogs in the future. In the meantime, we’d love to read about some of your best bug moments. Feel free to share them in the comments below.
And remember:

Wilwariniel signing off.